
La gouvernance des données
Introduction
Dans les chapitres précédents, nous avons étudié les différentes facettes de la donnée, puis montré comment stocker mais aussi comment transporter et transformer ces données dans le système d’information. Nous avons ensuite appris comment analyser et nettoyer nos données.
Mais, les données sont aussi une matière mouvante, elles bougent, changent et évoluent. Ces données ont pour vocation de devenir rapidement des informations et ainsi fournir la véritable richesse attendue par l’entreprise. Il devient donc indispensable de mettre en place des règles de gouvernance sur ces données afin de gérer et mieux contrôler la vie de ces informations qui deviendront l’énergie brute de l’entreprise.
De la même façon, nous avons vu dans le premier chapitre que la donnée était polymorphe et vivante, il en est de même pour la gouvernance. Cette dernière a en effet ses propres règles. La gouvernance des données est en quelque sorte la loi qui régit les données, et pour réguler ces données il est donc indispensable de créer une police des données. C’est ce que nous allons aborder dans ce chapitre : les moyens et les contrôles nécessaires à mettre en œuvre pour une bonne maîtrise de ces informations.
D’un point de vue gouvernance des données, il faut distinguer plusieurs facettes :
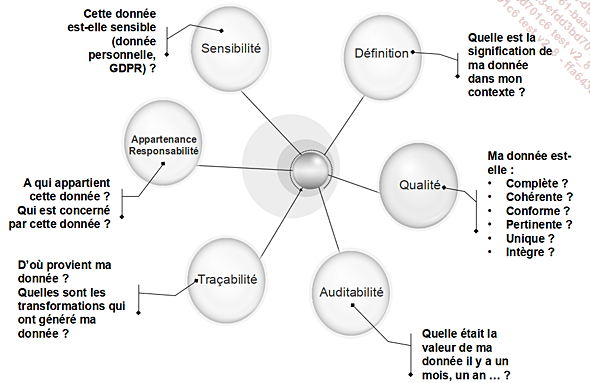
Les facettes de la gouvernance de données
À ces facettes, on doit ajouter des exigences de plus en plus fortes des consommateurs de données telles que :
-
l’exactitude...
L’équipe de gouvernance de données
Avant d’aborder les différents types d’outils nécessaires à la mise en place d’une bonne gouvernance, il paraît indispensable de décrire rapidement les rôles et missions de nos intervenants dans la gouvernance de données. Voici donc de manière succincte ces différents rôles :
-
Le CDO (Chief Data Officer) : à ne pas confondre avec le Chief Digital Officer ! Le CDO a pour rôle de porter la stratégie de l’entreprise autour de la donnée. Naturellement, la gouvernance est l’une de ses principales préoccupations car il doit garantir que les données sont définies, de confiance et utilisables à tout moment par les utilisateurs.
-
Le Data Steward : ce rôle est quelque part né avec la gouvernance de données. C’est un rôle assez complexe car les Data Steward sont des collaborateurs qui vont devoir gérer et garantir l’intégrité les données. Ils vont devoir ainsi s’assurer de leur collecte jusqu’à la mise à disposition en passant par la documentation. C’est un rôle central car, au passage, ils seront garants de la qualité des informations fournies. La question se pose souvent d’ailleurs quant aux compétences nécessaires pour un tel rôle. Avant tout métier, ces Data Steward ne sont pas des experts techniques mais ils doivent néanmoins connaître globalement les concepts, architectures et outils techniques qui sont utilisés.
-
Le Data Owner : chaque donnée et/ou métadonnée...
Les métadonnées
Qu’est-ce qu’une métadonnée ? Par définition, une métadonnée est une information qualificative d’une donnée. Certes, cette définition est un peu vague. Voyez une métadonnée comme une façon de définir ou même de décrire une information. Rappelons ici que les données ont plusieurs facettes et que, selon la personne qui consomme la donnée, celle-ci pourra avoir une signification différente. Les métadonnées ont aussi pour but de lever les ambiguïtés sur la réelle teneur des données. C’est en quelque sorte un étiquetage indispensable qui permet de qualifier sans doute l’information qui est stockée et gérée par l’entreprise. Pour reprendre la métaphore de l’étiquette : la métadonnée est à la donnée ce que l’étiquette est au produit.
Définir le socle de métadonnées, c’est aussi avoir une double approche, à la fois technique et fonctionnelle. En effet, l’étiquetage des données peut être abordé sous le prisme technique (stockage, nom de table, nom de colonne, type technique, etc.) mais aussi d’un point de vue sémantique et métier (numéro de facture, nomenclature à respecter, etc.). Bien sûr, l’intérêt dans une démarche de type métadonnée est de réconcilier ces deux visions complémentaires de la même donnée.
1. Les enjeux autour de la gestion des métadonnées
Définir...
Le lignage des données
1. Introduction
Le lignage de données (ou Data Lineage) est la capacité d’un outil ou d’une solution à pouvoir retracer toutes les étapes de déplacement et de transformation des données. Imaginez que vous ayez un indicateur dans l’un de vos tableaux de bord et que vous ne sachiez pas exactement d’où cette information provient. Le Data Lineage va permettre de retracer toutes les étapes de récupération des données source ainsi que les différentes transformations qui ont été nécessaires afin de produire cet indicateur. Ce type de solution peut s’avérer particulièrement utile lors de l’analyse d’impact mais il permet aussi et surtout de mieux comprendre la donnée dans son environnement.
2. Les couches de lignage
Le lignage de données permet donc de rendre compréhensible la provenance de nos données mais aussi comment ces dernières sont utilisées dans les diverses applications et systèmes.
