
La persistance
Introduction
Il est fréquent de voir dans les articles de presse la métaphore qui dépeint la donnée en carburant. C’est une métaphore intéressante, certes, mais qui porte surtout sur la nécessité de transformer une énergie brute - comme le pétrole - vers une énergie utilisable comme un carburant de voiture par exemple. Il est une autre caractéristique de la donnée qui est tout aussi importante. Cette dernière est liée à la volatilité de la plupart de nos données : le stockage. En cela, la métaphore d’électricité est sans doute plus adéquate, finalement. En effet, la volatilité mais aussi les limitations (comme celles induites par le Big Data) imposées par le stockage de nos données dans certaines conditions amènent à concevoir des solutions qui doivent s’adapter sans cesse et à tout type de besoin.
Le stockage (ou la persistance) des données est donc une composante importante, voire vitale, dans la gestion des données. Quel que soit le profil (expert, analyste ou simple consommateur des informations), il est en effet indispensable de pouvoir accéder aux données. Or qui dit accès aux données dit aussi connaissance du mode de stockage sous-jacent. On verra dans ce chapitre les différents modes de stockage et la façon dont ces derniers influent sur les modalités d’accès ou d’utilisation des données.
Le premier type de support auquel on pense immédiatement est bien sûr le fichier, ou du moins un ensemble de fichiers. Mais dès lors que les aspects partage...
Fichiers
De la même manière que le bit est l’unité primaire d’encodage de la donnée, le fichier est en quelque sorte l’unité primaire de stockage d’un ensemble de données sur un support. En effet, que ce soient les bases de données, les entrepôts de données (Data Warehouse) ou les lacs de données (Data Lake), tous fonctionnent avec des fichiers. Mais fermons la parenthèse ici et parlons de fichier comme une unité de stockage sur un support.
|
Qu’est-ce qu’un fichier ? Un fichier est un ensemble de données stocké et encodé de manière structurée sur un support (physique si c’est un disque dur). Un fichier est identifié par un nom et, par convention (car c’est facultatif), peut avoir une extension. |
Les fichiers sont gérés et organisés par le système d’exploitation via le système de fichiers (File System) qui peut lui aussi être de plusieurs natures (NTFS, FAT, FAT32, ext2fs, ext3fs, ext4fs, zfs, etc.). Ils ne sont, en fin de compte, qu’un ensemble de données reliées de manière logique afin de pouvoir être stockées de manière physique sur un support.
À noter aussi :
-
Il est possible de stocker plusieurs fichiers dans un seul fichier via des formats de stockage tels que Zip, Tar, etc.
-
Il est possible d’exécuter des fichiers (exécutables) directement dans le système d’exploitation, si ces derniers ne stockent pas à proprement dit de données.
-
Un fichier est attaché à un type de format (structure) qui permet d’identifier...
Les bases de données
Comment écrire un guide sur la donnée sans aborder les bases de données ? Une base de données permet de stocker et organiser un ensemble de données ou informations dans un même endroit (pas nécessairement physique).
Aujourd’hui, il existe de nombreuses bases de données. Bien sûr lorsque l’on parle de base de données, on pense immédiatement à Oracle, Microsoft SQL Server, IBM DB2, etc. Pour faire simple, les premières qui nous viennent à l’esprit sont les bases de données "historiques" dites relationnelles que l’on nomme SGBD-R (Systèmes de Gestion de Base de Données Relationnelles).
Depuis quelques années, avec la quantité grandissante des données à stocker (Big Data) et la diversité des usages, il était devenu impératif de repenser la manière de gérer les données. De nouvelles formes de bases de données sont alors apparues, permettant de combler les lacunes des bonnes vieilles bases de données relationnelles. On verra notamment dans ce chapitre les bases NoSQL qui proposent de nouvelles perspectives dans le stockage de données non structurées.
Avant tout, il est important de parcourir les grandes familles de bases de données.
1. Familles de bases de données
On distingue plusieurs grandes familles de bases de données :
-
Les bases de données relationnelles (SGBD-R). Ce sont les plus utilisées et nous y reviendrons plus en détail dans la section suivante.
-
Les bases de données hiérarchiques. Comme son nom l’indique...
