
Utilisation de Kubernetes en DevSecOps
Introduction
Maintenant que nous avons abordé l’installation et l’utilisation de Docker, il est temps de nous tourner vers Kubernetes. En effet, il s’agit de la solution la plus utilisée pour l’orchestration des conteneurs en 2023.
La prise en main de Kubernetes
Voici la définition officielle disponible sur le site https://kubernetes.io : « Kubernetes (K8s) est un système open-source permettant d’automatiser le déploiement, la mise à l’échelle et la gestion des applications conteneurisées ».
1. Principe de déploiement
Concentrons-nous tout d’abord sur la première partie, portant sur le déploiement. En effet, nous avons vu qu’il était simple de créer un conteneur Docker à partir d’une image, sur un ordinateur ou un serveur, grâce aux commandes docker run.
Cependant, que se passe-t-il lorsque nous possédons plusieurs serveurs à notre disposition ?
Une question potentielle que vous pourriez vous poser serait : pourquoi aurions-nous plusieurs serveurs sur lesquels nous souhaiterions déployer notre conteneur ?
Première réponse : répondre efficacement à des clients répartis sur le globe. En effet, il est beaucoup plus performant d’avoir des services situés géographiquement au plus proche des clients.
Imaginez que vous ayez des clients en France et aux États-Unis. La latence serait trop importante pour les clients australiens s’ils devaient se connecter à des services hébergés sur des serveurs en France. Il faudrait donc répliquer les services sur des serveurs situés en France et sur des serveurs situés aux États-Unis, ce qui peut vite devenir compliqué à gérer.
Deuxième réponse : augmenter les performances. En effet, un serveur ne peut supporter qu’un certain nombre de conteneurs. Imaginez que vous ayez à votre disposition des serveurs de 4 vCPU avec 8 GB de RAM. La consommation de vos services va drastiquement dépendre...
Le concept de Cluster
Nous avons abordé le sujet de pools de serveurs qu’il est possible de configurer grâce à Kubernetes dans la section précédente. Cependant, ce que nous n’avons pas détaillé, c’est le fait que ces serveurs appartiennent à ce que l’on appelle un cluster.
Vous l’avez donc compris, un cluster Kubernetes correspond simplement à un groupe de machines (que l’on appelle des nodes, signifiant nœuds en français) qui sont associées, et sur lesquelles des conteneurs sont exécutés.
Il est important de comprendre que tous les nodes d’un même cluster Kubernetes n’ont pas la même « intelligence ».
1. Les composants de Kubernetes
Tout d’abord, nous allons décrire l’ensemble des services qui composent Kubernetes.
-
kube-apiserver : correspond au « cerveau » de Kubernetes. C’est à ce service que l’on demande de créer de nouveaux objets, comme les pods (qui contiennent les conteneurs), les services, les replicas, etc. On dit également qu’il fournit le « Front-End » de la partie Control Plane dont nous parlerons dans la section suivante.
-
etcd : correspond à la base de données du cluster Kubernetes. Vous pouvez y retrouver, notamment, les informations permettant d’identifier les différents nœuds qui sont membres du cluster et l’état dans lequel ils se trouvent.
-
kube-scheduler : correspond au service capable de déterminer sur quels nodes sont déployés les nouveaux conteneurs. Ce service utilise plusieurs informations pour prendre sa décision : ressources CPU et RAM disponibles et nécessaires, contraintes de localisation (si les conteneurs doivent être déployés spécifiquement...
La sécurité de son cluster Kubernetes
1. CIS Benchmarks
Tout comme nous l’avions fait pour Docker, il est important de vérifier qu’au-delà de la configuration des objets de Kubernetes, le cluster lui-même n’est pas vulnérable.
