
Maintenance du système en production
Analyse du système
1. Nécessité d’analyser son système
Un système ne doit pas être installé puis oublié, surtout s’il s’agit d’un serveur. Il est essentiel d’assurer un suivi, une maintenance, comme on le ferait avec une voiture par exemple.
Les systèmes Linux en général, et Red Hat Enterprise Linux en particulier, disposent de divers outils permettant de surveiller, d’entretenir et de réparer un serveur.
Certains de ces outils sont pro-actifs : ils vous permettent de « prédire » l’avenir et prévenir les problèmes qui pourraient arriver. D’autres outils sont réactifs : ils vous préviennent quand un problème survient.
On ne saurait insister sur un bon entretien du serveur. L’administrateur doit connaître ses machines et les analyser régulièrement mais aussi mettre en place dès le début les outils qui lui permettront d’être serein.
Également, il faut savoir quoi faire en cas de problème de performances du serveur. Cela nécessite de bien connaître son système et les outils à votre disposition. Il existe des méthodes pour la vérification de performances sur un serveur. Par exemple, la méthode USE (Utilisation, saturation et erreurs) permet de ne rien oublier lors de vérifications, et peut se résumer en cette phrase :
Pour chaque ressource, vérifiez l’utilisation, la saturation et les erreurs.
-
Les ressources étant les composants fonctionnels de l’OS : processeurs, mémoire, disques, bus de communication, interfaces réseau.
-
Utilisation : combien de temps en moyenne la ressource est occupée à accomplir sa tâche.
-
Saturation : à...
Programmation de tâches
1. Présentation
La programmation de tâches est une partie importante de la gestion du système au quotidien. Même s’il est vrai que l’administrateur doit opérer certaines tâches manuellement, de nombreuses tâches de gestion ou d’autogestion sont programmées et lancées automatiquement. Quelques-unes d’entre elles sont vraiment nécessaires ; d’autres vont permettre à l’administrateur de gagner du temps, comme les sauvegardes automatiques, la surveillance du système, le lancement de scripts, etc.
Le système principal utilisé pour la programmation de tâche est Cron. Il est indispensable pour un administrateur d’en maîtriser le fonctionnement. Il faut aussi connaître les commandes at et batch.
2. Programmation périodique avec Cron
a. Présentation
Cron, dont le nom vient du grec Chronos (le temps), permet aux utilisateurs du système, et surtout à l’administrateur, de programmer des tâches - qu’on appelle aussi des travaux - à des moments bien précis. Les caractéristiques de Cron étant que ces tâches sont répétitives, opérées sur une base régulière (de l’ordre de la minute, l’heure, le jour, la semaine, etc.), et que la machine doit être allumée en permanence pour pouvoir les exécuter. Cron est donc bien adapté aux serveurs, prévus pour fonctionner en mode 24/7.
Le service crond est donc bien sûr installé par défaut sur n’importe quel système Red Hat Enterprise Linux et lancé au démarrage de la machine, pour fonctionner en permanence.
b. Configuration du service
Le fichier de configuration du service est /etc/crontab.
Ce fichier contient la configuration du service...
Gestion du temps
1. Configuration manuelle du temps
La synchronisation de la date et de l’heure n’est pas à prendre à la légère sur un serveur. Pour beaucoup de services, c’est un mécanisme essentiel, comme par exemple la vérification de certificats dans la cryptographie asymétrique ou le lancement des tâches avec Cron.
Bien sûr, il est possible de configurer la date et l’heure simplement avec la commande date :
date MMDDhhmm
date MMDDhhmmYY.ss Avec MM pour le mois, DD pour le jour, hh pour l’heure, mm pour les minutes. Éventuellement, il est possible d’ajouter YY pour l’année et .ss pour les secondes.
Pour obtenir la date et l’heure, tapez simplement :
date Par exemple, pour configurer le 25 décembre à 23h59 :
[root@cs30 /]# date 12252359
lun. déc. 25 23:59:00 CET 2017
[root@cs30 /]# date
lun. déc. 25 23:59:37 CET 2017
[root@cs30 /]# 2. Configuration du fuseau horaire
La meilleure option reste cependant l’utilisation d’un serveur de temps qui vous garantit que l’heure est exacte et ce sur l’ensemble de vos machines.
