
Intégration et déploiement continus (CI/CD)
Présentation générale de Git
1. Concepts fondamentaux de Git
a. Histoire de Git
L’histoire de Git est assez intéressante, car elle recoupe celle de Linux. En effet, c’est Linus Torvalds, le père de Linux, qui en est à l’origine !
En 2002, le projet du noyau Linux commence à utiliser BitKeeper, qui est un logiciel propriétaire permettant de faire du versioning de code. Cependant, en 2005, les relations entre Linux et BitKeeper se dégradent, au point que la gratuité de BitKeeper est remise en question.
Linus Torvalds décide alors de développer son propre outil, gratuit et open source, pour permettre à la communauté Linux de continuer à collaborer sur le développement du noyau.
C’est ainsi que Git a été adopté de manière massive par des plateformes de développement modernes. GitHub et GitLab sont devenus des plateformes d’excellence pour héberger les projets Git, offrant des fonctionnalités que nous allons détailler dans ce chapitre comme l’intégration continue (CI), le déploiement continu (CD), la gestion des Issues, des requêtes, et permettant une collaboration plus simple et efficace entre les développeurs.
En 2018, Microsoft a acquis GitHub, ce qui souligne à nouveau l’importance stratégique et la popularité de Git dans l’écosystème informatique actuel.
Git continue d’évoluer et est maintenant utilisé par plus de 12 millions de personnes à travers le monde, ce qui en fait le logiciel de gestion de versions (ou de versioning) le plus populaire au moment de l’écriture de cet ouvrage, en 2024.
b. Système de gestion de versions centralisé
Dans ce type de système, nous avons un serveur central qui contient tous les fichiers, avec les versions et l’historique des changements qui y sont associés.
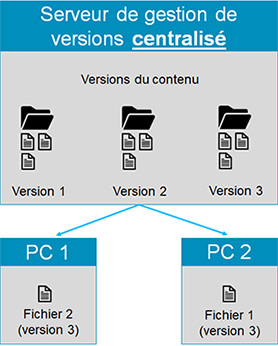
Chaque utilisateur qui travaille sur le projet peut télécharger les fichiers dont il a besoin. Chaque modification qu’il effectue localement est ensuite versionnée et ajoutée à l’historique.
Cependant, ce type de système présente un certain nombre de difficultés. En effet, en cas de dysfonctionnement du serveur central, les développeurs...
L’intégration continue
De manière générale, l’intégration continue correspond à des pratiques de développement impliquant le commit du code dans un dépôt partagé par les développeurs.
1. La phase de build
Lorsque plusieurs développeurs travaillent en même temps sur un seul et même code, il est nécessaire de mettre en place des solutions permettant d’empêcher des incompatibilités et des dysfonctionnements d’opérer.
Le développeur commence par effectuer un commit du code et par pousser les modifications qu’il a apportées au niveau du dépôt de code (par exemple GitLab).
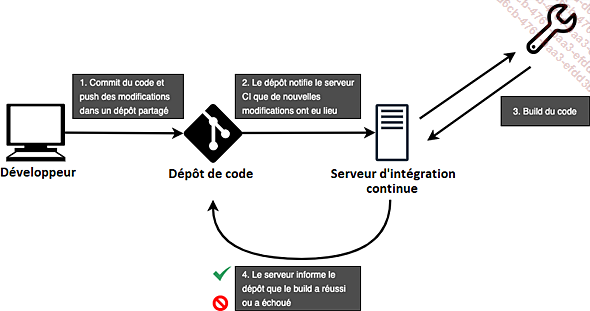
Une fois que le code a été poussé par le développeur sur le dépôt de code, ce dernier notifie le serveur d’intégration continue que de nouvelles modifications ont eu lieu.
