
Autres vulnérabilités applicatives
Introduction
Les vulnérabilités expliquées dans ce chapitre ne présentent pas nécessairement moins de risques que celles abordées précédemment, mais sont rencontrées peut-être moins fréquemment ou sont plus difficiles à identifier et à exploiter. Certaines ont été incluses dans les versions les plus récentes du Top Ten OWASP, c’est le cas de la vulnérabilité Server-Side Request Forgery (SSRF), introduite dans le Top Ten 2021. De même, les XML External Entities (XXE) ainsi que les failles liées à la désérialisation non sécurisée ont été présentées dans le Top Ten 2017.
Vulnérabilités logiques
1. Présentation
Les vulnérabilités logiques, désignées également par les termes « vulnérabilité métier » ou encore « vulnérabilité logique métier », se distinguent des vulnérabilités techniques, car résultent plutôt de lacunes dans la conception et la mise en œuvre de l’application web.
Ce type de faille nécessite une connaissance approfondie de l’application, du comportement attendu, de ses fonctionnalités et de ses objectifs. De plus, l’approche manuelle est obligatoire, car les outils ne détectent pas ce type de vulnérabilité.
Généralement, ces faiblesses surviennent lorsqu’un attaquant est en mesure d’identifier un moyen de contourner ou de manipuler une ou plusieurs étapes d’un flux métier. Cela est dû à un manque de contrôle concernant des états n’étant pas censés exister, qui peuvent survenir accidentellement, mais surtout lorsqu’une personne un peu trop curieuse interagit avec l’application de manière non prévue. Les risques associés dépendant de la nature de l’application, du flux métier impacté et du contournement identifié, et peuvent donc aller d’un risque insignifiant à important, voire dans certains cas, critique.
Un exemple de vulnérabilité métier souvent mentionné concerne les sites de e-commerce, ou du moins ceux qui offrent la possibilité de procéder à des achats en ligne. Une fois que le client a sélectionné les articles souhaités, et qu’il passe à l’étape de paiement, une requête contenant les détails de son panier est envoyée au serveur. Cette requête peut contenir les détails des articles sélectionnés, y compris la quantité de chaque article, leur prix, ainsi que le montant total du panier. Un utilisateur malveillant peut tenter d’intercepter cette requête en vue d’altérer le prix des articles, leur quantité ou le montant total du panier, permettant ainsi...
Insecure Deserialization
1. Présentation
La vulnérabilité de désérialisation non sécurisée repose sur l’utilisation de données non fiables lors du processus d’un flux de données sérialisées. Les conséquences de son exploitation varient en fonction du contexte de la vulnérabilité ainsi que de l’application, mais peut inclure le contournement d’autorisations ou d’authentification, le déni de service, la manipulation de la logique métier, voire l’exécution de code arbitraire.
La sérialisation est le procédé consistant à convertir un objet dans un format permettant son transport ou son stockage. Cette fonctionnalité est prise en charge par de nombreux langages, parmi lesquels figure PHP. Un intérêt supplémentaire réside dans le fait que la sérialisation d’un objet offre la possibilité de conserver la valeur de ses attributs, permettant ainsi de sauvegarder son état à un instant précis pouvant être rétabli ultérieurement.
Selon les langages et technologies, la sérialisation est également appelée marshalling ou linérarisation.
La désérialisation est le processus par lequel un flux de données est restauré en un objet fonctionnel représentant exactement l’état dans lequel il a été initialement sérialisé.

Selon le langage, la représentation d’un objet sérialisé peut être soit sous forme binaire, c’est le cas de Java, soit sous la forme d’une chaîne de caractères, par exemple en PHP.
La classe PHP suivante représente un utilisateur d’une application :
class User {
public $name;
public $age;
public function __construct($name, $age) {
$this->name = $name;
$this->age = $age;
}
} Un objet de la classe peut être sérialisé de la façon suivante :
$user = new User("John", 30);
echo serialize($user); Un tel objet, une fois sérialisé, est représenté de la façon suivante :...
Clickjacking
1. Présentation
Le clickjacking, également connu sous le nom de UI redressing, est une vulnérabilité permettant à un attaquant de voler (détourner) le clic d’un utilisateur. Ce détournement de clic permet de faire cliquer la victime sur une page, ou un élément de cette page, différent de celui qu’elle pense réellement cliquer. Pour cela, l’attaquant incite sa victime à consulter une page web qu’il possède sous son contrôle, et intègre, de façon transparente, une iframe du site ciblé.
