
Réplication
Présentation
La réplication est une puissante fonctionnalité de SQL Server qui permet de distribuer les données et d’exécuter les procédures stockées sur plusieurs serveurs de l’entreprise. La technologie de réplication a considérablement évolué et permet maintenant de copier, de déplacer les données à différents endroits et de synchroniser automatiquement les données. La réplication peut être mise en œuvre entre des bases de données résidant sur le même serveur ou sur des serveurs différents. Les serveurs peuvent être sur un réseau local (LAN), réseau global (WAN) ou sur Internet.
SQL Server distingue deux grandes catégories de réplication :
-
La réplication de serveur à serveur.
-
La réplication de serveur à clients.
Dans le cas de la réplication de serveur à serveur, la réplication permet une meilleure intégration ou rapprochement des données entre plusieurs serveurs de base de données. L’objectif de ce type de réplication est d’effectuer un échange d’informations entre des serveurs de base de données. Les utilisateurs qui travaillent sur les bases qui participent à la réplication peuvent ainsi consulter des données de meilleure qualité.
La réplication de serveur à clients concerne principalement les utilisateurs déconnectés du réseau de l’entreprise et qui souhaitent travailler avec tout ou partie des données de l’entreprise. Les utilisateurs travaillent avec une application spécifique et utilisent SQL Server comme serveur de base de données local. Lorsqu’ils se connectent sur le réseau, la synchronisation des données entre leur poste...
Les besoins pour la réplication
La réplication est une technologie complexe et il ne peut exister une solution unique pour couvrir tous les besoins. SQL Server propose différentes technologies de réplication qu’il est possible d’adapter et de combiner pour répondre le plus exactement possible aux besoins des applications. Chaque technologie présente ses avantages et ses inconvénients. Voici les trois critères principaux pour sélectionner une technologie de réplication :
-
La cohérence des données répliquées.
-
L’autonomie des sites.
-
Le partitionnement des données pour éviter les conflits.
Il n’est pas possible d’optimiser les trois critères simultanément. Ainsi, une solution qui favorisera la cohérence des données devra laisser une faible autonomie aux sites afin de connaître à chaque instant l’ensemble des modifications qui ont lieu sur les données.
1. Cohérence des données répliquées
Il existe deux principaux types de cohérence :
-
L’homogénéité des transactions.
-
La convergence des données.
La cohérence des opérations distribuées telle que la réplication est beaucoup plus difficile à maintenir comparée à la cohérence des transactions locales dont il suffit de respecter le test ACID (Atomicité, Cohérence, Isolement et Durabilité).
L’homogénéité des transactions dans la réplication impose que les données soient identiques sur tous les sites participant à la réplication, comme si la transaction avait été exécutée sur tous les sites.
La convergence des données quant à elle signifie que tous les sites participant aux réplications tendent...
Les modèles de réplication
Dans SQL Server, les différents modèles de réplication utilisent la métaphore "éditeur-abonné" afin de concevoir au mieux les modèles de réplication.
1. Les principaux composants
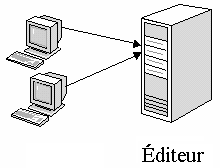
a. L’éditeur
Comme un éditeur de livres ou de journaux, un serveur éditeur met à la disposition des autres serveurs des données pour mettre en œuvre la réplication.
L’éditeur conserve toute les données publiées (celles qui participent à la réplication) et tient à jour les modifications intervenues sur ces données. Pour les données publiées, l’éditeur est toujours unique.
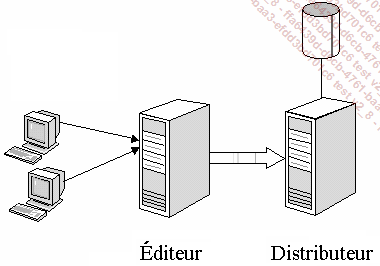
b. Le distributeur
Il s’agit du serveur SQL qui contient la base de distribution, c’est-à-dire celle qui contient toutes les informations utilisées par les abonnés pour tenir à jour les données qu’ils contiennent.
Ces deux rôles peuvent être tenus par la même machine.
c. Les abonnés
Ce sont les serveurs SQL qui stockent une copie des informations publiées puis reçoivent les mises à jour de ces données. Il est possible de modifier les données publiées sur l’abonné. Un abonné peut devenir éditeur pour d’autres abonnés.
Comme pour un magazine, les abonnés doivent passer des abonnements pour recevoir des données publiées. Il existe deux types d’abonnement :
Abonnement envoyé
Dans un tel cas, c’est le distributeur qui se charge d’envoyer la mise à jour des données distribuées à tous les abonnés. Ce type d’abonnement est particulièrement bien adapté lorsque le temps de mise à jour des abonnés doit être...
