
Simulation d'activité
Introduction
Lors de la mise en exploitation d’un système informatique quel qu’il soit, la montée en charge reste un passage critique. Ce qu’il y a de bien en informatique, c’est que l’on peut simuler la réalité. Et cela devient vraiment intéressant quand il est possible de simuler des dizaines, voire des centaines d’utilisateurs. Même si ceux-ci se comportent de manière idéale, sans faire d’erreur (après tout, il s’agit d’automates), cela permet au moins de valider des outils dans un contexte optimal. Rappelez-vous, tout n’est que question de volume et de fréquence.
Dans ce chapitre, nous allons voir comment simuler une activité d’informatique de gestion avec une pseudo entreprise qui pratique le négoce. C’est un cas facile et classique, mais cela permet de générer de l’activité sur un serveur et du volume de données.
À l’origine, ce petit projet devait me permettre de tester les sauvegardes RMAN de la base de données Oracle, or sauvegarder une base de données sans volume n’a quasiment aucun intérêt.
Effectuer une sauvegarde est toujours la partie la plus facile, c’est la restauration qui est compliquée et difficile. De plus, on restaure des données généralement dans un contexte tendu et stressant avec...
Description
L’entreprise "ACME Corporation" (le nom n’a pas d’importance) vend des produits à ses clients, et en fonction des quantités commandées, achète à ses fournisseurs le volume nécessaire pour honorer les commandes.
C’est ce que l’on appelle communément du négoce.
Il y a ici trois entités principales : Client/Produit/Fournisseur, qui deviendront des objets et des tables dans notre base de données.
Le client passe des commandes clients qui, une fois totalement livrées, pourront être facturées. Cela nous donne un objet "commande client" qui, au niveau de la base de données, deviendra une table d’en-têtes de commande et de lignes de commandes.
L’entreprise passe des commandes fournisseurs qui, elles, devront être réceptionnées. Cela donne un autre objet : lignes de commandes fournisseurs.
Et pour savoir où on en est pour chaque produit, on va gérer du stock, d’où le dernier objet : le stock.
La structure des données
Voici une description de la structure des données.
D’abord, sous forme de schéma :
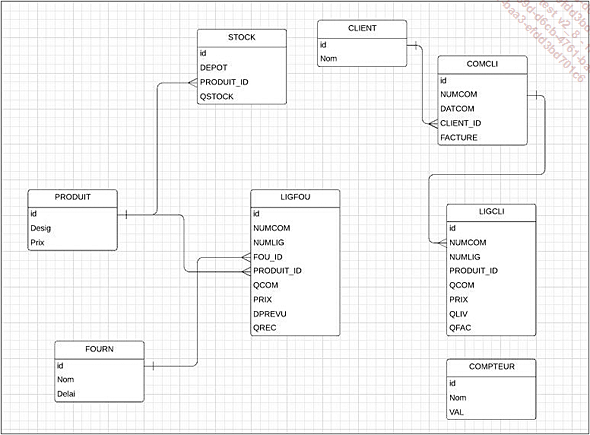
Structure des données
Puis plus détaillée :
Les tables Client/Produit/Fournisseur :
|
Table |
Champ |
Type |
Remarque |
|
CLIENT |
Nom |
Char(20) |
Clé unique |
|
PRODUIT |
Desig |
Char(30) |
Clé Unique/Désignation du produit |
|
PRODUIT |
Prix |
Flottant |
Le prix du produit |
|
FOURN |
Nom |
Char(20) |
Clé Unique |
|
FOURN |
Delai |
Entier |
Délai de réapprovisionnement |
La Table Stock :
|
Table |
Champ |
Type |
Remarque |
|
STOCK |
Dépôt |
Char(10) |
Code du Dépôt de marchandise |
|
STOCK |
PRO_ID |
|
Identifiant produit/clé étrangère |
|
STOCK |
QSTOCK |
Entier |
Quantité en stock |
Les commandes clients : les tables COMCLI et LIGCLI.
