
Spring et le NoSQL
Introduction
Historiquement, les grandes entreprises du Web, à cause d’un très grand nombre d’utilisateurs ou de très gros volumes de données, ont eu besoin, à un moment donné, de bases de données de plus en plus vastes. À cette époque, la mise à l’échelle se faisait généralement par l’augmentation de la capacité de la machine hébergeant la base. En effet, dans une base de données relationnelle SQL, les relations sont portées par des clés primaires qui sont référencées par des clés secondaires avec l’aide d’index. Les requêtes sur les données se font par jointures et au bout d’un moment s’il y a trop de jointures, cela devient très vite complexe.
La complexité relative aux jointures est un argument que l’on rencontre souvent. Il faut savoir à ce sujet qu’il existe des applications composées de plusieurs milliers de tables utilisant les jointures qui fonctionnent très bien sous Oracle. Oracle peut gérer plusieurs milliards de métadonnées (Dictionary-managed database objects : https://docs.oracle.com/en/database/oracle/oracle-database/19/refrn/logical-database-limits.html#GUID-685230CF-63F5-4C5A-B8B0-037C566BDA76). Il y a un volume de données limité et une croissance exponentielle...
Les modèles de données
Il existe quatre modèles principaux :
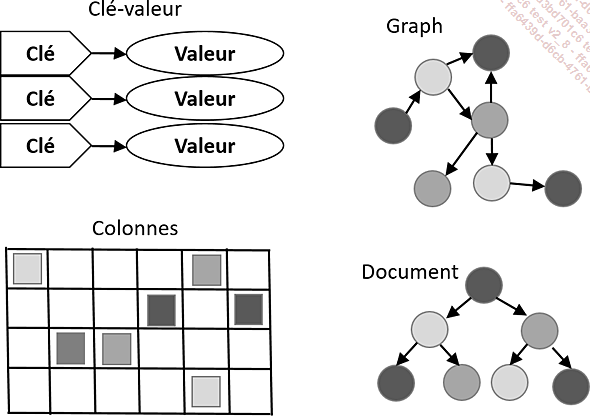
1. Modèle Clé-valeur
Il faut voir ces bases de données comme une grande hashmap stockée sur le disque avec la possibilité de mettre des métadatas pour créer des index. Il y a trois grandes bases de données de ce type : Projet Voldemort qui est un système de fichiers distribués proposé par LinkedIn et qui consiste en une implémentation libre du système Dynamo d’Amazon, Riak qui est inspiré de Dynamo et Redis REmote DIctionary Server (Serveur de dictionnaire distant).
2. Modèle Documents
Dans ce modèle de bases, n’importe quel document a une structure complexe persistée (enregistrée) en une fois. La base est orientée agrégat. Nous devons regrouper les choses qui font naturellement partie d’un agrégat pour les persister en base. Il y a une tendance à faire un schéma implicite. Les données représentent généralement des entités concrètes. Il faut savoir que dans un système clusterisé, si un agrégat pointe vers un autre agrégat, l’ensemble peut être sur plusieurs nœuds.
Dans une base agrégat, l’organisation de l’agrégat est centrée et optimisée sur un point de vue d’observation...
Principes des bases de données
Consistance des données
La consistance vise à gérer les modifications concurrentes. Dans une base de données, la consistance est souvent assurée par la notion de transaction. Si on découpe un ensemble d’informations en plusieurs pseudo-tables ou documents, on veut que, si une des modifications échoue, toutes les modifications soient annulées. On veut une mise à jour atomique. La transaction « unitaire » est devenue, après de longues années, acceptable et acceptée.
Historiquement, dans les applications qui font intervenir plusieurs systèmes répartis ou séparés, la notion de transaction était centrale et nous avions des transactions à plusieurs phases. Spring contient à ce titre une gestion des transactions très complète qui permet de gérer une transaction sur une suite d’appels. Aujourd’hui, avec les applications Stateless, les transactions sont beaucoup plus simples : une transaction, souvent implicite, par appel. La transaction « unitaire » est devenue, après de longues années, acceptable et acceptée.