Un exemple permet de mieux cerner le fonctionnement de cette faiblesse ainsi que son exploitation. Un camping offre la possibilité de louer un emplacement en utilisant son site web comme plateforme de réservation en ligne. Sur le site, les utilisateurs authentifiés peuvent accéder à des informations détaillées sur les emplacements disponibles ainsi que sur les tarifs. Une fois l’emplacement réservé, le client peut annuler en un clic sa réservation.
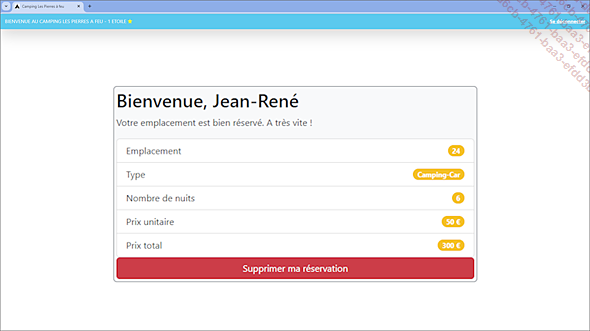
Les vacances arrivant, tous les emplacements sont réservés et il n’est plus possible pour un nouveau client d’obtenir un emplacement.
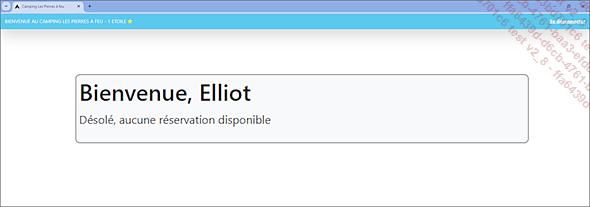
Elliot, client mécontent de ne pas pouvoir réserver son emplacement, décide alors de tromper un autre utilisateur de la plateforme afin...
Regular expression Denial of Server (ReDoS)
1. Présentation
Les expressions régulières, également connues sous les termes regular expression, regex ou regexp, sont des motifs de recherche utilisés principalement pour repérer du texte au sein d’un document. De manière simple, il est possible de créer une expression régulière en utilisant directement la chaîne de texte à rechercher. Par exemple, l’expression régulière chat permet de repérer les occurrences du mot chat dans le texte. En programmation, les expressions régulières sont généralement délimitées par certains caractères spécifiques, souvent le slash (/), bien que cela puisse varier. Ainsi le format typique d’une expression régulière serait /chat/.
Toutefois, elles permettent d’effectuer des recherches bien plus complexes grâce à l’ajout de caractères spéciaux. Par exemple, le motif /chat|chien/ permet de rechercher le mot chat ou le mot chien, la barre verticale agissant comme un opérateur d’un OU logique. Bien que cela ne soit pas nécessaire pour un exemple aussi simple, il est possible de modifier cette expression régulière afin de factoriser les caractères communs aux deux mots recherchés, donnant ainsi le motif /ch(at|ien)/. Voici les symboles les plus fréquemment employés :
|
Symbole |
Signification |
|
. |
Correspond à n’importe quel caractère. |
|
* |
(Quantificateur) Correspond à zéro ou plusieurs occurrences du caractère ou groupe précédent. |
|
+ |
(Quantificateur) Correspond à une ou plusieurs occurrences du caractère ou groupe précédent. |
|
? |
(Quantificateur) Correspond à zéro ou une occurrence du caractère ou groupe précédent. |
|
[] |
Définit une classe de caractères, par exemple [a-z] englobe tous les caractères en minuscule de "a" à "z". |
|
() |
Définit un groupe de capture, qui permet de capturer des sous-chaînes (permettant son extraction séparément) ou d’y appliquer des quantificateurs. |
|
(?:) |
Définit un groupe de non capture. Permet d’appliquer des quantificateurs, mais ne permet pas d’en extraire... |
Server-Side Request Forgery
1. Présentation
La vulnérabilité Server-Side Request Forgery (SSRF) est une faiblesse qui permet à un attaquant de forcer le serveur à effectuer des requêtes HTTP vers une destination inattendue et/ou non autorisée. Pour cela, l’attaquant abuse d’une fonctionnalité de l’application qui implique l’utilisation d’une URL, pouvant être manipulée en partie ou en totalité, afin d’en modifier le comportement initial.