Table COMCLI (Commandes Client) :
|
Table |
Champ |
Type |
Remarque |
|
COMCLI |
NUMCOM |
Entier |
Clé unique |
|
COMCLI |
DATCOM |
Date |
Par défaut date de création |
|
COMCLI |
CLI_ID |
|
Identifiant Client/Clé étrangère |
|
COMCLI |
FACTURE |
Entier |
N° de facture |
Table LIGCLI (Lignes de commande client) :
|
Table |
Champ |
Type |
Remarque |
|
LIGCLI |
NUMCOM |
Entier |
N° de commande client |
|
LIGCLI |
NUMLIG |
Entier |
N° de ligne |
|
LIGCLI |
PRO_ID |
|
Identifiant produit/clé étrangère |
|
LIGCLI |
QCOM |
Entier |
Quantité commandée |
|
LIGCLI |
PRIX |
Flottant |
Prix du produit |
|
LIGCLI |
QLIV |
|
Quantité livrée |
|
LIGCLI |
QFAC |
Entier |
Quantité facturée |
La table LIGFOU des commandes fournisseurs :
|
Table |
Champ |
Type |
Remarque |
|
LIGFOU |
NUMCOM |
Entier |
N° de commande client |
|
LIGFOU |
NUMLIG |
Entier |
N° de ligne |
|
LIGFOU |
FOU_ID |
|
Identifiant fournisseur/clé étrangère |
|
LIGFOU |
PRO_ID |
|
Identifiant produit/clé étrangère |
|
LIGFOU |
QCOM |
Entier |
Quantité commandée |
|
LIGFOU |
PRIX |
Flottant |
Prix du produit |
|
LIGFOU |
DPREVU |
Date |
Date de livraison prévisionnelle |
|
LIGFOU |
QREC |
Entier |
Quantité reçue |
La gestion des compteurs nécessite la gestion d’une table supplémentaire. Un compteur permet de gérer les numéros de commande client, de commandes fournisseurs, de facture, etc.
Il est nécessaire de se coder une gestion des compteurs pour être indépendant de la base de données.
|
Table |
Champ |
Type |
Remarque |
|
COMPTEUR |
NOM |
Char(10) |
Nom du compteur |
|
COMPTEUR |
VAL |
Entier |
Valeur du compteur |
Cette...
L’initialisation de la base de données
SQLAlchemy a déjà été étudié un peu plus haut dans cet ouvrage et c’est pour cette raison que nous n’allons décrire que l’essentiel.
1. definitions.py
La première chose à faire est de décrire la structure des données sous forme d’objet Python.
Donc, le premier script s’appellera definitions.py et il devra définir la base de données que l’on veut créer.
Tout d’abord, il est nécessaire d’effectuer les bons imports de modules. SQLAlchemy est une grosse librairie et un import global (import SQLAlchemy.*) risque d’être coûteux en mémoire.
Il est nécessaire d’importer :
La définition des colonnes et des clés étrangères : Column ForeignKey.
Les types de données : Integer, String, DateTime, Date, Float, BigInteger.
Des méthodes et fonctions comme relationship, declarative_base et create_engine.
ForeignKey : une clé étrangère, dans une base de données relationnelle, est une contrainte qui garantit l’intégrité référentielle entre deux tables. Une clé étrangère identifie une colonne ou un ensemble de colonnes d’une table comme référençant une colonne ou un ensemble de colonnes d’une autre table.
Source Wikipédia : https://fr.wikipedia.org/wiki/Cl%C3%A9_%C3%A9trang%C3%A8re
D’un côté plus "pratique" ici : la déclaration d’une clé étrangère d’une table sur une autre garantit que, lors de la saisie d’une commande pour un client, ce client existe dans la table des clients, sinon la commande est refusée.
Le module de définitions doit être conçu pour être importé par les autres scripts ; les classes décrites ont besoin d’être représentées spécifiquement, d’où l’utilisation de la méthode __repr__.
Et comme il s’agit de classes Python, il est tout à fait possible de définir une classe de base contenant les champs revenant sur chaque classe.
Voici le fichier definitions.py :
#fichier : db-activity-gestion/definitions.py
## ------------------------------------- ...La connexion à la base de données
Le script précédent n’est à lancer qu’une seule fois pour l’initialisation de la base de données.
Pour la suite de la simulation, chaque script sera autonome, mais fonctionnera de la même manière :
-
Connexion à la base de données
-
Exécution de la fonction principale
Chaque script aura donc besoin d’une fonction connect() qui renverra un objet session.
C’est le but du script base.py que voici, agrémenté d’une simple fonction de récupération du catalogue des produits pour test :
#fichier : db-activity-gestion/base.py
from sqlalchemy import create_engine, select
from sqlalchemy.orm import sessionmaker
from definitions import Base, BASE_NAME
from definitions import Client, Produit, Fourn, Stock, ComCli,
LigCli, LigFou
def connect():
engine = create_engine(BASE_NAME, echo=False)
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
session = DBSession()
return session
def get_catalog():
session = connect()
s = select([Produit.id])
prods = session.execute(s)
p = [ x[0] for x in prods ]
session.close()
return p ...Les compteurs
Initialement, cette simulation a été conçue pour la base de données Oracle, qui possède de base une gestion de séquence. Ces séquences permettent d’obtenir une suite de numéros unique qui se suivent, mais sans garantir la continuité.
Malheureusement, cet objet de base de données n’existe pas dans certaines bases, dont SQLite. Cependant, c’est assez facile à coder, surtout avec Python.
