
Gestion de la base de données
Notions générales
L’installation du serveur SQL réalisée, il convient de définir des espaces logiques de stockage afin de regrouper sous un même nom l’ensemble des données correspondant à un même projet. Cet ensemble est la base de données, elle va nous permettre de travailler logiquement avec des objets tels que les tables sans jamais avoir à se soucier du stockage physique. SQL Server permet de réaliser des associations entre les fichiers physiques et les bases de données. Dans ce chapitre, la création et la gestion des fichiers physiques seront abordées en même temps que les bases de données.
1. Liens entre base de données et organisation physique
Lors de la création d’une base de données, il est nécessaire de préciser au moins deux fichiers. Le premier servira à stocker les données, le deuxième sera utilisé par le journal des transactions afin de stocker les informations nécessaires à la gestion des transactions lors des modifications sur les données.
Ces deux fichiers sont obligatoires et sont propres à chaque base. Dans SQL Server, il n’est pas possible de partager un fichier de données ou le journal entre plusieurs bases.
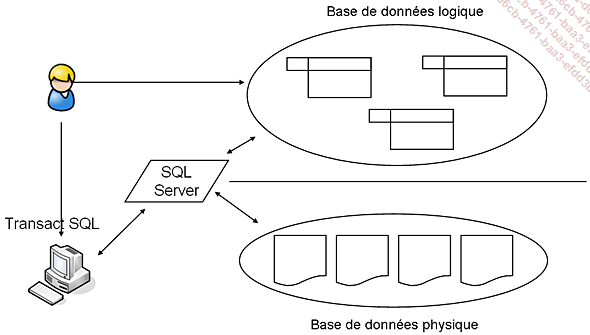
Séparation entre les schémas logique et physique
2. La notion de transaction
a. Qu’est-ce qu’une transaction ?
Une transaction est un ensemble indivisible d’ordres Transact SQL. Soit la totalité peut s’exécuter, soit aucun ordre ne peut s’exécuter. Le moteur SQL doit être capable, tant que la transaction n’est pas terminée, de remettre les données dans l’état initial. Durant toute l’exécution de la transaction, des verrous sont positionnés sur les données afin d’empêcher...
Création, gestion et suppression d’une base de données
Une base de données gère un ensemble de tables système et des tables utilisateurs. Les informations contenues dans ces tables système représentent, entre autres, la définition des vues, des index, des procédures, des fonctions, des utilisateurs et des privilèges. Les tables utilisateurs vont contenir les informations saisies par les utilisateurs.
Une instance SQL Server ne peut pas contenir plus de 32 767 bases de données.
1. Créer une base de données
La création d’une base de données est une étape ponctuelle, réalisée par un administrateur SQL Server. Avant de tenter de créer une base de données, il est important de définir un certain nombre d’éléments de façon précise :
-
Le nom de la base de données qui doit être unique sur le serveur SQL.
-
La taille de la base de données.
-
Les fichiers utilisés pour le stockage des données.
Pour créer une nouvelle base de données, SQL Server s’appuie sur la base Model. Cette base Model contient tous les éléments qui vont être définis dans les bases utilisateurs. Par défaut, cette base Model contient les tables système. Il est cependant tout à fait possible d’ajouter des éléments dans cette base. Toutes les bases utilisateurs créées par la suite disposeront de ces éléments supplémentaires.
Une base peut être créée de deux façons différentes :
-
Par l’intermédiaire de l’instruction Transact SQL CREATE DATABASE.
-
Par l’intermédiaire de SQL Server Management Studio.
Une base de données est toujours composée au minimum d’un fichier de données...
Mise en place de groupes de fichiers
Il est possible de préciser les fichiers de données utilisés par la base, mais il est malheureusement impossible de préciser sur quel fichier est créé un objet particulier. Pour résoudre ce problème, il existe la possibilité de créer une table ou un index sur un ensemble de fichiers. Cet ensemble de fichiers, également appelé groupe de fichiers, est géré assez simplement.