Pour les bases orientées documents, il faut garder la transaction au niveau de l’agrégat. La mise à jour d’un agrégat peut être atomique, mais...
Pourquoi et quand utiliser une base NoSQL
La base NoSQL trouve sa place là où il y a naturellement des agrégats et là où il y a de grands volumes de données. Pour les grandes bases de données très volumineuses, on a recours au NoSQL, car il n’y a pas de base SQL suffisamment grande.
On peut se baser sur les tableaux suivants pour se faire une idée des bases de données et de leurs usages :
Requêtes simples et rapides :
|
Volume |
CAP |
Base |
Applications |
|
Faible |
En RAM |
Redis |
Cache |
|
|
En RAM |
Memcache |
|
|
Illimité |
AP |
Cassandra |
Panier |
|
|
Riak |
boutique |
|
|
Voldemort |
|
||
|
Aerospike |
|
||
|
|
CP |
Hbase |
Historique |
|
|
MongoDB |
des ventes |
|
|
CouchBase |
|
||
|
DynamoDB |
|
||
Requêtes complexes :
|
Volume |
Type |
Base |
Applications |
|
Disque Dur |
ACID |
RDBMS |
Traitement |
|
|
Neo4j |
transactionnel |
|
|
RavenDB |
en ligne |
||
|
MarkLogic |
|
||
|
|
Disponibilité |
CouchDB |
Site web |
|
|
|
MongoDB |
|
|
|
|
SimpleDB |
|
|
Illimité |
Req sur |
MongoDB |
Réseau social |
|
|
mesure |
RethinkDB |
|
|
HBase |
|
||
|
Accumulo |
|
||
|
ElasticSearch |
|
||
|
Solr |
|
||
|
|
Req |
Hadoop |
Big data |
|
|
Analytique |
Spark |
|
|
Parallel DWH |
|
||
|
Cassandra |
|
||
|
HBase |
|
||
|
Riak |
|
||
|
MongoDB |
|
||
Nous savons que le succès des bases SQL vient aussi de leur aspect intégrateur. Une base de données SQL est idéale quand il faut partager des données qui sont accédées par plusieurs applications ou par plusieurs nœuds d’une application clusterisée. La base SQL est très bien pour partager des états entre applications monolithiques. À...
Problèmes liés à l’utilisation des bases NoSQL
L’utilisation des bases de données NoSQL induit de nouvelles décisions, des changements d’organisation. Les DBA traditionnels pour les grandes bases de données SQL comme Oracle, Sybase ou autres se retrouvent face à la relative immaturité des solutions NoSQL. Le manque d’outils, d’expérience, et de savoir dans les équipes ne rassure pas.
Dans les faits, les outils existent et le savoir-faire aussi mais ils sont souvent jugés onéreux et disproportionnés à l’échelle d’une équipe Pizza Team.
Les décisions sont prises dans les équipes de développement qui doivent alors gérer elles-mêmes le suivi et les inconsistances en production. Dans les projets stratégiques, on a souvent recours au NoSQL pour avoir des TTM (Time To Market ou temps de mise à disposition sur le marché) très courts. Nous pouvons profiter de la facilité de développement et gérer beaucoup de données. La tendance actuelle pour les nouveaux projets est de n’utiliser les bases SQL que sur les projets non vitaux et non stratégiques à rythme de releasing lent.
Ces bases de données NoSQL peuvent être persistées sur disques ou être juste en mémoire dans...
Limitations des bases de données NoSQL
Les requêtes SQL permettent de pratiquement tout faire dans une base bien conçue. Le SQL est connu et bénéficie d’outils comme la définition des six formes normales.
En NoSQL, il faut s’occuper soi-même des relations entre les documents et bien répartir les données sur les différents nœuds d’un cluster (sharding).
De plus, au niveau du stockage physique des données, chaque implémentation diffère. Au niveau de l’exploitation, il faut faire du spécifique pour chaque fournisseur de base de données NoSQL. Les API diffèrent également. Avec le NoSQL, nous sommes plus dans le domaine de l’artisanat par rapport au domaine bien industrialisé du monde SQL traditionnel.
