
Comprendre les tenants et aboutissants
Pourquoi cela ne fonctionne pas bien ?
1. Décohérence quantique
Les états quantiques sont extrêmement fragiles et sensibles aux interactions. À un niveau macroscopique, l’opération de mesure qui consiste à déterminer, à un instant donné, l’état d’un système quantique, provoque la destruction de celui-ci. À un niveau microscopique, les interactions entre les différentes particules ou molécules modifient le niveau d’énergie desdites particules et provoquent ainsi des perturbations du système quantique.
Ces états quantiques peuvent être représentés par des particules ou des ondes (cf. chapitre Introduction - section Petite histoire de l’informatique quantique). Cette propriété générale des objets suffisamment petits s’appelle la dualité onde-corpuscule.
À un niveau très petit, les différentes ondes sont bien en phase et réglées les unes par rapport aux autres, elles forment un ensemble cohérent. À cause de menues perturbations, certaines de ces ondes se retrouvent en avance ou en retard, c’est-à-dire déphasées. C’est ce que nous appelons la décohérence quantique. C’est un peu comme deux musiciens bien synchronisés au départ, qui finissent par jouer sur des rythmes différents : l’air mélodieux se transforme alors en cacophonie.
Plus le système est complexe, plus il est difficile de maîtriser ces différentes interactions, et donc de maintenir un système cohérent. Pour reprendre la métaphore musicale : il est plus facile de synchroniser deux musiciens qu’un orchestre au complet.
Les ordinateurs quantiques sont soumis à des bruits différents en fonction de leur architecture. Dans beaucoup de cas cependant, la température joue un rôle dans l’apparition du bruit. Pour les particules qui constituent les ordinateurs quantiques, une température élevée est synonyme d’une certaine activité de leur part (tout comme les activités physiques augmentent la température de notre corps). Sauf dans certains cas, comme pour les photons, l’activité des particules génère...
Enjeux de la recherche
Une approche efficace pour aborder un domaine de recherche consiste à visualiser les liens entre les diverses publications scientifiques. C’est précisément ce que propose la figure 32.
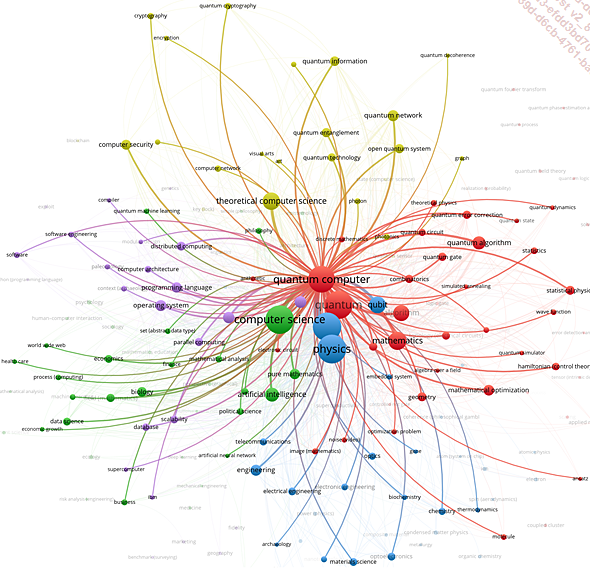
Figure 32
Représentation obtenue avec le logiciel VOSViewer. Le principe est le suivant : nous cherchons, dans une base de données d’articles scientifiques, toutes les publications dont le titre contient « quantum computing ». Les nœuds du graphe représentent les mots-clés les plus fréquents. Les liens entre les nœuds représentent la cooccurrence de ces mots-clés. En lien estompé entre deux nœuds indique que la cooccurrence entre les mots-clés est faible. Les différents niveaux de vue indiquent l’appartenance à des « clusters » différents.
Le logiciel que nous avons utilisé met en avant des clusters ou groupes thématiques dans la recherche sur l’informatique quantique. Nous en identifions cinq :
-
Un large groupe portant sur l’informatique quantique en général. Il reprend des concepts que nous abordons dans ce livre : manipulation des états quantiques, mesures, correction des erreurs, algorithmes et problèmes d’optimisation.
-
Un groupe portant sur l’Internet quantique et la sécurité quantique. Il traite des concepts dont il est question dans l’introduction, tels que la distribution quantique de clés, la blockchain ou encore la cryptographie quantique (comment rendre les infrastructures d’aujourd’hui résistantes aux attaques quantiques).
-
Un groupe portant sur les sciences de l’ingénieur. Il réunit des domaines tels que la science des matériaux, le contrôle industriel ou l’optique, qui sont à la base de l’architecture physique des ordinateurs quantiques. Sont également représentées des sciences comme la biochimie, la chimie ou les télécommunications, qui sont plutôt des domaines d’application.
-
Un groupe de recherche portant sur les applications de l’informatique quantique : mathématiques, intelligence artificielle, biologie, science des données, Web, finance, mais aussi de manière assez surprenante, santé...
Cas pratique : exemple d’application concrète
1. Mise en place
Ce cas pratique porte sur la détection de fraudes aux prêts bancaires. Un algorithme de classification appelé séparateur à vaste marge (SVM) sera utilisé, dans sa version classique puis dans sa version quantique avec Qiskit. Le SVM est un algorithme dit supervisé. Dans un premier temps, il s’agit de fournir à l’algorithme un ensemble de prêts bancaires dont la nature (illicite ou pas) est connue. Cela permet à l’algorithme d’apprendre à différencier les prêts frauduleux, des prêts non frauduleux. Dans un second temps, des prêts inconnus sont soumis à l’algorithme pour qu’il les étiquette.
Vous utiliserez à nouveau Jupyter Notebook, installable en local avec Qiskit. Nous vous conseillons également d’utiliser la plateforme en ligne IBM Quantum Lab (cf. chapitre Comprendre l’informatique quantique - section Cas pratique : exécuter un programme quantique).
Vous pouvez dès à présent créer le notebook tp_classification, sur lequel vous travaillerez.
Si vous choisissez d’utiliser Jupyter Notebook sur votre ordinateur, il faut également installer les librairies suivantes :
pip install ydata_profiling
pip install qiskit-aer
pip install qiskit-machine-learning
pip install qiskit-ibm-provider
pip install sklearn
pip install imblearn
pip install seaborn Si vous choisissez d’utiliser la plateforme IBM Quantum Lab, seules les librairies ydata_profiling et imblearn sont nécessaires. ydata_profiling génère un rapport sur le jeu de données, qui permet d’évaluer la qualité desdites données. imblearn permet de faire de l’apprentissage automatisé sur des données dites non balancées. C’est par exemple le cas lorsque sont détectés plus de cas de non-fraude que de cas de fraude.
Vous pouvez installer ces deux librairies depuis le notebook avec les instructions suivantes :
!pip install ydata_profiling
!pip install imblearn Une fois les dépendances installées, vous pouvez réaliser les imports requis pour l’expérience :
import pandas as pd
from ydata_profiling import...