Les bases de données relationnelles (SGBD-R)
1. Le langage SQL
Le langage SQL (Structured Query Language) est le langage normalisé d’interrogation et de mise à jour des données dans une base de données relationnelle. Sa première version date de 1970 (IBM), et l’on peut dire que ce langage est devenu la référence en matière d’accès aux données. À tel point que même les autres types de bases de données (NoSQL par exemple) s’en inspirent et surtout cherchent à proposer un mode d’interrogation qui se rapproche au maximum du SQL.
Il est malheureusement impossible d’aborder le SQL sans passer en revue les grands concepts ensemblistes inhérents à ce langage d’interrogation de données. Le SQL est basé sur ce que l’on appelle des requêtes. Une requête est en quelque sorte une instruction envoyée à la base de données qui permet à l’utilisateur de l’interroger ou de communiquer avec.
Attention car le langage SQL a beaucoup évolué et changé depuis sa création. Parfois ces changements sont dans les détails, parfois même ils diffèrent selon les SGBD-R. Sachez qu’officiellement, plusieurs normes ont vu le jour (SQL-1, SQL-2, etc.) et apportent aussi des différences notables.
Le langage SQL comporte trois grandes typologies d’instructions :
-
Le LMD (Langage de Manipulation de Données) qui permet d’interroger les données. Ce langage permet d’agir directement sur les données stockées.
-
Le LDD ou DDL (Langage de Définition...
Les systèmes OLTP et OLAP
Impossible ici de ne pas évoquer les systèmes OLTP (OnLine Transaction Processing). Ce type de système de gestion de données est en effet capable de prendre en charge les applications orientées transactions (saisie des commandes, transactions financières, gestion de la relation client (CRM) et ventes au détail).
On parle de systèmes opérationnels.
Ces systèmes sont conçus pour gérer des données opérationnelles via des transactions et ont souvent comme caractéristiques :
-
La gestion de petits ensembles de données.
-
L’indexation de l’accès aux données.
-
Un grand nombre d’utilisateurs/requêtes.
-
Beaucoup de requêtes (CRUD).
-
Une exigence en matière de temps de réponse.
-
De grands volumes de données.
Ce type de système est souvent en opposition avec un traitement de type OLAP (Décisionnel/OnLine Analytical Processing) : ce dernier impliquant par exemple d’interroger de nombreux enregistrements (parfois même tous les enregistrements) dans une base de données à des fins analytiques.
D’ailleurs, si la même base de données peut proposer ces deux types d’utilisations, la modélisation, elle, se doit d’être différente :
-
OLTP -> Modélisation relationnelle
-
OLAP -> Modélisation étoile
Système distribué et théorème CAP
Ce théorème CAP vient du constat (démontré de manière empirique) qu’Éric Brower a posé et qui confirme qu’à un instant donné il est impossible pour un système de gestion de données qui fonctionne comme un cluster (fonctionnement distribué) de respecter les trois contraintes suivantes :
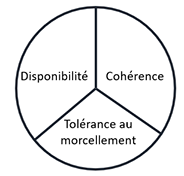
Critères CAP
-
Cohérence : ce critère certifie que tous les éléments constitutifs du système de gestion de données contiennent exactement les mêmes données au même moment.
-
Disponibilité : c’est un critère simple qui permet d’assurer que toute requête doit recevoir une réponse.
-
Tolérance au morcellement : dans un système fonctionnant avec plusieurs nœuds (cluster), ce critère impose que les données, si elles sont morcelées (éparpillées sur plusieurs nœuds), doivent pouvoir être reconstituées à tout moment, et ce même en cas de panne d’un des éléments/nœuds.
Les études d’Éric Bower ont aussi montré qu’il est possible de respecter deux contraintes au maximum (à un instant donné) mais jamais les trois. Cela impose donc certains compromis.
|
CAP est l’acronyme de : Consistency, Availability and Partition tolerance. |
Ce théorème aura des impacts sur les typologies de bases de données orientées cluster que nous allons voir par la suite. Ce théorème influence particulièrement l’architecture...
