
Les outils techniques
Code versioning
En développement informatique, le code d’un projet conséquent se retrouve éclaté en milliers de fichiers. Parmi cette quantité de fichiers, il est tout à fait possible que plusieurs développeurs soient amenés à travailler sur un même fichier à un moment donné.
Chaque développeur tape son code en local sur sa machine ; quand il a fini, il enregistre son code sur un tronc commun situé sur un serveur distant.
Or, si deux développeurs ont travaillé sur un même code d’un même fichier, au moment d’enregistrer sur le tronc commun, il risque d’y avoir des conflits. Quel code faut-il alors conserver ? Il n’y a pas de système de verrouillage sur les fichiers, de sorte que quand j’utilise le fichier, les autres ne peuvent le modifier ! Un bon logiciel de gestion de code versioning sait parfaitement traiter ce genre de conflit. C’est la base pour travailler en équipe sans perdre de temps à attendre que les fichiers soient disponibles. La référence dans le domaine est de loin l’application GitHub. Ce type d’application permet d’effectuer toutes les actions possibles dans le quotidien du développeur : récupérer tout le code du projet à partir du tronc commun, afin de le copier en local.
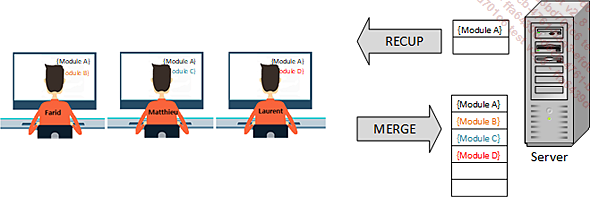
C’est ce qu’on appelle la création de l’espace de travail du développeur où il pourra ensuite ajouter, supprimer ou modifier les fichiers du projet. Une fois son travail terminé, il pourra expédier le résultat sur le tronc commun. Cette action nécessite quelques vérifications avant de valider les modifications. Ce type d’application permet aussi d’avoir toute sorte d’information sur les fichiers : par exemple, qui a saisi tel code, quand, pourquoi, qui a supprimé, qui a modifié, qui a fait le café... non, oublions ce dernier, il ne faut pas exagérer !
Vous avez ci-dessus une photo de mon écran, je suis en train de taper du code sur le fichier ElecConsumptionController.cs.
Un projet peut contenir des milliers de fichiers de ce type et l’ensemble des lignes de code du projet peut largement dépasser le million. Dans le jargon informatique, le tronc commun s’appelle...
Intégration continue
L’intégration continue (CI) a pour but de traiter chaque merge effectué sur la branche Main ; on intègre son code à celui de ses collègues.
Pour rappel, lorsqu’un développeur a fini son code, il effectue une Pull Request pour soumettre son travail. Lors de la validation de cette PR, l’intégration continue démarre. En fait, aujourd’hui, la CI fait bien plus qu’une simple intégration du code (merge) dans la branche Main. Après le merge, on y trouve désormais un ensemble de filtres posés les uns derrière les autres qui vont automatiquement s’exécuter l’un après l’autre dès qu’un code est fusionné dans la branche Main. L’ensemble de ces filtres disposés en file s’appelle un pipeline ou workflow applicatif. Ces filtres sont donc des éléments exécutables (une application, un script, un job, un bout de code, un service, un web service, un microservice...) qui vont s’exécuter de manière séquentielle dans l’ordre dans lequel ils se trouvent dans le pipeline.
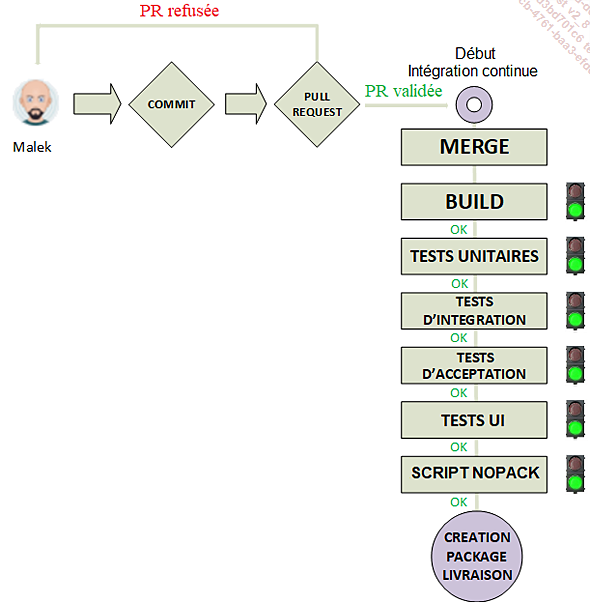
Le but de la CI est de s’assurer que le merge d’un nouveau code sur la branche Main n’a pas entraîné d’erreur, afin de nous éviter de construire un package de livraison rempli de bugs en tout genre....