Le protocole utilisé pour la synchronisation du temps est NTP (Network Time Protocol) et il est implémenté avec les services ntpd et chrony.
Commencez par configurer le fuseau horaire de votre serveur :
-
Listez les fuseaux horaires disponibles :
timedatectl list-timezones -
Configurez le fuseau horaire :
timedatectl set-timezone <fuseau horaire> Par exemple :
[root@cs30 /]# timedatectl list-timezones | grep -i paris
Europe/Paris
[root@cs30 /]# timedatectl set-timezone Europe/Paris
[root@cs30 /]# timedatectl
Local time: mar. 2017-12-26 00:07:28 CET
Universal time: lun. 2017-12-25 23:07:28 UTC
RTC...Gestion des processus
Dans vos tâches d’administration, il faudra lancer et gérer divers programmes et processus.
1. Contrôle des jobs
Comment gérer les processus que vous lancez et ceux qui sont exécutés par la machine ?
Le bash vous autorise à contrôler les processus que vous lancez en ligne de commande. Ces programmes sont appelés tâches (jobs). Le contrôle des jobs consiste à stopper ou suspendre leur exécution, et dans ce dernier cas, à reprendre l’exécution selon votre souhait. En résumé, cela vous permet de faire du multitâche dans un seul shell. Principalement, les jobs peuvent être dans quatre états : stoppés (mis en pause), à l’avant-plan (toujours en exécution), à l’arrière-plan (toujours en exécution mais vous permettant d’utiliser le shell), ou complété (travail accompli).
Les commandes principales pour manipuler les travaux sont les suivantes :
-
Afficher la liste des travaux : jobs -l
-
Mettre en pause un travail se trouvant à l’avant-plan : [Ctrl] Z
-
Placer un travail en exécution en arrière-plan : bg %<numéro du job>
-
Lancer un travail directement en arrière-plan : <commande> &
-
Déplacer une tâche de l’arrière-plan vers l’avant-plan : fg %<numéro du job>
-
Tuer un script qui tourne en boucle : [Ctrl] Z puis kill %%
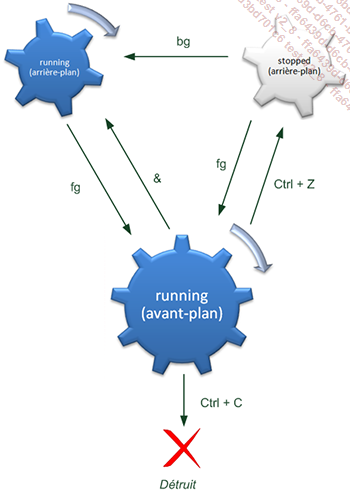
Source : https://openclassrooms.com/fr/
Mettre en pause un travail se trouvant à l’avant-plan
Par défaut, lorsque vous lancez un programme en ligne de commande, il est en avant-plan, c’est-à-dire que vous n’avez plus accès à la ligne de commande jusqu’à la fin de son exécution ; il n’est pas possible...
Améliorer la sécurité et la fiabilité
1. Plan de reprise d’activité
La sauvegarde de votre système est essentielle. Toujours dans le souci d’effectuer une administration sereine de votre serveur, il faut mettre en place la sauvegarde dès les premiers instants pour pouvoir remettre en service votre système le plus rapidement possible en cas de désastre.
Le plan de reprise d’activité définit comment assurer, en cas de crise majeure d’un centre informatique, la reconstruction de son infrastructure et la remise en route des applications.
Le PRA doit être défini correctement, sinon les conséquences d’un temps de panne trop long peuvent être désastreuses et coûter très cher à l’entreprise, surtout si des SLA (Service Level Agreements, accord de niveau de service) ont été définis avec les clients. Lorsque l’on planifie les processus de reprise d’activité d’un serveur, il faut penser à deux facteurs :
-
Le RTO (Recovery Time Objective, objectif de délai de retour) : temps prévu pour remettre le service en état.
