
Orchestration
Introduction
Comme nous l’avons vu précédemment, nous avons un ensemble de serveurs susceptibles d’héberger nos applications et il nous est devenu possible de choisir le ou les serveurs sur lesquels les déployer ou les redéployer.
Néanmoins, il nous faut toujours choisir le serveur physique disponible sur lequel déployer eni-todo et vérifier qu’il a des ressources suffisantes. Il faut vérifier l’espace disque, les ports à configurer, la mise à jour du DNS interne, etc.
Si nous avons une opération de maintenance à faire, il faut basculer la charge, c’est-à-dire les applications existantes, depuis le serveur à mettre à jour vers un ou plusieurs serveurs qui resteront disponibles et qui pourront héberger nos applications le temps de l’opération de maintenance, le tout bien entendu sans arrêter de fournir le service.
Ce parcours des serveurs disponibles pour choisir le candidat sur lequel déployer notre application est fait manuellement ou semi-manuellement avec des commandes Ansible vers les serveurs candidats.
L’automatisation de ce type de tâche est le rôle d’un orchestrateur.
Nous allons voir dans ce chapitre ce qu’est un orchestrateur, comment il fonctionne, et nous initier au plus connu et puissant d’entre eux : Kubernetes.
Abstractions d’orchestration
Le principe d’un orchestrateur de système d’information est de créer des abstractions permettant de manipuler, de distribuer et de rendre des services informatiques, à travers les réseaux informatiques, très souvent via HTTP, mais pas exclusivement. On parle souvent de la complexité de maintenir une machine à états de façon distribuée.
Une des idées derrière l’utilisation d’un orchestrateur est la possibilité d’avoir une utilisation optimale des ressources disponibles. L’objectif étant, à travers diverses contraintes, de permettre un mécanisme de décision répondant de manière optimale au contexte. Ces éléments seront détaillés dans la section Scheduler.
Il y a deux grandes catégories d’outils d’orchestration :
-
les outils à accès distant (tel Ansible), qui accèdent aux serveurs distants pour y effectuer des opérations ciblées (playbooks) ;
-
les outils (tel Puppet) utilisant un agent local qui assure la « cohérence » du serveur face à des états définis.
L’architecture physique, technique et logicielle pouvant être variée (PowerPC, AMD et autres, type de processeur - x86, ARM, etc. -, espace disque, type de disque dur, etc.), il est néanmoins nécessaire...
Automatisation ou orchestration ?
La distinction entre une automatisation des processus d’installation, de mise à jour, de répartition, etc., et un système d’orchestration réside principalement dans la volonté ou la capacité de formaliser les règles de gestion permettant la prise de décision dans l’affectation des ressources.
L’une des difficultés en informatique d’entreprise est la prédictibilité des décisions. Il est donc souvent plus facile d’avoir des processus automatisés, mais dont la prise de décision reste à la main des opérateurs (comme c’est le cas dans le chapitre Exposition et répartition). Cette méthode de fonctionnement tend à maintenir un sentiment de maîtrise. C’est un sentiment qu’il ne faut pas négliger, car la confiance que l’on a dans ses outils est certainement le premier facteur de leur utilisabilité. Cependant, l’ordinateur a des capacités de traitement bien supérieures et il arrive que les limites humaines entraînent une obligation de passer à l’orchestration. La limite est vague, dépend de l’expérience et des niveaux d’harmonisation entre les applications, néanmoins le seuil reste présent.
Force
La force d’un orchestrateur est bien entendu dans...
Bataille des orchestrateurs
De 2011 à 2014, Docker devient de plus en plus incontournable comme outil d’encapsulation d’applications à destination du cloud, avec notamment des solutions comme Amazon ECS. Les offres d’hébergement Docker commencent à fleurir chez Microsoft et IBM.
De 2015 à 2018, c’est le début de la guerre des orchestrateurs. Il y a de très nombreuses solutions d’orchestration rivalisant de fonctionnalités. Docker étant facilement manipulable par ses API, la mise en place d’un orchestrateur devient une nécessité. Rappelons que Docker a précisément été conçu dans l’objectif de faciliter le déploiement des applications et l’hyperdensification. Parmi les grands candidats pour l’orchestration, il y a essentiellement :
-
CoreOS, qui est à l’origine de etcd, de la release Tectonic et du moteur de container rkt, créateur de la release immuable CoreOS, puis des opérateurs (operators) au sein de Kubernetes.
-
Rancher avec Cattle, qui est notamment à l’origine de la démocratisation de l’expression métaphorique « think cattle not pets » (penser que le bétail n’est pas les animaux de compagnie) pour définir le nouveau paradigme des relations entre les opérateurs et leurs serveurs. Cet orchestrateur...
Mécanismes des environnements distribués
1. Consensus
Dans un système distribué, le maintien de la cohérence de l’état du système est un processus complexe qui doit prendre en compte, d’une part, les latences potentielles d’une partie des membres et, d’autre part, les potentiels problèmes de défaillance. Historiquement, les outils de hash (MD5, shasum) et de parité sont faits pour vérifier la non-corruption des fichiers dans un réseau reconnu non fiable (TCP/IP).
On appelle consensus le mécanisme qui permet de garantir cette cohérence. Il existe plusieurs mécanismes techniques pour maintenir le consensus. Nous allons présenter Paxos et Raft.
2. Paxos
Paxos est un mécanisme de consensus dans un système distribué, défini en 1989 et affiné en 1998 (The Part-Time Parliament - Leslie Lamport. This article appeared in ACM Transactions on Computer Systems 16, 2 (may 1998), 133-169. Minor corrections were made on 29 August 2000).