Planification
La mise en place de la réplication nécessite une planification rigoureuse des tâches à mener afin d’utiliser au mieux les ressources fournies par SQL Server tout en réduisant les ressources matérielles (temps UC, réseau) utilisées par la réplication.
1. Options générales de planification
a. Option NOT FOR REPLICATION
L’option NOT FOR REPLICATION permet de définir un comportement différent des options lorsque le traitement est fait dans le cadre de la réplication. Cette option est positionnable sur :
-
Les colonnes de types identity.
-
Les contraintes de validation (CHECK).
-
Les contraintes de clé étrangère (FOREIGN KEY).
-
Les déclencheurs de base de données.
b. Type de données uniqueidentifier
Le type de données uniqueidentifier est utilisé avec la fonction NEWID() qui permet de générer un nouvel ID pour chaque appel de la fonction.
Avantages du GUID :
-
Le GUID est toujours unique et ainsi de nombreux conflits sont évités.
Cependant, cette option n’est pas intéressante lorsque les utilisateurs ne voient pas ou n’utilisent pas les valeurs du GUID. En effet les valeurs de type uniqueidentifier présentent des inconvénients qu’il ne faut pas négliger lors de la mise en place d’une application.
-
La manipulation par un utilisateur est difficile (format trop long).
-
Les valeurs sont aléatoires et ne possèdent aucune signification.
-
Les valeurs uniqueidentifier ne sont pas nécessairement disponibles pour les applications existantes qui sont construites à partir de valeurs d’identificateurs incrémentielles.
En résumé, il est possible de préciser que les valeurs de type uniqueidentifier sont bien adaptées lorsqu’elles sont utilisées directement...
L’accès au réseau
Afin que le processus de réplication se déroule sans encombre, certaines conditions élémentaires doivent être satisfaites sur l’accès au réseau :
-
Si les serveurs SQL participant à la réplication se situent dans des domaines différents, des relations d’approbation doivent être établies entre ces domaines.
-
L’agent SQL Server doit s’exécuter dans le contexte d’un compte d’utilisateur du domaine. Si possible, l’agent SQL Server des différents serveurs SQL participant à la réplication utilise toujours le même compte d’utilisateur. Ce compte d’utilisateur du domaine doit être membre du groupe local Administrateurs afin de faire profiter des privilèges administratifs au service SQLServerAgent.
La configuration des comptes de service est expliquée au chapitre sur l’installation et la configuration de SQL Server.
Mise en œuvre
Quels que soient le modèle et le type de réplication choisis, la mise en œuvre doit toujours respecter les mêmes étapes :
-
La mise en œuvre du distributeur.
-
La mise en œuvre de l’éditeur.
-
La mise en œuvre des abonnés.
-
La définition des publications.
Comme SQL Server considère par défaut que l’éditeur et le distributeur résident sur le même serveur, l’installation de ces deux états est confondue.
Pour pouvoir mettre en œuvre la réplication à partir de SQL Server Management Studio, tous les serveurs SQL qui y participent doivent y être inscrits.
SQL Server Management Studio propose différents assistants graphiques pour mettre en place, surveiller et paramétrer l’environnement de réplication. Tous ces éléments sont accessibles depuis le nœud Réplication de l’explorateur d’objets de SQL Server Management Studio.
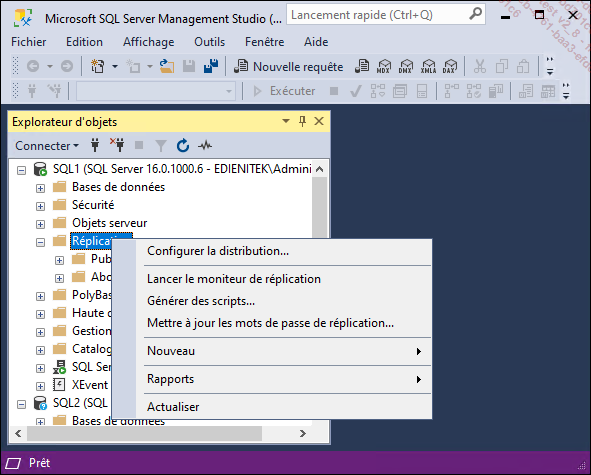
1. Le distributeur
Il s’agit du poste qui va gérer le répertoire partagé pour la capture instantanée ainsi que la base de distribution. Le distributeur stocke les modifications effectuées sur les données puis les transmet aux abonnés.
a. Concepts
Le distributeur doit être installé avant de mettre en place les éditeurs qui l’utilisent. Pour créer un distributeur, il faut être administrateur du système (membre du groupe local Administrateurs et par le biais des connexions approuvées se connecter à SQL Server en tant qu’administrateur). Lorsque le distributeur est installé, il est possible de connaître ses propriétés locales et distantes.
La base de données de distribution
Elle contient toutes les transactions qui sont en attente d’envoi vers les abonnés....