Pourquoi est-il nécessaire de travailler avec plusieurs groupes de fichiers ? Parce qu’il est normal sur un système d’exploitation de séparer les fichiers système des programmes et des données utilisateur ; pourquoi en serait-il autrement dans une base de données ? Il convient donc de regrouper sur un même groupe de fichiers des données de même type. Par exemple, les données stables (comme les clients, les articles) peuvent être distinguées des données de type historique tout simplement parce que les volumes ne sont pas les mêmes, la façon de travailler avec non plus. Il peut être également intéressant de définir les index et les tables sur des groupes de fichiers distincts afin de réduire les temps de mise à jour des données et des index. Dans le cas de données sensibles, la répartition par groupe de fichiers peut également être conduite par la politique de sauvegarde adoptée.
1. Création d’un groupe de fichiers
Avant de pouvoir utiliser les groupes de fichiers, il faut les créer. Lors de la création de la base, le groupe de fichiers PRIMARY a été créé.
C’est par l’intermédiaire d’une commande ALTER DATABASE que l’on va créer un groupe de fichiers. Et cette commande va permettre...
Instructions INSERT, SELECT ... INTO
L’instruction SELECT INTOpermet d’insérer les données résultat d’une commande SELECT dans une table qui sera elle-même créée par cette requête SELECT.
La table créée de la sorte ne dispose d’aucune contrainte d’intégrité.
select nom,prenom
into cli
from dbo.CLIENTS; La commande INSERT est également capable d’insérer le résultat d’une commande SELECT dans une table qui a été créée auparavant à l’aide de l’instruction SQL DDL CREATE TABLE.
Cette fois-ci, il est tout à fait possible d’inclure la définition de contraintes d’intégrité lors de la création de la table.
insert into cli(nom,prenom)
select nom,prenom
from dbo.clients; Structure des index
SQL Server propose deux types d’index :
-
Les index ordonnés ou clustered.
-
Les index non ordonnés ou non clustered.
1. Les index ordonnés
Ces index sont constitués d’un arbre binaire (b-tree) dans lequel les pages de niveau feuille contiennent les données de la table sous-jacente. Lors de l’ajout d’une ligne d’information, cette ligne est insérée en fonction de la valeur de sa clé. Il ne peut donc y avoir qu’un seul index ordonné par table.
Étant donné que la clé de l’index organise physiquement la table, il est nécessaire de baser cet index sur une valeur stable et c’est pourquoi la clé primaire, qui de préférence doit être un entier compteur, est traditionnellement retenue.
Le schéma ci-dessous illustre de façon synthétique la structure d’un index ordonné. En plus des chaînages permettant de parcourir l’arbre de bas en haut (depuis la racine vers les feuilles), il existe un double chaînage permettant de parcourir toutes les pages d’un même niveau.
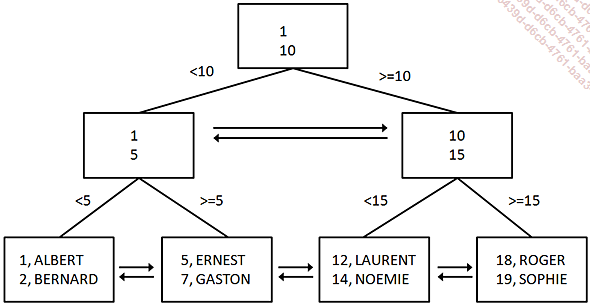
L’index ordonné est créé par défaut lorsqu’une contrainte de clé primaire est définie sur une table. Si l’administrateur souhaite que la définition de la contrainte ne s’accompagne pas de la création d’un tel index il lui est nécessaire de spécifier le mot-clé NONCLUSTERED lors de la définition de la contrainte.
Syntaxe
ALTER TABLE nomTable
ADD CONSTRAINT nomContrainte PRIMARY KEY
[CLUSTERED|NONCLUSTERED] (listeColonnes); La seconde possibilité est de définir un index avec l’option CLUSTERED.