Le code est ainsi buildé par le serveur (Jenkins, ou GitLab-CI par exemple). L’étape de Build correspond aux processus grâce auxquels le code source initial est converti en un fichier, ou un ensemble de fichiers, directement exécutable(s) sur un ordinateur ou un serveur. C’est d’ailleurs durant ces étapes qu’a lieu, pour certains langages, le processus de compilation, où les fichiers correspondant au code source sont convertis en un code directement exécutable (souvent du langage machine ou du binaire).
Lorsque cette troisième étape est effectuée...
Créer votre propre pipeline CI (Continuous Integration)
L’objectif de cette section est de créer un premier pipeline d’intégration continue, en utilisant les outils suivants :
-
Python
-
Git
-
GitLab-CI
Évidemment, elle n’a pas pour but de maîtriser l’ensemble des outils, mais plutôt de vous accompagner dans la création et l’assemblage de ces différents éléments.
1. Architecture de GitLab-CI
a. Serveur GitLab et Runners
Le serveur GitLab fournit une interface permettant de créer des repositories et de gérer l’ensemble des éléments qui sont liés à votre projet. Les différentes actions que vous réalisez sont enregistrées dans une base de données associée à votre serveur GitLab.
Lors de la création d’un pipeline, celui-ci est géré par le serveur GitLab lui-même, mais la réalisation des actions est déléguée à ce que l’on appelle un GitLab Runner. C’est donc sur ce Runner que sont exécutées les différentes tâches que vous souhaitez effectuer pour les actions de build ou de test.
Pour effectuer des actions d’intégration continue avec GitLab, vous avez donc besoin au minimum d’un serveur GitLab et d’un Runner. Il est cependant courant d’avoir plusieurs Runners GitLab, pour avoir la capacité d’exécuter des jobs en parallèle sur plusieurs projets en même temps.
Voici les différentes étapes effectuées par GitLab lorsque vous cherchez à exécuter un job avec l’outil GitLab-CI :
-
instanciation du Runner GitLab grâce à l’image Docker spécifiée en paramètre ;
-
clonage du dépôt Git du projet, dans le répertoire principal du Runner (tous les fichiers de notre dépôt sont donc disponibles dans le Runner) ;
-
exécution des différentes commandes indiquées ;
-
optionnel - export des artefacts générés durant le job ;
-
validation du job (code retour de valeur 0) ou échec du job (code retour différent de 0) ;
-
conservation des logs et suppression du conteneur créé pour réaliser le job.
b. Les Shared...
Aller plus loin avec GitLab-CI
1. Exécuter plusieurs jobs en parallèle
Comme expliqué précédemment, vous pouvez tout à fait lancer plusieurs jobs en même temps sur votre Runner GitLab. Il est cependant nécessaire que les jobs appartiennent au même stage.
Par exemple, prenons le cas où nous souhaitons effectuer plusieurs tests sur notre code, comme :
-
la correspondance avec le standard Flake8 ;
-
une analyse de sécurité ;
-
un lint avec Pylint.
Il est alors possible de construire un pipeline dont le fichier .gitlab-ci.yml ressemblerait à ceci :
stages:
- code
flake8_code:
stage: code
image: python
before_script:
- pip install flake8
script:
- flake8 password_check.py
allow_failure: true
security_code:
stage: code
image: python
before_script:
- pip install bandit
script:
- bandit -r password_check.py
allow_failure: true
pylint_code:
stage: code
image: python
before_script:
- pip install pylint
script:
- pylint password_check.py
allow_failure: true Exécutez ensuite les commandes suivantes sur votre terminal Git Bash, afin de pousser le fichier .gitlab-ci.yml sur le dépôt Git.
git commit -a -m "Test multiples jobs"
git push -u origin main Le résultat correspond à un pipeline qui ressemble à ceci :
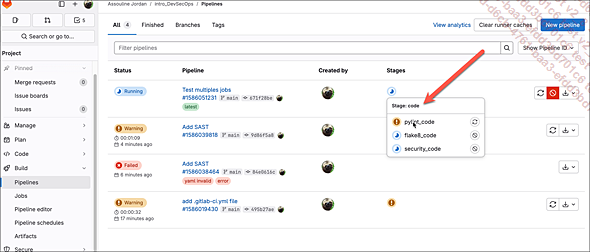
Il y a quelque chose d’intéressant à observer ! En effet, plutôt que les trois jobs s’exécutent les uns après les autres, vous...