Pour illustrer cela de manière simple, il est possible de considérer la possibilité pour un utilisateur de fournir une URL à l’application afin de charger un avatar en tant que photo de profil. Le serveur d’application effectue une requête GET vers l’URL renseignée, récupère l’image et met à jour le profil de l’utilisateur.

Mais que se passe-t-il si un attaquant ne spécifie pas une URL pointant vers une image, mais vers une autre URL ? Et quel est le comportement de l’application si l’URL cible la boucle locale du serveur, ou tout autre équipement présent sur son réseau interne, pouvant même utiliser un protocole autre que HTTP(S) ? Une application permettant ce genre de comportements est sans aucun doute vulnérable aux attaques SSRF.
Les impacts vont dépendre de l’écosystème de l’application, des équipements potentiellement présents sur le réseau interne, des services à l’écoute, etc. Cela peut potentiellement entraîner l’exécution d’actions non autorisées, l’accès à des données sensibles, voire, dans certains cas, l’exécution de commandes arbitraires.
La vulnérabilité SSRF est également appelée Basic SSRF ou Full read SSRF lorsqu’elle permet de récupérer directement la réponse de l’URL manipulée. Dans le cas contraire, elle porte le nom de Blind SSRF, dont l’exploitation est plus difficile.
a. Détection d’une SSRF
La détection d’une vulnérabilité peut ne pas être triviale. La solution la plus évidente est de faire effectuer une requête HTTP vers un point de terminaison contrôlé...
XML External Entity
1. Présentation
L’injection d’entités externes XML (également appelée XXE) est une vulnérabilité qui affecte les applications manipulant des données XML. À l’instar de HTML, XML, pour eXtensible Markup Language, est un langage de balisage conçu pour structurer et décrire des données. À sa création, en 1998, son objectif était de faciliter les échanges entre des systèmes hétérogènes, typiquement des applications web. Son format, représenté sous la forme d’un arbre, a été pensé pour être facilement lisible et manipulable par ses utilisateurs.
Par exemple, l’extrait de code XML ci-dessous présente une collection de livres, où chaque élément livre encapsule des informations telles que l’auteur et le titre, permettant ainsi de représenter ces données de façon structurée.
<?xml version="1.0" encoding="UTF-8"?>
<livres>
<livre>
<auteur>John Doe</auteur>
<titre>La sécurité pour tous</titre>
<edition>LaCyberPourTous</edition>
</livre>
<livre>
<auteur>Jane Doe</auteur>
<titre>Concevoir une application web</titre>
<edition>LaCyberPourTous</edition>
</livre>
</livres> Le langage est dit « extensible », car il permet aux développeurs de définir leurs propres balises.
a. Espace de noms
Les espaces de noms offrent une méthode structurée pour regrouper des ensembles de termes, permettant d’éviter les conflits de noms lorsque plusieurs vocabulaires sont utilisés au sein d’un document. L’exemple suivant illustre cette notion en reprenant l’idée de collection de livres, tout en utilisant un espace de nom dédié aux livres, et un second espace de noms dédié aux auteurs :
<?xml version="1.0" encoding="UTF-8"?>
<bibliotheque xmlns:livres="http://exemple.com/livres" ...Server-Side Template Injection
1. Présentation
La vulnérabilité Server-Side Template Injection (SSTI) est une faiblesse qui se produit lorsque l’application utilise des moteurs de modèles de manière non sécurisée et permet à un utilisateur malveillant d’injecter du code.
Les moteurs de modèles, appelés également moteurs de templates, sont des logiciels, généralement intégrés au sein de frameworks, permettant de générer dynamiquement du contenu, en combinant des modèles associés à des données spécifiques. Ce contenu peut être de type page web, courrier électronique, document PDF, etc. Un modèle est un fichier qui définit, en s’appuyant sur le langage spécifique au moteur de modèles, la structure et le style d’un document. Des emplacements dédiés sont prévus pour l’insertion de données spécifiques, telles que celle provenant d’une base de données, permettant sa personnalisation. Ainsi, lors de la génération d’un document, le moteur de modèles charge le modèle, remplace les espaces réservés par les données adéquates, puis transmet ou affiche le document.