Déploiement continu
Déployer une application, c’est l’installer sur une machine pour que les usagers puissent l’utiliser. Le déploiement continu (CD) n’est que la suite logique de l’intégration continue ! Une fois que le pipeline de la CI a fabriqué notre package de livraison, il ne reste plus qu’à installer ce package sur un serveur pour que l’application puisse être utilisée.
Autrefois, cette installation se faisait de façon manuelle mais aujourd’hui, grâce au CD, on peut installer notre application à la volée dans n’importe quel environnement.
La plupart des systèmes de déploiement continu nécessitent une longue phase de paramétrage pour spécifier les différents environnements vers lesquels on souhaite installer notre package de livraison. Une fois ce paramétrage effectué, nous sommes en mesure d’installer notre application sur n’importe quel serveur en un clic de souris. En couplant un système de déploiement continu avec un système d’intégration continue, on obtient le duo CI/CD. Lors de nos déploiements, nous pouvons donc avoir l’assurance que les packages de livraison que nous recevons du CI ont été parfaitement testés. On réduit ainsi considérablement les bugs qui seraient...
Les microservices
On pourrait parler de l’architecture microservices durant des heures, mais nous allons nous contenter de comprendre globalement les concepts qui tournent autour de cette formidable technologie à base de containers.
Le schéma ci-dessous décrit différentes façons d’exécuter un programme :
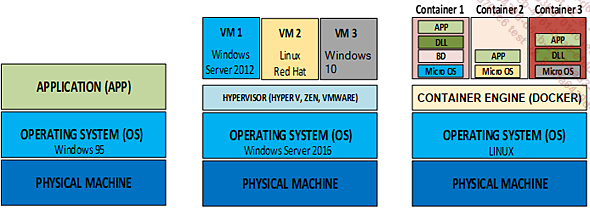
Pour exécuter un programme informatique, le strict minimum requis est un ordinateur avec un système d’exploitation (OS) et un système de fichiers. Cet ordinateur doit bien sûr posséder des éléments électroniques comme un microprocesseur, une RAM, un disque dur, etc. Le système d’exploitation va dialoguer avec toute l’électronique de la machine pour exécuter un programme récupéré dans le système de fichiers.
En gros, quand vous lancez une application, l’OS charge le code de l’application en mémoire RAM et le microprocesseur exécute les lignes de code du programme. Dans les années 90, à mon domicile j’avais un réseau avec deux ordinateurs tournant sur l’OS Windows NT, un ordinateur tournant sous Unix (l’ancêtre de Linux) et une machine AS400 tournant sous OS400. Toutes ces machines prenaient beaucoup de place.
Le jour où les VM ont fait leur apparition sur le marché, ce problème a été vite réglé !
La technologie des VM ou la virtualisation consiste à simuler une ou plusieurs machines dans une vraie machine. Autrement dit, avec un seul ordinateur il est possible d’avoir plusieurs machines tournant chacune sur un OS propre ! Chaque VM installée dans l’ordinateur simulera un autre ordinateur avec son propre OS ! Sur le schéma ci-dessus, dans la colonne centrale, on a installé trois VM sur une machine sous Windows Server 2016 : une VM tournant sous Windows Server 2012, une autre tournant sous Red Hat et une troisième simulant l’OS Windows 10. On dispose donc de quatre machines, une vraie et trois virtuelles ! Au moment d’allumer l’ordinateur, Windows Server 2016 se mettra en route et, sur l’écran, un logiciel tel VMware (un hypervisor) proposera les VM installées sur l’ordinateur. Ainsi, pour travailler sur Red Hat, par exemple, il suffira...



