
Les formats de fichiers populaires
Introduction
Ce chapitre est consacré à quelques-uns des multiples formats de fichiers que l’on peut trouver dans le monde de l’informatique et que l’on peut lire ou écrire avec Python.
Python se révèle un outil précieux, car il est capable de lire et d’écrire beaucoup de ces formats, d’accéder à de nombreuses bases de données et de pouvoir se connecter directement à des web services.
Bref, bien souvent, personne ne sait comment alimenter la base de données A avec les données du serveur B ; et là, nous proposons la solution : Python, et un peu de bon sens.
Le format de fichier "INI"
Honneur aux anciens, même si certains ne connaissent pas le format des fichiers de configuration ".ini", celui-ci peut encore servir.
Ce format a été introduit par les systèmes Windows à partir de 1985. De nombreux fichiers de paramétrage utilisaient ce format puis, petit à petit, les développeurs de Microsoft les ont remplacés par la redoutable "base de registre". Mais si vous cherchez bien, dans une machine Windows, on en trouve encore quelques-uns.
Et il y a aussi le fichier php.ini de l’incontournable langage PHP. Bref, ce format existe encore. Et c’est normal, car il s’agit d’un format simple, lisible par un être humain et éditable.
Un fichier .ini est structuré en chapitres, et dans un chapitre, on trouve des paramètres sous la forme "clé = valeur".
Le ’;’ point-virgule permet de laisser des commentaires, et c’est tout.
Voici un exemple de fichier :
; ------------------------------
; Exemple de fichier ini
; ------------------------------
;
; Un chapitre
[utilisateur]
default_user = demo
default_password = demo
; un autre chapitre
[database]
server = servbase.example.com
port = 1521 Le module capable de lire et d’écrire des fichiers de ce format se nomme configparser.
Pour l’utiliser et lire le fichier en exemple, la procédure est la suivante :...
Comma Separated Values : CSV
Ce format commence par une énigme : il n’existe pas de spécification fonctionnelle, et pourtant il est quotidiennement utilisé dans les environnements bureautiques ou en informatique de gestion. Cela vient certainement du fait que la majorité des tableurs le proposent comme format d’échange de données.
Pourtant, il s’agit tout simplement d’un format de fichier texte ouvert utilisé pour échanger des données tabulaires avec un séparateur de champ et un séparateur de lignes, et quelques options concernant les délimiteurs de chaînes de caractères.
Pour l’avoir très souvent rencontré dans son activité professionnelle, voici comment l’auteur conseille de l’utiliser :
Séparateur de champ : le code ascii n° 9 : TAB \t pour les unixiens.
Séparateur de lignes : le code ascii 10 : LF Line Feed \n.
Délimiteur de chaînes de caractères : le double guillemet ".
Mais ce n’est pas tout. Généralement, il faut se mettre d’accord sur le format des nombres, des dates, sur l’utilisation d’un jeu de caractères, sur la présence ou non de commentaires multilignes, sur l’éventuelle notation de mesures anglo-saxonnes, etc.
Malgré tout, une fois...
MS Office
Python possède des modules très performants pour générer des documents dans les formats bureautiques les plus connus.
Dans ce cas, il s’agit surtout de générer des documents et rarement de lire des documents pour en extraire les informations.
Le module docx
Ce module permet donc de générer des documents dans ce format, et ce d’une manière plutôt pratique et élégante.
Son installation s’effectue avec pip install python-docx.
Hormis le fait que, par défaut, tout est à la norme anglo-saxonne, son utilisation est plutôt agréable. Cependant, via un poste de travail sous Linux, il est difficile de juger de son efficacité si ce n’est à travers LibreOffice qui, nous le savons, lit très bien le format docx.
Comment cela fonctionne-t-il ?
Il faut importer du module docx la classe Document et, pour notre particularité européenne, il faut aussi importer de docx.shared les centimètres. Ensuite, on crée un objet issu de la classe Document.
Sous MS-Word, les documents sont structurés en sections, ce qui correspond à des pages, mais pas seulement. Pour accéder à la section courante, il suffit de demander la dernière en utilisant l’indice -1. Accéder à cette section permet de modifier les marges de la page/section et d’européaniser...
Le module odfpy
Ce module est peut-être moins facile d’accès que le précédent, mais il paraît quasiment sans limites, car grâce à ce module, l’ensemble du format OpenDocument semble à portée de clavier.