En général, on distingue deux types de métadonnées que la solution de lignage va devoir récupérer :
-
Les informations physiques : on incorpore ici les éléments techniques du Système d’information tels que les bases de données, les fichiers, les solutions, programmes, etc. En général, c’est le socle le plus robuste de notre lignage car ses éléments sont factuels. On y retrouve donc :
-
Les systèmes (bases de données, applications, etc.)
-
Les DataSets ou Tables qui sont en fait les données...
Le catalogue de métadonnées
La solution fournissant le catalogue de données extrait les métadonnées provenant de diverses sources externes (bases de données, data Warehouse, glossaires d’entreprise, rapports de BI, etc.) afin de les rendre accessibles au sein d’une interface consolidée et dédiée aux Data Stewards.
Ce type de solution aide à analyser et comprendre les grandes quantités de métadonnées présente dans les différents domaines de votre Système d’information. Il est donc possible :
-
d’y extraire des métadonnées physiques et opérationnelles pour de nombreux composants liés à des données ;
-
d’organiser les métadonnées sur la base de concepts métier ;
-
d’afficher les informations de lignage de données et de relation pour chaque donnée
|
L’objectif de ce type de solution est de maintenir un catalogue qui sert de référentiel centralisé, stockant ainsi toutes les métadonnées provenant de différentes sources externes. |
Très souvent, ce type de solution s’accompagne d’un moteur de découverte qui permet de recueillir les données au sein de l’entreprise tout en augmentant leur compréhension grâce à un catalogue d’informations préchargé. Il devient alors beaucoup plus simple pour tout type d’utilisateur de :
-
rechercher tous les types de données au sein de l’entreprise ;
-
découvrir les relations ;
-
enrichir les données avec un glossaire métier et les annotations...
La sécurité des données
La sécurité des données est devenue depuis quelques années un domaine extrêmement prolifique et pourrait d’ailleurs faire l’objet d’un (ou plusieurs) livres entiers tellement il y a à dire et à faire sur le sujet. Bien sûr le RGPD (Règlement Général sur la Protection des Données) a accéléré bon nombre d’initiatives. Finalement, c’est une excellente chose car cela a permis de poser enfin les bases de la sensibilité des données et bien sûr des devoirs en matière de gestion et sécurité pour ceux qui les stockent.
L’objectif ici n’est pas de couvrir de manière exhaustive ce sujet, mais plutôt de parcourir les grands concepts autour de la sécurité des données. Comment protéger les données stockées ? Comment les rendre accessibles tout les sécurisant via l’anonymisation, la pseudonymisation ou même le cryptage ? Voici les sujets qui seront développés dans cette section.
1. Anonymisation vs Pseudonymisation

Extrait du RGPD
Dans le cadre de la réglementation RGPD (ou GDPR en anglais) et plus particulièrement de la thématique spécifique autour de la sécurisation des données à caractère personnel, une première approche proposée consiste - cf. article ci-dessus - à pseudonymiser de manière définitive les données personnelles.
|
Mais qu’est-ce que la pseudonymisation, quelle différence avec l’anonymisation ? |
L’anonymisation et la pseudonymisation...
La fabrique de données (Data Fabric)
Une fabrique de données - ou Data Fabric - est un concept d’architecture de données apparu dans les années 2000 et formalisé par l’institut Forrester. La fabrique de données est en fait un assemblage d’outils et de pratiques permettant de mettre à disposition des données fraîches et de qualité. Les fabriques de données sont fondées sur le principe de réalisation d’un « tissu de données » cohérent et qui pourra directement être utilisé par divers utilisateurs ou consommateurs. Sans ce modèle, chaque entité des entreprises doit se construire son jeu de données, le documenter et le gérer. Cette démarche montre dans bien des cas ses limites. Les types de sources de données, les volumes et tous les besoins en matière de données fraîches sont aussi en constante augmentation. Il devient de plus en plus complexe et coûteux de bien gérer son parc de données.
D’où l’idée de mutualiser tous ces efforts - auparavant éparpillés - en les regroupant dans une même entité qui aura pour rôle de fournir des données utilisables. La fabrique de données est née.
Bien sûr, cette fabrique ne peut fonctionner sans outils adéquats. Elle a besoin pour fonctionner de mettre en oeuvre une ou plusieurs solutions qui lui permettront :
-
d’Acquérir des données permettant de se connecter à tout type de système afin d’y récupérer tout type de données nécessaires...
Le maillage de données (Data Mesh)
C’est un fait, la quantité de données ne cesse d’augmenter et de manière proportionnelle aux besoins d’ailleurs. Malgré la création de Data Lake qui ne cessent de grossir et de se complexifier, on voit se proliférer de multiples petits îlots de données - parfois non sous gouvernance. Tout cela est complexe à gérer et maîtriser et peut vite se transformer en chaos. Si l’approche fabrique de données peut remédier à certains problèmes et proposer une meilleure fluidité dans la consommation des données, elle peut s’avérer vite dépassée tant les données et les solutions s’accumulent et se complexifient. D’où l’introduction d’un nouveau type d’architecture de données proposé en 2019 par Zhamak Dehghani.
Ce type d’architecture repose sur quatre piliers :
1. La création et la gestion d’un domaine de données.
2. Le principe de Data as a Product (donnée en tant que produit).
3. Le principe de Self-Service.
4. La gouvernance fédérée.
Dit plus simplement…
|
Un peu à l’image des microservices qui ont permis de segmenter les applications par domaine et non plus par technologies, le Data Mesh (ou maillage de données) se propose de découper la gestion des données par domaine. |
L’idée sous-jacente est en fait très pragmatique. Partant du constat qu’il est très complexe de faire cohabiter Data Warehouse et Data Lake, et que d’autre part les lignes de chargement de ces derniers (très souvent...