Il existe un CIS Benchmark dédié à la version communautaire de Kubernetes : https://www.cisecurity.org/benchmark/kubernetes/
Dans le document, les vérifications sont découpées en plusieurs grandes parties :
-
Composants du Control Plane :
-
Fichiers de configuration des nodes du Control Plane
-
API Server
-
Controller Manager
-
Scheduler
-
Etcd
-
Configuration du Control Plane :
-
Authentification et Authorization
-
Logging
-
Worker nodes
-
Fichiers de configuration du Worker node
-
Kubelet
-
Politiques de sécurité
-
RBAC et Service Accounts
-
Standards de sécurité des Pods
-
Politiques de sécurité réseau et CNI
-
Gestion des secrets
-
Politiques de sécurité générales
Le document faisant plus de 300 pages, nous conviendrons qu’il n’est pas aisé d’analyser chaque élément.
Heureusement, d’autres ont déjà effectué le travail en développant des outils permettant d’analyser tous ces éléments à votre place.
2. Utilisation de Kube-Bench
a. Exécuter Kube-Bench
Kube-Bench est un outil développé par Aquasecurity sous licence Apache 2.0, dont l’objectif est de vérifier que l’ensemble des éléments indiqués dans le fichier du CIS Benchmark sont respectés sur votre cluster. Vous pouvez retrouver le dépôt officiel de cet outil à l’adresse : https://github.com/aquasecurity/kube-bench
Pour exécuter Kube-Bench sur votre cluster, vous devez au préalable télécharger un fichier de...
Les Objets dans Kubernetes
1. YAML
Dans Kubernetes, quasiment tous les éléments sont considérés comme des objets.
Les Pods sont l’un des objets Kubernetes les plus importants, puisque ce sont eux qui sont utilisés pour lancer et gérer les conteneurs sur nos nodes. C’est en interagissant avec le kube-apiserver que l’administrateur peut déclencher le déploiement de pods sur les nodes appartenant au cluster.
Le node peut ensuite notifier le kube-apiserver situé au niveau du Control Plane pour l’informer du statut de chaque conteneur en cours d’exécution, permettant à l’utilisateur d’avoir accès à l’état du conteneur en temps réel.
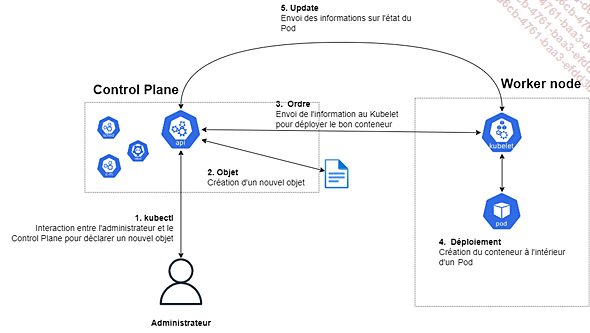
Pour être plus précis, voici les différentes étapes qui se déroulent lorsqu’un utilisateur souhaite déployer un conteneur sur les nodes, de manière abrégée et résumée :
-
L’utilisateur interagit avec le kube-apiserver pour lui indiquer qu’il souhaite déclarer un nouvel objet : un Pod, grâce à la commande kubectl.
-
Le kube-apiserver crée un objet au sein du Control Plane (généralement au format YAML) correspondant au Pod à déployer.
-
Le kube-apiserver envoie l’ordre de déployer le Pod avec la bonne configuration via le kubelet du Worker node.
-
Le Worker node tient le Control Plane informé du statut du conteneur.
La configuration des objets dans Kubernetes est souvent représentée par un fichier au format YAML.
Le YAML (YAML Ain’t Markup Language) est un langage permettant de représenter des données structurées (à la manière du XML ou du JSON). Il a notamment été développé pour être facilement lisible par des humains et pour être...
Les tests de Lint sur les objets Kubernetes
Dans cette section, nous allons voir comment effectuer un certain nombre de tests de sécurité sur les Manifests Kubernetes correspondant aux différents objets déjà utilisés dans ce chapitre. Nous allons nous baser sur GitLab-CI pour construire des pipelines d’intégration continue qui effectueront des tests de sécurité, comme nous l’avons déjà fait pour Docker.