-
Le RPO (Recovery Point Objective, objectif de point de retour) : état du service à la fin de la reprise d’activité.
-
Par exemple, dans le cas d’une base de données, toutes les transactions doivent-elles être conservées jusqu’à la dernière seconde ou seulement jusqu’à hier ?
-
Le service peut-il être fourni en mode dégradé, ou tous les services doivent-ils être disponibles ?
2. Politiques d’archivage et de sauvegardes
Une sauvegarde doit fournir :
-
la possibilité de restaurer les systèmes de fichiers entiers ;
-
la possibilité de restaurer des fichiers individuels ;...
Administration graphique avec la console web Cockpit
1. Présentation
Dans les pages de ce livre, nous fournissons parfois des explications sur les outils graphiques disponibles correspondant aux commandes en ligne utilisées pour l’administrateur du système.
Cependant, au regard de la diversité des distributions, des interfaces graphiques et des outils, ces GUI (Graphical User Interface, interface graphique utilisateur) sont difficiles à maintenir, de qualité très inégale et souvent incomplètes.
De plus, l’environnement graphique nécessaire pour l’exécution de ces outils d’administration (GNOME) est lui-même très lourd : il utilise des ressources processeur, disque et mémoire vive, de manière permanente (et pas à la demande). C’est pourquoi il existe une multitude d’outils d’administration à distance, mais, là encore, à la qualité inégale.
Pour ces raisons, à partir de RHEL 7, Red Hat a décidé d’implémenter dans ses serveurs un outil d’administration graphique reposant sur une interface web. Ce front-end, appelé Cockpit, est disponible sur de nombreuses distributions (dont RHEL et Ubuntu) avec une interface unique, facile à installer et facile à appréhender.
De plus, Cockpit est extensible et léger, contrairement aux outils dépendants d’une interface graphique lourde. En effet, lorsqu’il n’est pas utilisé, il n’utilise pas de ressources : un module écoute les connexions sur le port 9090 et lance Cockpit à la demande. De plus, il ne stocke pas de données d’administration en parallèle (dans une base de données, par exemple) : il se contente de lire et d’écrire dans les fichiers standards...
Dépannage d’un système RHEL
Le mode de dépannage consiste à prendre la main sur un serveur Red Hat Enterprise Linux qui refuse de démarrer. Les raisons peuvent être les suivantes :
-
Le système ne démarre pas : le démarrage dans les niveaux d’exécution 3 ou 5 échoue, il vous est impossible de vous connecter à une console locale.
-
Peut-être que la machine est accessible en connexion distante SSH ?
-
Il est possible que le système soit corrompu, ou que le chargeur de démarrage ait une défaillance.
-
Vous avez perdu le mot de passe root du système : vous apercevez l’invite de connexion au shell, mais vous ne pouvez pas administrer la machine.
Pour ces raisons et bien d’autres, il vous faudra accéder à votre système en mode de secours. Nous vous les indiquons ici ainsi que leur usage, mais la part la plus importante du travail reposera ensuite sur vos épaules et vos compétences techniques propres à la recherche de la cause de la panne.
Avec Red Hat Enterprise Linux, il existe plusieurs façons d’accéder à un système endommagé.
1. Mode de secours par DVD
C’est le mode de dépannage qu’il faut préférer.
Grâce au mode de secours (rescue mode en anglais), il est possible d’accéder aux fichiers d’un système Red Hat Enterprise Linux qui refuse de démarrer, soit parce que sa configuration est corrompue, soit parce qu’une partie des systèmes de fichiers est abimée.
Le mode de secours Anaconda Rescue Mode utilise le CD/DVD d’installation de Red Hat Enterprise Linux.
Pour démarrer en mode de secours :
Arrêtez la machine et insérez le CD/DVD d’installation de Red Hat Enterprise Linux 8 ou 9, selon votre installation....