
Traitements et architectures distribués
Introduction
Nous avons abordé les problématiques de stockage distribué dans le chapitre précédent ; dans celui-ci, nous allons couvrir les traitements de haut niveau et les architectures typiques, toujours dans le cadre des technologies Big Data.
Écosystème Hadoop
Sur les briques fondamentales d’Hadoop s’empilent des composants de plus haut niveau pour offrir différentes modalités de consommation et de manipulation de la donnée. En effet, comme écrire des applications MapReduce est une tâche complexe, plutôt dévolue au développeur, les distributions Hadoop proposent des outils d’analyse dédiés aux utilisateurs plus « standards ». Le diagramme suivant montre l’empilement des couches de composants qui forment une distribution Hadoop proposée par Hortonworks à base de composants open source.
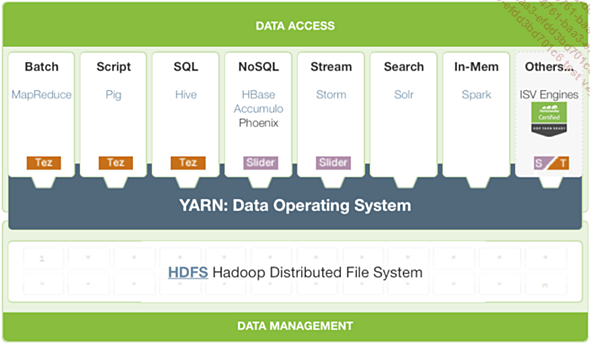
Figure 11.1 : Socle technologique Hadoop selon Hortonworks HDP 2.3
1. Acquisition des données
Dans cette section on décrit les quelques composants en charge d’acheminer les données de l’extérieur du cluster Hadoop vers celui-ci. Selon la nature du flux de données à mettre en place, du fait le plus souvent du système de stockage source de la donnée, on choisira l’un ou l’autre de ces composants.
a. Sqoop
Apache Sqoop est un outil conçu pour transférer des données entre Hadoop et des bases de données relationnelles ou mainframes. Vous pouvez utiliser Sqoop pour importer des données à partir d’un système de gestion de base de données relationnelle (SGBDR) comme MySQL ou Oracle ou d’un ordinateur central dans le système de fichiers distribués Hadoop (HDFS), transformer les données dans Hadoop MapReduce, puis exporter les données dans un autre SGBDR.
Sqoop automatise la plus grande partie de ce processus en se fondant sur la base de données pour décrire le schéma des données à importer. Sqoop utilise MapReduce pour importer et exporter les données, ce qui fournit un fonctionnement en parallèle ainsi que la tolérance aux pannes.
Avec Sqoop, vous pouvez importer des données à partir d’un système de base de données relationnelle ou un mainframe dans HDFS. L’entrée du processus d’importation est soit la table ou des ensembles de données mainframe. Pour les bases de données, Sqoop va lire la table ligne par ligne dans HDFS. Pour les ensembles de données mainframe, Sqoop lira...
Lambda-Architecture
Face à la profusion de composants disponibles, il n’est pas toujours évident pour l’architecte de faire des choix pérennes. De même qu’il n’est pas non plus simple de convaincre un public de néophytes en Big Data que notre architecture est la meilleure, d’autant qu’on a encore peu de recul sur les bonnes pratiques et les motifs de conceptions de cette branche de l’informatique. Toutefois, un concept structurel a émergé récemment, qui commence à faire référence en la matière dès lors qu’on doit bâtir un système alliant à la fois les traitements temps réel et les jobs longue durée (batch). Il s’agit du principe de λ-Architecture défini par Nathan Marz pour atténuer le problème de latences introduites par les jobs MapReduce.
On peut appliquer ce genre d’architecture à tout système qui doit mélanger des traitements longs sur des gros volumes de données (pour bâtir des modèles de machine learning) et des traitements temps réel comme par exemple de la recommandation temps réel (historique de navigation récente, géolocalisation, profilage, marketing, publicité en ligne), de la supervision d’infrastructures (industrie télécom, datacenters), de l’agrégation d’informations boursières ou financières, des objets connectés, de la gestion de stocks, de chiffre d’affaires temps réel ou encore de la détection de fraude.
1. Principes et avantages
Les principes de la λ-Architecture sont simples :
-
Les données sont stockées dans un ensemble de données maître (master dataset) qui est immutable, on ne peut donc pas y mettre à jour les données, juste y faire des insertions ce qui garantit plus d’efficacité et de robustesse.
-
On utilise des vues pré-calculées sur ce master dataset pour la séparation des problèmes, la dénormalisation, l’indexation et les agrégations des données.
-
On répartit les données sur trois niveaux de traitements : batch, service et temps réel.
On considère la couche de service (serving layer) comme une fonction du master dataset....