La majorité des moteurs de modèles s’exécutent côté serveur, cela signifie que les données traitées ainsi que la génération des documents sont effectuées par le serveur. Toutefois, certains moteurs de modèles s’exécutent côté client, principalement à l’aide de JavaScript. Il existe un nombre important de moteurs de modèles, dont en voici certains, à titre d’exemple :
|
Moteur de modèles |
Langage |
|
Jinja2 |
Python |
|
Twig |
PHP |
|
Handlebars |
JavaScript/NodeJS |
|
Thymeleaf |
Java |
Pour mieux illustrer le fonctionnement d’un tel mécanisme, voici un exemple d’utilisation du moteur de modèles Jinja2 en Python. Tout d’abord, le modèle utilisé contient deux espaces réservés Jinja2 : {{ nom }} et {{ prenom }} qui seront remplacés par les données fournies lors de son rendu.
modele.html
<!DOCTYPE html> ...Attaque de la chaîne d’approvisionnement (Supply chain attack)
1. Présentation
Les attaques de la chaîne d’approvisionnement visent à atteindre une cible en compromettant la sécurité d’un élément tiers. L’injection de code par une ressource tierce partie, illustrant une des possibles méthodes d’attaques, permet à un attaquant de compromettre l’application web en manipulant les ressources externes qu’elle utilise pour fonctionner. En effet, il n’est pas rare qu’une application utilise des fichiers de scripts JavaScript, ou des feuilles de style externes depuis des serveurs d’un partenaire, ou via l’utilisation d’un réseau de diffusion de contenu (Content Delivery Network, CDN).
Un CDN est un réseau de serveurs géographiquement distribués qui permet d’optimiser la diffusion de contenu web en fournissant des copies des ressources demandées, grâce à un système de cache, au plus proche des utilisateurs, améliorant ainsi le temps de réponse.
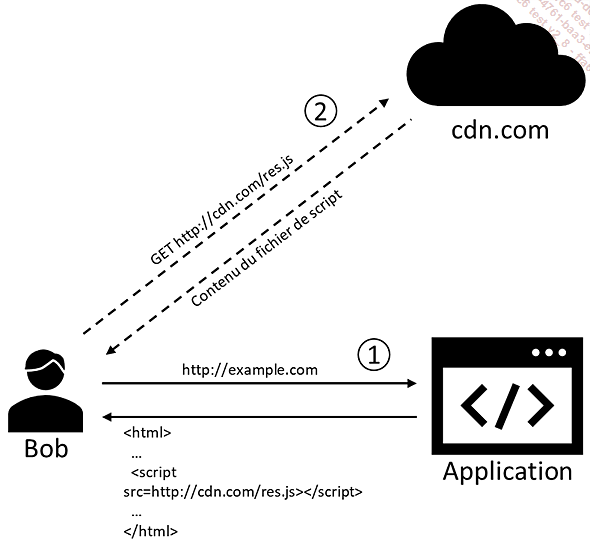
Mais que se passe-t-il si le contenu de la ressource externe est modifié, que cela soit accidentellement, ou de façon malveillante ? Dans ce cas, l’application web cliente (celle utilisant cette ressource) peut se voir impactée. La compromission d’une telle entité tierce peut survenir de diverses manières, motivée par une multitude de raisons. Les impacts sur l’application cliente peuvent être à la fois des dommages collatéraux, résultant d’une attaque plus vaste, ou faire partie d’une campagne spécifiquement ciblée, dont les acteurs malveillants ont choisi de passer par un chemin alternatif. Attaquer une partie tierce plutôt que la cible principale en première instance peut parfois être une approche plus aisée...
Mauvaise configuration de sécurité
1. Présentation
Les problématiques de sécurité liées à de mauvaises configurations, que cela soit du serveur d’application, du serveur de bases de données, des différents frameworks, et de tout autre équipement nécessaire au bon fonctionnement de la plateforme, peuvent entraîner des faiblesses significatives susceptibles d’être exploitées par des acteurs malveillants, compromettant ainsi l’intégrité, la confidentialité et la disponibilité des données.
Les responsables de ces configurations peuvent varier en fonction de la solution utilisée, qu’elle soit physique ou logicielle, mais les développeurs sont en première ligne lorsqu’il s’agit de l’utilisation de frameworks ou de bibliothèques tierces.
Les configurations non sécurisées sont nombreuses et il n’est pas possible de les lister de façon exhaustive. Cependant, voici quelques éléments sur lesquels il est impératif de concentrer une vigilance particulière.
a. Comptes par défaut
Les comptes par défaut sont des comptes utilisateurs, possédant généralement des privilèges importants, présents à l’installation de l’équipement ou du logiciel installé, permettant...