Paxos demande plusieurs rôles :
-
Le Proposer crée le message induit par une demande d’écriture d’un client du système.
-
Plusieurs Acceptors constituent ensemble un ou plusieurs quorum. S’il y a plusieurs quorums, au moins un Acceptor par quorum doit appartenir à plusieurs quorums.
-
Les Learners sont les serveurs en charge de l’écriture...
Scheduler
Le rôle du scheduler, ou ordonnanceur, est de trouver parmi les ressources disponibles qu’il possède la ressource lui permettant d’instancier la charge de calcul. Il est pour cela nécessaire de formaliser un processus de décision au sein de Kubernetes. Ce processus au sein de Kubernetes est appelé policy.
Au sein d’un cluster Kubernetes, le scheduler recherche sur quel nœud il peut déployer ses pods (ensemble atomique de 1 à n containers). Il procède à une action de filtrage et à une action de calcul de poids afin de choisir le bon nœud. Pour cela, il utilise des prédicats et des critères de priorisation. Il filtre l’ensemble des nœuds à sa disposition selon lesdits prédicats (par exemple : si un nœud a suffisamment de ressources). Puis il attribue une note aux nœuds candidats selon les critères de priorisation et leurs poids pour choisir le meilleur candidat.
Voici un exemple de fichier policy :
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : " PodFitsHostPorts"},
{"name" : " PodFitsResources"},
{"name" :...Premiers pas avec Kubernetes
Un outil comme Kubernetes est au départ une abstraction pour permettre de faire tourner des containers indépendamment de l’endroit physique sur lequel il se trouve.
C’est un outil initialement créé par Google et proposé en open source. Il serait inspiré de Borg (une référence à la série Star Trek TNG), l’orchestrateur interne de Google.
1. Architecture
Kubernetes est donc initialement un orchestrateur de containers. Dans Kubernetes, tous les serveurs sont des nœuds (nodes).
Les contrôleurs (control-plane nodes) sont chargés de faire fonctionner les composants principaux :
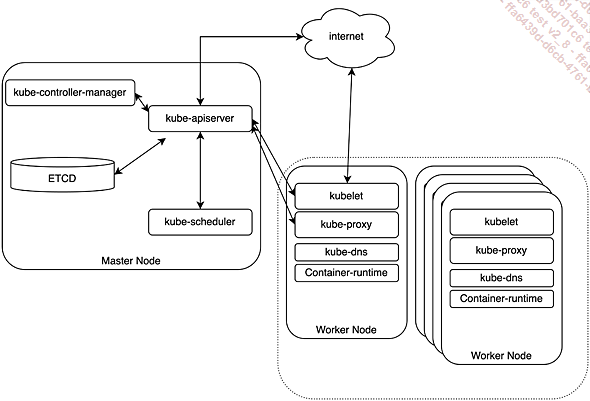
Figure 4 : Architecture de Kubernetes
-
Le kube-apiserver est le port de communication entre les différents composants. Il a le rôle d’intermédiaire entre, d’un côté, le kube-controller, le kube-scheduler, l’etcd, et de l’autre, le kubelet et le kube-proxy, ces deux derniers étant situés sur les nœuds workers en charge des échanges avec des nœuds.
-
Le kube-controller est le « garant » des états du cluster. Il vérifie et maintient à travers une boucle infinie la cohérence des objets du cluster.
-
Le kube-scheduler est chargé d’affecter les pods aux nœuds, conformément aux contraintes et politiques d’ordonnancement, l’assignation des pods sur les nœuds.
-
La base de données (simple ou cluster) etcd est la base clé-valeur qui contient l’état du cluster.
Les nœuds de travail (workers), qu’on appelle généralement les nodes, sont en charge d’instancier les pods suivant les demandes du contrôleur.
-
La kubelet instancie les pods par le biais de son moteur de container et sur la base des descriptions qui lui sont transmises par le « contrôleur » (control-plane). Il instancie également les pods « statiques » définis localement dans son dossier prévu à cet effet (/etc/kubernetes/manifest).
-
Le kube-proxy est le composant en charge de la connectivité des nœuds avec l’API et de la mise en place des éléments de routage interne et du port-mapping.
-
Le pod (que l’on peut traduire par « capsule »)...
Initiation à Kubernetes
1. kubectl
Kubectl, l’outil client de Kubernetes, est un outil en ligne de commande pour gérer l’interaction avec notre cluster. Bien qu’il nous semble préférable d’avoir le client sur notre environnement, il est possible d’utiliser ce client depuis notre Minikube avec la commande minikube kubectl --, sans avoir à installer cette dernière.
Cette fonctionnalité est également assez pratique lorsque nous devons utiliser des versions différentes du client.
$ minikube kubectl -- get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 65m v1.30.0 Le client kubectl effectue les appels à l’API de Kubernetes à notre place, de manière bien plus simple pour nous. Tout ce que kubectl fait peut être effectué avec des appels directs (par curl, wget ou de manière programmatique) à l’API.
2. Appels à l’API
Kubernetes présente une API REST qui permet aux utilisateurs d’interagir avec le cluster. Cette API permet de lire, de créer ou de modifier les object resources du cluster : toutes les ressources (les objets) que peut manipuler Kubernetes. Vous pouvez obtenir la liste des types d’object resources du cluster avec la commande kubectl api-resources :
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap ...

![Linux Préparation à la certification LPIC-1 (examens LPI 101 et LPI 102) - [7e édition]](http://www.editions-eni.fr/livre/linux-preparation-a-la-certification-lpic-1-examens-lpi-101-et-lpi-102-7e-edition-9782409043109_M.webp)