Les bases NoSQL
Au cours des années 2010, et face à une boulimie inéluctable de données mais aussi à cause de la diversité des structures de données à exploiter, les bases de données atteignent, dans certains cas, très vite leurs limites. Un nouveau paradigme qui va redistribuer les critères CAP tout en regroupant plusieurs initiatives autour de la donnée va naître de cette déviance. Il faut donc faire certains choix et en effet proposer des solutions permettant de répondre à la demande de disponibilité, et ce au détriment du maintien de la cohérence (cf. Théorème CAP). Les bases de données dites NoSQL (comme Not Only SQL - pas seulement SQL) font alors leur apparition.
Ces nouveaux systèmes de gestion de données remettent alors en cause certains concepts et principes bien établis jusque là des bases de données traditionnelles tels que les propriétés ACID. Tout cela dans un but précis : gérer de grands (très grands) volumes de données, de tout type.
Ce courant NoSQL, contrairement à certaines idées reçues, ne s’affirme pas en opposition avec les bases de données relationnelles. Au contraire, il vient combler les lacunes de ces derniers dans les deux autres volets du théorème CAP (tolérance au morcellement et disponibilité), cela bien sûr au détriment de la cohérence.
Voici quelques exemples d’implémentations NoSQL :
-
Apache Cassandra (Colonne)
-
MongoDB (Document)
-
AWS Dynamo, Azure Cosmos DB (Clé-valeur)
-
Apache HBase (Colonne)...
Le Big Data
La réelle limite des bases de données traditionnelles est sans aucun doute la gestion de très grosses quantités de données. À titre d’exemple, certains analystes n’hésitent pas à affirmer qu’environ 2,5 trillions d’octets de données sont produits par jour. C’est considérable et ce type de chiffre ne cesse de fluctuer à la hausse. Au cours des années 2000, des entreprises telles que Facebook ou Google ont dû se confronter à ce problème de Big Data afin de pouvoir proposer plus de services avec davantage de données à gérer. Il a alors fallu penser à d’autres modes de gestion de données et proposer une alternative à nos fameuses bases de données relationnelles (SGBD-R). Mais, avant tout, il était important de positionner les priorités de ce que le nouveau type de système de stockage devait proposer.
À la genèse du Big Data on trouve donc les 3 V.
1. Les 3 V
La notion de Big Data pose ses fondamentaux sur la base des 3 V (concept introduit par Doug Laney en 2001) : volume, variété et vélocité. Cette règle a, dès le début d’Hadoop, été la loi que devraient suivre les systèmes dits Big Data. Mais que veulent dire ces 3 V ?
-
V comme volume. Cela peut paraître évident quand on parle de Big Data mais bien sûr la qualité première d’un système Big Data est d’être capable de gérer une très grande quantité de données. Cette quantité de données...
Les tendances actuelles
1. Bases de données dans le Cloud (Database as a Service : DBaaS)
Aujourd’hui il est possible d’utiliser les bases de données au travers de fournisseurs externes via des services Cloud. C’est ce que l’on appelle le DBaaS (DataBase as a Service).
Les avantages de ce type d’utilisation sont évidemment très liés à l’exploitation de la solution :
-
Aucune installation ni maintenance logicielle/matérielle (On-Premise) n’est nécessaire.
-
La gestion des ressources (besoin d’espaces, puissance) est plus souple et adaptative. Le gain en flexibilité est notoire car le service est fourni par des Data Center à haut niveau de performance.
-
Le monitoring, l’administration et la surveillance des bases de données sont automatisés par le fournisseur.
-
Des experts dédiés par le fournisseur garantissent la sécurité.
-
Le reporting est automatique et exhaustif.
Les inconvénients potentiels :
-
Les données sont stockées en dehors de l’entreprise.
-
Dans le cas de données confidentielles ou personnelles (RGPD) cela peut poser des interrogations voire des problèmes selon la localisation du data center.
-
Selon les contrats de services proposés, les data centers peuvent être indisponibles temporairement (maintenance, etc.).
Aujourd’hui, il y a pléthore de fournisseurs DbaaS, on y trouve plusieurs types d’acteurs :
-
Les éditeurs de solutions de bases de données eux-mêmes qui proposent leurs services via le cloud (Snowflake).
-
Les grandes plateformes Cloud (Google, AWS, Azure, etc.).
-
Des acteurs du cloud tels...