Fan de LibreOffice depuis ses débuts (cet ouvrage est d’ailleurs rédigé avec la version 6.4 dans sa première version et la version 7.4 dans sa seconde édition), l’auteur n’a pas trouvé de module Python permettant de dompter ce format.
Puis le module odfpy est apparu comme une solution. Cependant, dans l’état actuel des choses, la documentation est assez restreinte et manque cruellement d’exemples probants.
La première chose que l’on doit pouvoir contrôler sur un document texte, c’est le format des pages, l’orientation portrait ou paysage. Cela n’a pas été facile, peut-être aurait-il fallu se pencher sur le format OpenDocument avant de commencer à étudier ce module. Mais après quelques recherches, nous avons fini par trouver et vous livrons le résultat dans cet ouvrage.
Cependant, ce module va plus loin car il permet de générer, mais aussi de modifier et de manipuler des documents ; et pas seulement les documents textes, mais tous les autres : Draw, SpreadSheet, Chart, Présentation…
1. Document Texte
Générer un document texte avec ce module donne un résultat verbeux ; il faudra certainement factoriser le code pour obtenir quelque chose de plus élégant.
Par contre, en se penchant sur la documentation et sur les exemples, il sera possible de faire ce qu’offre le format OpenDocumenText et cela peut aller très loin.
Premier point : obtenir une page A4 avec des marges que l’on contrôle.
Pour cela, il faut créer un style de page et inclure ce style dans la "MasterPage" se nommant "Standard".
Puis il faut l’inclure dans les MasterStyles ; c’est à ce prix que vous pourrez gérer les paramètres de votre page.
Dans ce style de page, vous pouvez déterminer beaucoup de paramètres. Attention cependant, beaucoup ne sont pas mis par défaut et il faut quand même préciser pas mal de choses.
Ensuite, il faut créer...
Le module multi-format pyexcel
Ce module est très intéressant car il permet de générer et lire plusieurs formats.
À voir sur le site du module : http://docs.pyexcel.org/
|
pyexcel - Let you focus on data, instead of file formats |
Le but de ce module est de lire, manipuler et écrire dans un certain nombre de formats, dont : csv, ods, xls, xlsx et xlsm.
Avec ce module, les données stockées dans des "DataSheets" Excel ou LibreOffice sont transformées en objet Python comme des dictionnaires ou des tableaux (Array).
Il suffit tout simplement d’invoquer la bonne méthode, c’est presque magique !
Exemple
# fichier : fic_fmt/pyex1.py
from pyexcel import get_records
records = get_records(file_name="contacts.ods")
fmt = "|{NOM:30s} | {DATE_NAI:10s} | {TEL:20s} |"
for record in records:
print( fmt.format( **record )) La feuille de données est celle générée par le premier exemple de la section précédente, sauf que pour obtenir les noms des colonnes comme clés du dictionnaire, nous avons ajouté une ligne avec les noms, comme ceci :
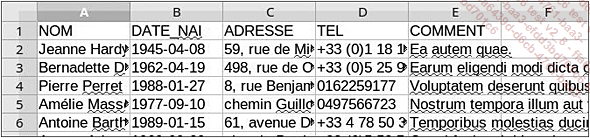
contacts.ods
À l’exécution, cela donne :
$ python pyex1.py
|Jeanne Hardy | 1945-04-08...Le format de fichier JSON
Le format de fichier JSON (JavaScript Object Notation) est un format de fichier texte de plus en plus utilisé pour faire communiquer des environnements hétérogènes, notamment pour les échanges basés sur le protocole AJAX et les web services.
Malgré l’acronyme de son nom, il s’est en quelque sorte échappé du langage JavaScript pour vivre de son côté. Il est maintenant devenu indépendant de ce langage. Quasiment tous les langages peuvent lire et écrire dans ce format.
Même s’il possède un type de données assez restreint, il permet néanmoins de faire simplement beaucoup de choses.
Avec Python, une fois le module importé, il y a 2 * 2 méthodes à retenir :
|
dumps() |
génère du texte au format JSON à partir d’une chaîne de caractères. |
loads() |
retourne un objet Python à partir d’une chaîne au format JSON. |
|
load() et dump() |
font la même chose, mais à partir d’un descripteur de fichier. |
Voici un petit exemple :
#fichier : fic_fmt/json1.py
import json
data = {
'quiz' : {
'Chapitre 1 : premier pas' : {
'Question 1' : {
'question' : 'Un...Le format de fichier XML
XML est bien plus qu’un simple format de fichier. Il ne faut jamais oublier que XML signifie eXtensible Markup Language, ou en bon français "langage extensible de balisage", et qu’il a été conçu à l’origine pour faciliter les échanges de données entre systèmes hétérogènes.