Syntaxe
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED] INDEX nomIndex
ON nomTable (listeColonnes)
[ON groupeDeFichiers]; 2. Les index...
Partitionnement des tables et des index
L’objectif du partitionnement est d’offrir une meilleure montée en charge sur les tables très volumineuses en termes de données et accédées par de nombreux utilisateurs.
Le partitionnement peut être utile pour diviser la méthode d’accès aux données. Par exemple, sur la table des commandes, il n’est possible de modifier (update) que les commandes de l’année comptable en cours. Les commandes des années précédentes doivent être en lecture seule.
Le partitionnement d’une table permet de stocker une table de grande dimension sur plusieurs fichiers/groupes de fichiers. Chacune de ces partitions est plus petite que la table initiale et donc plus facile à gérer pour SQL Server.
Le partitionnement se fait selon un critère lié aux colonnes de la table ; par exemple, sur la date de commande avec le 1er janvier de l’année en cours pour valeur de délimiteur.
La table partitionnée permet d’optimiser le stockage des informations, sans que le nombre de tâches administratives supplémentaires soit important. En effet, des éléments tels les contraintes d’intégrités, les déclencheurs sont définis au niveau de la table sans tenir compte de l’espace de stockage physique utilisé.
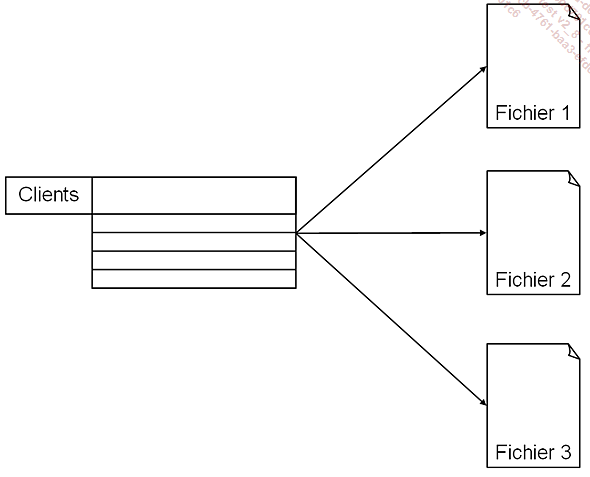
Pour partitionner la table, il est donc nécessaire de définir une fonction et un schéma de partitionnement qui vont indiquer une clé de partitionnement qui va être utilisée pour sélectionner la partition, donc le groupe de fichiers où vont être stockées les données.
Si deux tables utilisent la même fonction de partitionnement et le même schéma de partitionnement, alors les données en relations seront stockées...
Compression des données
SQL Server donne la possibilité d’activer la compression au niveau des tables et des index. Si la compression peut être définie sur des tables et index existants, il ne sera pris en compte qu’après la reconstruction de la table (ALTER TABLE nomTable REBUILD) ou bien de l’index concerné. Si la compression de la table entraîne la compression de l’index ordonné (CLUSTERED), les index non ordonnés ne sont pas affectés, et il est nécessaire d’activer la compression sur chacun d’eux un par un. Dans le cas des tables partitionnées, la compression peut être mise en place partition par partition.
La compression n’est possible que sur les données utilisateur. Les tables système ne peuvent pas être compressées.
L’objectif de la compression est de réduire l’espace disque utilisé par les données de la table. La compression des données va permettre de stocker plus de lignes d’informations sur le même bloc de 8 ko. La compression ne permet pas d’augmenter la taille maximale des lignes. En effet, le mécanisme doit être réversible.
Sur des tables valorisées, il est possible de connaître l’impact de la compression des données en exécutant la procédure stockée sp_estimate_data_ compression_savings.
La mise en place de la compression est une opération ponctuelle. Aussi, est-il préférable de passer par l’assistant proposé par SQL Server Management Studio. Au niveau Transact SQL, la compression est mise en place avec les instructions CREATE TABLE/CREATE INDEX et ALTER TABLE/ALTER INDEX.
L’assistant de compression des données est lancé depuis le menu contextuel associé à la table en sélectionnant...
