
Implémentation des bases de données
Présentation de SQL Server
Pour travailler avec les bases de données de façon optimale, SQL Server, comme les autres SGBDR, s’appuie massivement sur le langage SQL. Pour accroître les possibilités de traitement des données au niveau du serveur, SQL Server propose le langage Transact-SQL qui apporte des possibilités de langage procédural au langage SQL qui est ensembliste. Ces deux langages sont étroitement liés au sein de SQL Server, toutefois il est important de souligner que le langage Transact-SQL est spécifique à SQL Server. Dans ce livre, l’étude de ces deux langages est clairement séparée.
SQL Server est un outil serveur composé de services et d’outils clients. Les services vont permettre le bon fonctionnement du moteur de base de données (SQL Server), la gestion des tâches planifiées (Agent SQL Server), la gestion des index de texte intégral (SQL Full-text Filter Daemon Launcher) ou bien encore la gestion dynamique des ports TCP/IP (SQL Server Bowser) dans le cas où plus d’une instance s’exécute sur le serveur.
En complément de ces services, Microsoft propose également des outils graphiques ou en mode ligne de commande pour travailler directement avec les bases de données. Ces outils s’adressent aussi bien au développeur d’application qu’à l’administrateur de bases de données. Il n’existe pas de séparation en termes d’outils par rapport à ces deux grands rôles d’utilisateurs de bases de données. En effet, il semble illusoire de vouloir administrer une base de données en ignorant tout de la façon dont il est possible d’utiliser la base. Sinon comment optimiser une requête ? Comment faire les bons choix en termes de type de données ? De même, un développeur d’applications ne peut pas se permettre de travailler en ignorant les contraintes administratives liées à une bonne utilisation des données. La solution de donner à tous les utilisateurs des privilèges d’administrateur n’est pas une bonne option. Le développeur peut par exemple faciliter le travail des administrateurs en s’appuyant sur les schémas pour organiser les tables...
Les principes élémentaires de la gestion d’une base de données
1. Les trois catégories d’instructions
Microsoft Transact-SQL est un langage de requêtes amélioré par rapport au SQL dont il reprend les bases. Le SQL (Structured Query Language) est le lan-gage standard, créé par IBM dans les années 70, pour la gestion des SGBDR (systèmes de gestion de bases de données relationnelles).
Trois catégories d’instructions composent le langage SQL :
-
Le langage de définition de données (Data Definition Language - DDL) permettant la création, la modification et la suppression des objets SQL (TABLE, INDEX, VIEW, PROCEDURE, etc.).
-
Le langage de manipulation de données (Data Manipulation Language - DML) fournissant les instructions de création, de mise à jour, de suppression et d’extraction des données stockées.
-
Le langage de contrôle d’accès aux données (Data Control Language - DCL) pour la gestion des accès aux données, des transactions et de la configuration des sessions et des bases.
De plus, le Transact-SQL prend en compte des fonctionnalités procédurales telles que la gestion des variables, les structures de contrôle de flux, les curseurs et les lots d’instructions. C’est donc un langage complet qui comporte des instructions, qui manipule des objets SQL, qui permet d’effectuer de la programmation procédurale et qui utilise des expressions.
À l’aide du Transact-SQL, il est possible de définir des fonctions et des procédures qui sont directement exécutées sur le serveur de base de données. Ce type de procédures et fonctions est particulièrement intéressant lorsque le traitement nécessite de manipuler un volume d’informations important pour produire le résultat. De même, le développement en Transact-SQL est parfaitement adapté dans un cadre de partage de fonctionnalités car les procédures et fonctions hébergées par le serveur peuvent être exécutées depuis un environnement client quelconque (.NET, Java...).
2. Les instructions
Dans la norme SQL, les instructions se terminent par un point-virgule. SQL Server permet d’omettre...
Les tables
Une table représente une structure logique dans laquelle les données vont être enregistrées. Pour permettre une bonne organisation des informations, chaque table est constituée de colonnes ou attributs afin de structurer les données. Chaque attribut est caractérisé par son identificateur qui est unique à l’intérieur de la table et par son type de données. Une application va donc utiliser plusieurs tables différentes et les données seront enregistrées dans ces différentes tables. Pour garantir la cohérence des données, il est nécessaire de définir des contraintes au niveau de la structure des tables. De telles contraintes sont appelées contraintes d’intégrité.