Le Continuous Delivery
Le Continuous Delivery correspond à la capacité à fournir un software (ou du code source) qui est toujours dans un releasable state (disponible pour être utilisé par le client) à travers le cycle de vie du code.
En réalité, le Continuous Delivery amène l’intégration continue à un niveau supérieur.
1. Les bénéfices du Continuous Delivery
Le Continuous Delivery permet de fournir rapidement des feedbacks automatiques sur les environnements de préproduction et de production (cf. chapitre Introduction au DevSecOps).
En effet, le service ou logiciel est toujours gardé dans un état releasable et déployable même lorsque de nouvelles fonctionnalités sont en cours de développement.
Cependant, pour être efficace, il faut que le Continuous Delivery soit accompagné de la mise en place d’un pipeline permettant de faire du déploiement à la demande. Cela permet d’arriver à un état de réduction des coûts, de gain de temps et de diminution des risques inhérents aux changements incrémentaux réalisés.
2. Les différences avec le déploiement continu
Il ne faut pas confondre les notions de déploiement continu avec celles de Continuous Delivery. En effet, elles ne correspondent pas spécifiquement aux mêmes...
Déploiement continu
1. Quelques règles de bonnes pratiques
Mettre en place du déploiement continu implique un certain nombre d’investissements au niveau ingénierie. En effet, il devient nécessaire d’implémenter de nouveaux outils.
La condition indispensable à un bon déploiement continu correspond à la capacité d’effectuer de bons tests automatiques. Ces tests sont effectués pour prévenir des risques de régressions lorsque du nouveau code est introduit, et ainsi remplacer les phases de revues de code manuelles. Comme expliqué précédemment, ils peuvent être réalisés lors des phases d’intégration continue.
Il est également nécessaire de pouvoir effectuer un retour en arrière rapide (rollback) en cas de dysfonctionnement d’une nouvelle version déployée. On peut ainsi utiliser les techniques de déploiement Blue/Green, par exemple (expliquées un peu plus loin dans ce chapitre).
Enfin, une bonne infrastructure est une infrastructure supervisée, sur laquelle un certain nombre d’alertes ont été implémentées pour avoir la capacité de détecter les dysfonctionnements qui peuvent apparaître.
2. Méthode Blue/Green
Cette méthode apparaît pour la première fois dans le livre Continuous...
Conclusion
Nous avons repris les bases de l’utilisation de Git, un outil indispensable pour les DevOps et les DevSecOps. Grâce à Git, il devient possible de générer automatiquement des pipelines d’intégration continue via GitLab-CI, Jenkins, ou encore GitHub Actions. Cette phase d’intégration continue est elle-même composée de plusieurs étapes : lint et build du code, et tests fonctionnels, non fonctionnels et de sécurité. Nous avons également abordé les sujets du Continuous Delivery et du Continuous Deployment, avec les différences qui les caractérisent, ainsi que la manière dont les méthodes Blue/Green et de Canary Releases nous permettent de faire des déploiements en Zero Downtime (ZDD).
Dans un monde où la capacité à délivrer rapidement et de manière sécurisée sont devenues des priorités absolues, votre outillage peut être amené à changer, mais ces pratiques sont avant tout destinées à transformer profondément la philosophie et la vision de votre entreprise et de vos équipes. C’est d’ailleurs l’objectif des chapitres suivants de vous apporter une vision approfondie des outils et pratiques ainsi que des approches complémentaires qui vous permettront de mettre toutes ces notions en pratique dans...