Mais en fait, XML peut être utilisé dans beaucoup d’autres domaines, à tel point qu’il fut un temps où, par un effet de mode, tout devait finir en XML. C’est un peu le problème de l’informatique moderne : dès qu’une "innovation" apparaît, elle devient la solution à tous les problèmes.
XML est exigeant ; c’est avant tout une structure arborescente avec une racine, des éléments et une syntaxe rigoureuse. Il est contraignant, mais c’est davantage une force qu’une faiblesse. Un document mal formé ou ne respectant pas les contraintes n’est plus du XML.
Sachant ceci, le but de cette section est de montrer comment générer du XML simple ou comment transformer un document XML en dictionnaire.
Il est tout à fait possible d’aller plus loin avec Python pour valider un document en fonction d’un schéma par exemple, mais on s’engouffre alors dans des problèmes plus complexes de programmation et on sort de l’objectif de cet ouvrage.
À savoir, si vous voulez vérifier la validité d’un document XML, la commande xmllint se trouvant dans toutes les bonnes distributions sera une alliée précieuse.
Le langage Python fournit un module très pratique pour les deux cas de figure : lire du XML et le transformer en dictionnaire Python, mais aussi l’inverse.
Ce module, comme toujours, est simple d’utilisation. Il suffit de lui fournir une chaîne ou un descripteur de fichier et de lui demander de ’parser’ le contenu. C’est après que cela se complique, surtout quand on ne comprend pas la structure d’un document XML.
Prenons un exemple simple : le fichier FOLDERS.xml utilisé par le Programme de Gestion Intégrée SAGE X3.
Ce fichier permet de connaître les dossiers applicatifs d’une solution, soit un environnement de l’ERP Sage...
Le module tarfile pour archives tar
Le format d’archive tar est bien connu des ingénieurs système. Littéralement, son nom signifie "Tape Archive", pour archivage sur bande magnétique.
Au siècle dernier, pendant la préhistoire, donc AVANT Internet et Linux, tar n’avait pas le succès qu’il a aujourd’hui et nous utilisions beaucoup plus cpio pour les sauvegardes (sur disquette et cassette...), notamment à cause d’un problème avec les liens.
De plus, le format tar n’était toujours pas portable entre les différents Unix ; cpio avait une option -c permettant justement de s’affranchir des problèmes de portabilité.
Puis Linux est arrivé, et surtout GNU Tar, une version sur-vitaminée de l’utilitaire d’origine, portable, facile à utiliser, avec plein d’options et surtout en open source, libre et installable sur de multiples Unix. À notre époque moderne, ce format est encore largement utilisé pour l’échange de multiples fichiers.
Le module tarfile de Python vous permet de créer et de lire des fichiers au format tar, mais pas seulement. Ce module prend aussi en charge les différentes compressions que l’on peut utiliser avec cet utilitaire.
En combinant tarfile et pathlib, le tout orchestré par l’instruction with, la création d’une archive tgz se fait en quelques lignes....
Le format zip
Ce format a été inventé par M. Phil Katz suite à un problème de droits entre PKARC, un logiciel qu’il avait créé, et le format de fichier ARC. M. Katz décida d’arrêter le développement de PKARC pour se consacrer à un autre format et un autre algorithme de compression : PKZIP, format d’archive rapidement appelé zip à cause de l’extension des fichiers : .zip.
Python a un module pour ce format d’archivage, et comme il est couramment utilisé pour pas mal de choses (.jar, OpenDocument, OOXML…), cela peut être intéressant de savoir le manipuler via le langage Python.
Exemple de script pour lister une archive
# fichier : fic_fmt/zip/zipfile2.py
import sys
import datetime
import zipfile
def pr_info(archive):
SYSTEM = { 0:'Windows', 3:'Unix' }
zf = zipfile.ZipFile(archive)
fmt = "{f:30s} | {d:10s} | {s:8s} | {v:5d} | \
{c_size:10d} | {u_size:10d} |"
for info in zf.infolist():
if info.filename.endswith('/'):
if len(info.filename) <= 29: ...Résumé
Cette section décrit un certain nombre de formats de fichiers utilisables avec Python.
Mais, avec ces quelques formats, cela vous permet de couvrir des domaines aussi vastes que :
La Bureautique odt csv docx xlsx
La gestion de configuration ini xml
L’échanges de données xml...