1. Présentation de l’outil KubeLinter
Tout comme nous l’avions déjà fait pour Docker, nous allons voir les outils à notre disposition pour effectuer des tests de Lint sur nos Manifests Kubernetes. Cela nous permettra de savoir si nous ne sommes pas en train de construire un Pod, un Deployment, un ReplicaSet, ou un Service qui présenterait nativement des failles de sécurité liées à une mauvaise configuration des options et paramètres à disposition.
Pour cela, nous pouvons utiliser l’outil KubeLinter, qui a été développé en langage Go par stackrox sous licence Apache-2.0, et pour lequel vous pouvez retrouver le lien du dépôt GitHub à l’adresse https://github.com/stackrox/kube-linter.
Cet outil a été conçu pour analyser les fichiers YAML afin d’identifier des éléments de configuration à affiner pour renforcer la confidentialité, la sécurité et la disponibilité des objets Kubernetes que nous allons déployer sur notre Cluster.
Un des principaux intérêts de KubeLinter correspond au fait qu’il est possible de configurer l’outil pour y inclure ses propres tests et vérifications, qui seraient spécifiques à l’entreprise ou l’organisation dans laquelle vous vous trouvez. Par exemple, il devient possible...
Les tests de sécurité sur les objets Kubernetes
1. Présentation de l’outil Checkov
Checkov est un outil réalisé en Python, et sous licence Apache 2.0. Il permet d’effectuer de nombreux scans de vulnérabilités et de mauvaises configurations au niveau des outils DevOps et Cloud, comme Kubernetes, Terraform, CloudFormation, etc.
Vous pouvez retrouver le code de cet outil à l’adresse : https://github.com/bridgecrewio/checkov
Il s’agit d’un outil indispensable pour ceux qui souhaitent effectuer des scans de vulnérabilité sur l’ensemble de leur code, concernant de l’Infrastructure as Code, mais aussi des fichiers Dockerfile et des Manifests Kubernetes.
Pour utiliser Checkov, il suffit de l’installer grâce à l’utilitaire pip, avec la commande suivante :
pip3 install checkov==2.3.23 Pour réaliser le scan d’un répertoire, il est nécessaire d’utiliser la commande suivante :
checkov --directory /mon/repertoire Pour réaliser le scan d’un fichier, c’est la commande suivante :
checkov --file /monfichier.file Pour chaque vérification qui échoue, l’outil nous donne le lien vers la documentation permettant d’en savoir plus sur la manière dont il est possible de corriger la vulnérabilité ou la mauvaise configuration.
Exemple : https://docs.bridgecrew.io/docs/bc_k8s_28
Reprenons notre Manifest décrivant le Pod que nous avons corrigé précédemment, afin de vérifier si Checkov découvre d’autres vulnérabilités qui n’auraient pas été détectées par KubeLinter :
exemple-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers: ...Conclusion
Comme vous avez pu vous en apercevoir, il n’est pas toujours aisé de configurer vos objets Kubernetes en prenant en compte toutes les règles de bonnes pratiques, surtout en matière de sécurité. Évidemment, en fonction des objets que vous allez créer, KubeLinter ou Checkov n’affiche pas nécessairement les mêmes erreurs que celles que nous avons traitées à titre d’exemple dans ce chapitre. Cependant, cela vous permet d’avoir une bonne base concernant la méthodologie à appliquer lorsque vous souhaitez implémenter des outils de sécurité, et ensuite corriger vos fichiers YAML afin de réduire le nombre de vulnérabilités.
Il existe encore bien d’autres outils pour renforcer la sécurité de votre infrastructure et de vos objets Kubernetes, parmi lesquels :
-
Kubeaudit (https://github.com/Shopify/kubeaudit), permettant d’effectuer un audit de sécurité de vos clusters Kubernetes.
-
Kube-scan (https://github.com/octarinesec/kube-scan), permettant d’obtenir un score de risque de chaque objet de votre cluster.
-
Kube-score (https://github.com/zegl/kube-score), permettant de faire une analyse de sécurité statique des objets Kubernetes de votre cluster.
N’hésitez pas à tester ces outils sur vos clusters et vos objets et à comparer les résultats que vous obtenez afin d’en apprendre plus sur les vulnérabilités et la manière dont vous pouvez les corriger.