Cryptage des données
SQL Server permet de crypter les fichiers de données et les journaux. Ce cryptage est dynamique et est effectué lors de chaque écriture sur le disque. Il est en est de même pour l’opération de décryptage. Cette fonctionnalité de cryptage/décryptage transparent est identifiée sous le nom TDE ou Transparent Data Encryption.
La mise en place de cette opération de cryptage permet de garantir une opacité plus grande des fichiers de données et journaux face aux différents outils système d’analyse des fichiers, ou bien pour éviter un détachement/attachement de base de données non autorisé. Cependant cette opération de cryptage n’apporte aucune garantie supplémentaire en ce qui concerne la communication entre le processus client et le serveur. Lorsque le cryptage de la base de données est actif, les sauvegardes sont également cryptées avec la même clé. Il est donc nécessaire de posséder cette clé pour être en mesure de restaurer les données.
Le cryptage des données s’appuie sur une clé de cryptage (DEK : Database Encryption Key) qui est enregistrée dans la base master par exemple sous la forme d’un certificat.
Avant de pouvoir mettre en place le cryptage sur une base, il faut commencer par définir une clé principale afin d’obtenir un certificat valide. Le certificat est alors utilisé pour définir la clé de cryptage. La génération de cette clé peut être réalisée par différents algorithmes. Le nom de l’algorithme choisi est passé en paramètre à l’instruction CREATE DATABASE ENCRYPTION KEY.
Exemple
Dans l’exemple ci-dessous, le cryptage est défini sur la base GESCOM....
Les tables temporelles
SQL Server propose de suivre automatiquement les différentes versions des informations stockées dans une table. C’est-à-dire que SQL Server va garder une version de chaque ligne avant et après modification.
Le nom exact de ce mécanisme proposé par SQL est « tables temporelles à système par version » car la période de validité de chaque ligne est gérée par SQL Server.
Pour pouvoir gérer cette notion de temporalité, SQL Server s’appuie sur :
-
deux colonnes de type datetime2. Ces deux colonnes correspondent aux dates et heures de début et de fin de validité des données,
-
une table miroir (en termes de structure) à la table qui contient les données actives afin de conserver l’historique. On nomme souvent cette table « table d’historique ». Elle peut être créée automatiquement par SQL Server ou bien par l’administrateur.
Ces tables, bien que particulières dans leur système de gestion de l’information, peuvent s’administrer comme n’importe quelle autre table de la base de données.
Syntaxe
CREATE TABLE nomTable(
nomColonne type, ...
debutValidite datetime2 GENERATED ALWAYS AS ROW START NOT NULL,
finValidite datetime2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (debutValidite, finValidite)
) WITH (SYSTEM_VERSIONING=ON (HISTORY_TABLE= nomTableHistorique)) ; Cette table nécessite une clé primaire.
Exemple
Dans l’exemple présenté ci-dessous, une table des produits est générée avec une notion de temporalité.
CREATE TABLE dbo.produits(
reference char(8) constraint pk_produits primary key,
designation varchar(200),
debutValidite datetime2 GENERATED ALWAYS...Planification
1. Dimensionner les fichiers
Afin d’évaluer la taille des fichiers nécessaires au stockage des informations contenues dans la base il faut prendre en compte de nombreux critères.
Pour les fichiers de données
-
Distinguer les tables système et utilisateur.
-
Prendre en compte le nombre de lignes dans les tables.
-
Recenser les valeur indexées (clé, nombre de ligne, facteur de remplissage).
C’est après une fine évaluation de la quantité d’espace occupée qu’il est possible de fixer la taille initiale des fichiers de données. La méthode la plus simple est d’évaluer la longueur moyenne d’une ligne, de calculer combien de lignes peuvent être stockées dans un bloc de 8 ko, et enfin de trouver le nombre de blocs nécessaires pour stocker toutes les lignes de la table. À partir de ce nombre de blocs utilisés par la table, il convient de prendre le multiple de 8 immédiatement supérieur puis de diviser par 8 pour obtenir le nombre d’extensions.