Spring et le NoSQL
Comme pour les autres bases SQL, Spring rend plus simple l’utilisation des bases NoSQL à travers la mise à disposition d’API.
Il existe une multitude de bases NoSQL. Voici les plus populaires :
|
Base |
Caractéristiques |
|
MongoDB |
Base de données de documents open source. |
|
CouchDB |
Base de données qui utilise JSON pour les documents, JavaScript pour les requêtes MapReduce et l’API standard HTTP. |
|
GemFire |
Plate-forme de gestion de données distribuée offrant une évolutivité dynamique, de hautes performances et une persistance de type base de données. |
|
Redis |
Serveur de structure de données dans lequel les clés peuvent contenir des chaînes, des hachages, des listes, des ensembles et des ensembles triés. |
|
Cassandra |
Base de données offrant extensibilité et haute disponibilité sans compromettre les performances. |
|
memcached |
Système open source à haute performance, à mémoire distribuée et à mise en cache d’objets. |
|
Hazelcast |
Plate-forme de distribution de données open source hautement évolutive. |
|
HBase |
Base de données Hadoop, un grand entrepôt de données distribué et évolutif. |
|
Mnesia |
Système de gestion de base de données distribuée qui présente des propriétés logicielles en temps réel.... |
Cache de données
Les caches répondent à la problématique de garder des données en mémoire pour les rendre disponibles sans rechargement. Les caches de données sont proches des bases NoSQL clé/valeur. Spring permet assez simplement d’avoir un cache simple et un cache plus élaboré basé sur GenFire.
"Il y a seulement deux problèmes compliqués en informatique : nommer les choses, et l’invalidation de cache". Citation célèbre de Phil Karlton.
1. Cache simple
Nous pouvons utiliser un ResourceBundle pour charger une ressource pour garder en mémoire des données fixes, mais cela ne suffit pas toujours. Pour simplifier, nous dirons dans la suite de ce chapitre que nous "cachons" des données quand nous les rendons disponibles à travers l’utilisation d’un cache de données.
Spring offre un support simple pour cacher les beans managés par Spring via l’utilisation de l’annotation @Cacheable.
Cette annotation indique que le résultat de l’appel d’une méthode (ou de toutes les méthodes d’une classe) peut être mis en cache. À chaque fois qu’une méthode est invoquée, on vérifie si on a en mémoire le résultat d’un appel précédent pour les arguments donnés. Nous pouvons...
Cacher des données avec GemFire
GemFire est la data grid (grille de données) en mémoire basée sur Apache Geode. Elle permet de stabiliser nos services de données à la demande pour répondre aux exigences de performance des applications temps réel. Elle accompagne la montée en charge cohérente et homogène sur plusieurs data centers, offre des données temps réel à des millions d’utilisateurs, a une architecture orientée événements, et elle est idéale pour les microservices. Ses caractéristiques principales sont sa latence faible et prévisible, sa scalabilité et son élasticité, la notification d’événements en temps réel, la haute disponibilité et la continuité de l’activité. Elle est durable et fonctionne sur le cloud.
Pour l’exemple qui suit, nous utilisons la configuration embarquée (Embedded) qui est la plus simple pour faire un cache distribué haute disponibilité.
Exemple d’utilisation
Classe Application :
@ClientCacheApplication(name = "CachingGemFireApplication",
logLevel = "error")
@EnableGemfireCaching
@SuppressWarnings("unused")
public class Application {
private static final Logger logger= LoggerFactory.getLogger
(Application.class);...GemFire en tant que base de données NoSQL
La classe ApplicationEnableGemfireRepositories :
@ClientCacheApplication(name = "DataGemFireApplication", logLevel =
"error")
@EnableGemfireRepositories
public class ApplicationEnableGemfireRepositories {
public static void main(String[] args) throws IOException {
SpringApplication.run(ApplicationEnableGemfireRepositories.class,
args);
}
@Bean("Department")
public ClientRegionFactoryBean<String, Department>
departmentRegion(GemFireCache gemfireCache) {
ClientRegionFactoryBean<String, Department> departmentRegion =
new ClientRegionFactoryBean<>();
departmentRegion.setCache(gemfireCache);
departmentRegion.setClose(false);
departmentRegion.setShortcut(ClientRegionShortcut.LOCAL);
return departmentRegion;
}
@Bean
ApplicationRunner run(DepartmentRepository departmentRepository) {
return args -> {
Department ain = new Department("01","AIN");...Redis en autonome
1. Utilisation de Redis pour le cache de données
La classe Departement reste la même que dans le premier exemple.