Pour un compteur, c’est juste un nom et une valeur ; on a simplement besoin d’une fonction pour créer un compteur, une autre pour obtenir la prochaine valeur et, au cas où, une fonction pour obtenir la valeur courante.
Chaque fonction sera autonome et créera sa propre session.
Voici le script :
# fichier : db-activity-gestion/sequence.py
## -------------------------
## Librairie des sequences
## -------------------------
from sqlalchemy import create_engine, select
from sqlalchemy.orm import sessionmaker
from base import connect
from definitions import Compteur
def cr_Compteur(nom):
session = connect()
c = Compteur()
c.nom = nom
c.val = 1
session.add(c)
session.commit()
session.close()
def Curr_val(nom):
...Les commandes clients
Une fois que la base est initialisée, il est possible de se pencher sur la base du négoce, à savoir la commande client.
Pour cette simulation, ce script devra générer une commande client à partir du catalogue complet des produits et pour un client choisi au hasard.
Le script commence donc par récupérer le catalogue des produits, et surtout les informations intéressantes, à savoir l’identifiant du produit et son prix.
Ensuite, il faut trouver un client, et pour cela extraire les identifiants des clients et utiliser la fonction random.choice().
Il reste à sélectionner les produits commandés. Pour cela, la fonction random.sample() permet d’extraire un échantillon significatif.
Dans l’état actuel des choses, le maximum de produits commandés est calculé en fonction du nombre de produits ; cela convient quand il y a peu de produits. Mais si l’on veut un fichier produits plus imposant, il sera nécessaire de borner le nombre de produits commandés, pour ne pas avoir des commandes surréalistes de plusieurs milliers de lignes (même si cela existe réellement…).
Quand on a le client, la liste des produits commandés, on peut générer une commande. On prendra bien soin d’encadrer l’écriture dans la base de données par une gestion...
La livraison des commandes clients
Si on a des commandes et du stock, alors on peut procéder à la livraison des commandes clients.
Ce n’est guère plus compliqué que le reste, il faut rechercher les lignes de commandes dont la quantité commandée moins la quantité livrée est supérieure à zéro.
La requête SQL est beaucoup plus succincte qu’en langue française, car il s’agit ni plus ni moins que de :
select numcom, numlig, produit_id, qcom, qliv
from LIGCLI
where qcom-qliv > 0
order by numcom, numlig SQLAlchemy permet d’utiliser directement des requêtes avec la méthode execute() de la session en cours.
À partir du résultat de cette requête, nous pouvons travailler sur chaque commande et chaque ligne de chaque commande.
On commence par récupérer le stock de chaque produit, et si le stock est supérieur à la quantité nécessaire (qcom - qliv), alors nous pouvons allouer notre ligne et décrémenter le stock.
On remarquera la solution trouvée par les développeurs de SQLAlchemy pour exprimer des tests multiples dans la fonction get_stock() en cumulant les ".where".
Il n’y a pas trop de contrôle à ce niveau pour le stock négatif, ni trop de risques tant que ce script est lancé de manière...
La facturation des commandes livrées
Les commandes sont livrées, il est donc possible de les facturer. En fait, il s’agit plus d’un exercice obligeant à réfléchir sur la question.
Le principe de ce script est de rechercher les commandes clients non facturées (champ FACTURE == 0) et de vérifier si toutes les lignes ont été livrées.
C’est ce que réalise la fonction get_ccl_a_facturer() ; elle renvoie une liste des commandes à facturer.
Cette liste permet de lancer, pour chaque commande à facturer, la fonction facture_ccl(). Celle-ci a pour rôle de créer un numéro de facture, de lancer une commande SQL update pour mettre à jour la commande, et de mettre à jour les lignes de commandes en positionnant la quantité facturée à la quantité livrée.
Voici le script :
#fichier : db-activity-gestion/fact_client.py
from sqlalchemy import select
from base import connect
from definitions import Client, Produit, Fourn, Stock, ComCli,
LigCli, LigFou
import sequence as seq
import datetime
import random
# -------------------------------------
# Recherche des commandes facturables
# -------------------------------------
def get_ccl_a_facturer():
ccl_a_facturer = []
session...Le réapprovisionnement du stock
Au bout d’un moment, il n’y aura plus de stock et il faudra bien se fournir quelque part. C’est là qu’intervient le réapprovisionnement.
Dans cette simulation, chaque fournisseur est capable de livrer tous les produits. Dans la vie réelle, c’est beaucoup plus complexe.
Au début, pour effectuer des tests, le délai de réapprovisionnement est positionné à 0 jour pour éviter l’attente. Dans un contexte de simulation plus long, il est souhaitable de le modifier pour reproduire les flux d’une exploitation.
Comment réapprovisionne-t-on un stock ?