Pour les fichiers journaux
-
L’activité.
-
La fréquence.
-
La taille des transactions.
-
Les sauvegardes.
C’est la prise en compte de ces critères, ainsi que la consultation des options de la base, qui vont permettre de fixer une taille optimale pour le fichier journal. Au départ il peut être utile de fixer la taille du journal entre 10 % et 25 % de la taille des données dans la base. Ce pourcentage est à diminuer si la base supporte principalement des requêtes de sélection SELECT, qui n’utilisent pas le journal.
2. Nommer la base et les fichiers de façon explicite
Il est important de prévoir le nom de la base, les noms logiques, physiques et la taille des fichiers ainsi que la gestion dynamique ou non de l’accroissement.
3. Emplacement des fichiers...
Exercice : créer une base de données
1. Énoncé
La première étape consiste donc à créer la base de données LivreTSQL, et comme son nom l’indique, elle devra être créée à l’aide d’un script Transact SQL. Une seconde base, nommée LivreSSMS, sera créée depuis l’interface graphique de Management Studio.
Les fichiers de données vont être définis dans un répertoire spécifique. Il convient de créer le dossier c:\donnees. Bien entendu, stocker les données directement sur le disque c:\ relève de l’exemple pédagogique.
Paramètres de la base LivreTSQL
Fichier de données
-
Taille : 10 Mo
-
Nom physique : c:\donnees\LivreTSQL.mdf
-
Nom logique : LivreTSQL
Fichier journal
-
Taille : 8 Mo
-
Nom physique : c:\donnees\LivreTSQL_log.ldf
-
Nom logique : LivreTSQL_log
Paramètres de la base LivreSSMS
Fichier de données
-
Taille : 15 Mo
-
Nom physique : c:\donnees\LivreSSMS.mdf
-
Nom logique : LivreSSMS
Fichier journal
-
Taille : 8 Mo
-
Nom physique : c:\donnees\LivreSSMS_log.ldf
-
Nom logique : LivreSSMS_log
2. Corrigé
La base de données LivresTSQL peut être créée à l’aide du script suivant :
CREATE DATABASE LivreTSQL
ON PRIMARY (
NAME=LivreTSQL,
FILENAME='c:\donnees\LivreTSQL.mdf',
SIZE=10Mb
)
LOG ON (
NAME=LivreTSQL_log,
FILENAME='c:\donnees\LivreTSQL_log.ldf'...Exercice : ajouter un groupe de fichiers
1. Énoncé
Sur la base LivreTSQL, ajoutez le groupe de fichiers Data. Ce groupe de fichiers est composé de deux fichiers : data1.ndf et data2.ndf.
Le fichier data1.ndf possède une taille fixe de 50 Mo tandis que le fichier data2.ndf possède une taille initiale de 10 Mo puis peut croître jusqu’à la taille de 50 Mo par pas de 10 Mo.
2. Corrigé
Pour ajouter un groupe de fichiers et définir les fichiers présents dans ce groupe, il est possible de passer par la boîte de dialogue présentant les propriétés de la base depuis SSM, mais il est également possible de passer par un script Transact SQL. Ce script est présenté ci-dessous.Dans un premier temps, le groupe de fichiers est défini à l’aide de l’instruction ALTER DATABASE.
ALTER DATABASE LivreTSQL
ADD FILEGROUP Data; Le groupe de fichiers est défini, mais il n’est pas encore possible de l’utiliser car aucun fichier n’appartient à ce groupe. Le premier fichier (data1) va être créé à l’aide du script ci-dessous.
ALTER DATABASE LivreTSQL
ADD FILE (
NAME=data1,
FILENAME='c:\donnees\data1.ndf',
SIZE=50Mb,
MAXSIZE=50Mb
)
TO FILEGROUP Data; Le second fichier (data2) est créé de façon très similaire mais en ajoutant les paramètres MAXSIZE et FILEGROWTH afin de contrôler...