Le lanceur :
@SpringBootApplication
@EnableCaching
public class Ex3CacheRedis implements CommandLineRunner {
private static final Logger LOGGER =
LoggerFactory.getLogger(Ex3CacheRedis.class);
public static void main(String[] args) {
SpringApplication.run(Ex3CacheRedis.class, args);
}
@Autowired
private DepartementRepository departementRepository;
@Override
public void run(String... args) throws Exception {
departementRepository.cacheEvict();
LOGGER.info("27->{}", departementRepository.getByCode("27"));
LOGGER.info("44->{}", departementRepository.getByCode("44"));
LOGGER.info("51->{}", departementRepository.getByCode("51"));
LOGGER.info("27->{}", departementRepository.getByCode("27"));
LOGGER.info("44->{}", departementRepository.getByCode("44"));
LOGGER.info("51->{}", departementRepository.getByCode("51"));
departementRepository.patch("27","__EURE__");
LOGGER.info("27->{}", departementRepository.getByCode("27"));
}
} Dans le lanceur, nous avons l’appel à la méthode departementRepository.cacheEvict() pour vider le cache. Nous utilisons le cache, puis nous patchons une des valeurs :...
MongoDB
MongoDB est un système de base de données orienté documents, sous licence AGPL, avec les données réparties sur plusieurs serveurs. Il n’y a pas de schéma de données. Les pilotes sont sous Apache et la documentation sous licence Creative Common.
Créée en 2007, il a fallu attendre la version 1.4 de 2010 pour pouvoir l’utiliser en production. Les données sont au format BSON (JSON binaire), enregistrées sous forme de collections d’objets JSON à niveaux multiples. Ces enregistrements dans la base peuvent être polymorphiques avec comme contrainte de partager un champ-clé principal nommé "id". Cet index unique permet d’identifier un document (enregistrement dans la base). Les requêtes se font en JavaScript.
La base de données dispose d’un interpréteur de commande en mode texte directement accessible via le binaire Mongo. Des outils graphiques libres existent, comme par exemple nosqlbooster4mongo.
1. MongoDB avec Spring Boot
Nous utilisons la version Community Edition de MongoDB pour nos tests.
Pour les tests unitaires et les tests d’intégrations, il est aussi possible, d’utiliser les tests containers (https://www.testcontainers.org/modules/databases/mongodb/).
Pour cet exemple, nous mettons dans le pom.xml le starter spring-boot-starter-data-mongodb. Ceci a pour effet d’inclure les dépendances vers MongoDB.
Il n’y a pas de différences notables avec un programme classique utilisant du SQL.
La classe du lanceur :
@SpringBootApplication
public class Ex1MongoDB implements CommandLineRunner {
private static final Logger LOGGER = LoggerFactory.getLogger(Ex1MongoDB.class);
@Autowired
private CapitaleRepository repository;
public static void main(String[] args) {
SpringApplication.run(Ex1MongoDB.class, args);
}
@Override
public void run(String... args) throws Exception {
repository.deleteAll();
repository.save(new Capitale("Afghanistan", "Kaboul", "Asie"));
repository.save(new Capitale("Afrique du Sud"...Points clés
-
Les bases NoSQL remplacent les bases SQL pour les projets qui demandent un TTM performant.
-
Les bases NoSQL sont adaptées pour les microservices ou le Big Data.
-
Les bases NoSQL sont généralement gérées en production par les équipes de développement.
-
Un bon sharding qui correspond à la répartition des données entre serveurs est critique.