En calculant le besoin pour chaque produit. Cela se fait en deux passes :
La première cherche dans les commandes clients le volume de stock nécessaire pour chaque produit, avec une requête comme :
select produit_id, sum(qcom) 'qte'
from LIGCLI
where qcom-qliv > 0
group by produit_id
order by produit_id Cela signifie que l’on veut la liste des identifiants produits avec la somme des quantités commandées pour les lignes de commandes non livrées (qcom-qliv > 0) et, pour se simplifier la vie, on trie et on regroupe par identifiant produit.
Le résultat est la liste triée des besoins (la somme des quantités à livrer) pour chaque produit.
Cette liste brute des besoins...
La réception des commandes fournisseurs
Dernier script pour la gestion de cette petite entreprise de négoce : la réception des commandes fournisseurs.
Il suffit de rechercher les lignes de commandes fournisseurs dont la quantité commandée moins la quantité reçue est supérieur à zéro (qcom - qrecu > 0) et dont la date prévue est inférieure ou égale à la date du jour.
Dans l’affirmative, on récupère l’enregistrement de stock correspondant et l’on incrémente le stock avec la quantité reçue.
Dans la même transaction, on effectue une mise à jour de la ligne de commande fournisseur en incrémentant aussi la quantité reçue.
Voici le script :
# fichier : db-activity-gestion/recept_fou.py
from sqlalchemy import select
from base import connect
from definitions import Client, Produit, Fourn, Stock, ComCli,
LigCli, LigFou
import sequence as seq
import datetime
import random
def get_cfou_ar(date_jour):
session = connect()
r = select([LigFou]).\
where(LigFou.qcom-LigFou.qrecu > 0).\
where(LigFou.dprevu <= date_jour)
cfouar = session.execute(r).fetchall()
c...Utilisation
Voici un exemple d’utilisation pour ces scripts.
La première chose à faire est de choisir la base de données que l’on veut tester.
Ces scripts sont facilement adaptables pour une autre base de données grâce à l’utilisation de SQLAlchemy.
Le deuxième point est d’adapter le script populate.py au volume désiré ; par défaut, ce script crée 10 clients, produits, fournisseurs, ce qui permet de tester les scripts, mais même SQLite ne répond pas trop mal sur ces volumes.
Le dernier point est de choisir une période : heure, journée, 30 minutes. Tout dépend du temps et du volume que vous voulez générer.
Voici le tableau récapitulatif des scripts décrits précédemment :
|
Scripts |
Fréquence |
Remarque |
|
Populate.py |
1 seule fois |
Initialise la base de données |
|
Client.py |
Plusieurs fois/période |
La fréquence est à adapter en fonction du volume de flux désiré |
|
livraison_client.py |
2 fois par période |
|
|
fact_client.py |
1 fois par période |
Hors période d’exploitation |
|
reappro_fou.py |
1 fois par période |
Hors période d’exploitation |
|
recept_fou.py |
1 à 2 fois par période |
|
La période peut correspondre à une journée comme à une heure ou une minute, tout dépend du type de simulation souhaitée.
Voici un tableau de déclenchement des scripts qui pourrait correspondre à une exploitation classique, et qui permet aussi de bien séquencer les opérations afin de ne pas trop agacer le serveur.
Toutes les opérations devaient être terminées pour 22 h, heure à laquelle nous avions prévu une sauvegarde globale de la base de données.
|
Horaire |
|
|
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
||||
|
scripts |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
client.py |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
livraison_client.py |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
reappro_fou.py |
|
|
|
|
|
|
|
... | ||||||||||||
Résumé
À l’origine, ce projet devait permettre de tester sur une grande période les scripts de sauvegarde et de purge liés aux mécanismes d’archivage des fichiers de journalisation d’Oracle, plus connus sous les noms de RMAN et ARCHIVELOG.
En effet, il est difficile de tester ce genre de choses sur une base qui ne bouge pas et nous voulions un environnement de laboratoire pour comprendre un peu mieux comment évoluaient la consommation des ressources et surtout la ressource disque.
Au bout de quelques jours, cela a dépassé nos attentes, car nous pouvions aussi étudier sur du volume comment se comportait la base en fonction de paramètres volontairement réduits, comme la mémoire cache allouée (SGA, System GlobalArea).
Mais cela peut être transposé sur une autre base de données comme MySQL ou PostgreSQL et ainsi permettre de voir comment celle-ci réagit avec un volume que l’on a décidé et que l’on maîtrise.
Ces scripts sont volontairement simples, voire simplistes. Lorsqu’on a codé dans différents langages des équivalences plus complexes, il ne faut pas longtemps pour créer ces six scripts.
Cependant, il ne s’agit que de simulation, certainement imparfaite, et il ne faut pas trop pousser cette simulation pour que se déclenchent des erreurs...