Les trois opérations de gestion de table sont la création (CREATE TABLE), la modification (ALTER TABLE) et la suppression (DROP TABLE). Ces opérations peuvent être réalisées avec un script SQL ou par un assistant graphique de SQL Server Management Studio. Ces opérations sur les tables affectent directement la structure de la base de données et il est nécessaire de disposer de privilèges SQL Server suffisants comme être membre du rôle de base de données db_owner (ce qui équivaut à être reconnu comme le propriétaire de la base) ou bien de disposer du privilège d’exécuter l’instruction CREATE TABLE sur la base de données courante.
Bien entendu, l’administrateur du serveur SQL Server peut créer des tables comme il le souhaite.
1. La création
L’étape de création des tables est une étape importante de la conception de la base, car les données sont organisées par rapport aux tables. Cette opération est ponctuelle et elle est en général réalisée par l’administrateur (DBA : DataBase Administrator) ou tout au moins par la personne chargée de la gestion de la base. La création d’une table permet de définir les colonnes (nom et type de données) qui la composent ainsi que les contraintes d’intégrité. De plus, il est possible de définir des colonnes calculées, un ordre de tri spécifique à...
Les index
1. L’objectif
Les index sont un moyen d’accéder rapidement à une ou à des données afin de les consulter, de les modifier ou de les supprimer.
Les index des bases de données fonctionnent de manière assez similaire aux index des livres. Si une personne a besoin de rechercher une information précise dans un livre, elle a différents moyens d’y parvenir.
-
Elle peut lire le livre depuis le début jusqu’à trouver l’information qui l’intéresse. Cette solution est bien adaptée si le livre est très court. En revanche, si le livre est volumineux, cela peut prendre beaucoup de temps.
-
Elle peut consulter l’index pour rechercher à l’aide d’un mot-clé. La recherche dans l’index est rapide puisque les pages de celui-ci sont bien moins nombreuses que les pages du livre. De plus, les termes indexés sont triés par ordre alphabétique, ce qui permet de les trouver plus rapidement. L’index indique ensuite à quelle page trouver l’information recherchée. Cette solution permet d’aboutir en n’ayant consulté que peu de pages. Néanmoins, il est nécessaire que l’index existe et que le terme recherché soit présent dans cet index.
-
Elle peut enfin consulter la table des matières, qui constitue un index thématique. Les titres des différentes parties du livre y sont regroupés dans le même ordre que le livre. À nouveau, peu de pages sont consultées avant d’aboutir à l’information recherchée.
Les tables peuvent être indexées suivant une ou plusieurs colonnes. Ces colonnes peuvent être de n’importe quel type à l’exception de TEXT, NTEXT et IMAGE. Dans le cas d’un index portant sur plusieurs colonnes, l’ordre de ces colonnes est important puisque l’index permet de trouver rapidement une valeur pour la première colonne indexée mais pas pour les autres colonnes. L’index n’est utilisé pour trouver rapidement une valeur que si la valeur de la première colonne indexée est connue.
Les colonnes calculées peuvent être utilisées pour un index à condition qu’elles soient déterministes (n’utilisant que des fonctions...
Les schémas
1. L’intérêt
Dans SQL Server, les schémas représentent un ensemble logique à l’intérieur d’une base. Ils permettent de mieux organiser logiquement les tables, vues, procédures et fonctions. Par défaut, lors de création d’un objet, celui-ci est enregistré dans le schéma de l’utilisateur courant. Le schéma porte alors le même nom que celui de l’utilisateur. Il est possible d’associer un schéma existant avec un utilisateur, ou bien de créer un objet sur un schéma autre que celui associé à l’utilisateur (à condition que l’administrateur de base de données l’y autorise).
Lors de la création de la base, il existe le schéma dbo. Ce schéma est donc présent sur toutes les bases. En créant et en utilisant d’autres schémas, l’organisation logique des données est améliorée, car il est alors nécessaire de référencer les objets en les préfixant du nom du schéma (en effet les objets ne sont plus dans le schéma par défaut).
2. La création
Le schéma est défini par l’instruction CREATE SCHEMA nomSchéma.
Il est alors possible de créer des objets sur ce schéma en précisant lors...
La gestion d’une base de données
1. Le schéma de la base de données
SQL Server Management Studio permet de créer une représentation graphique de la base de données. Cette représentation est appelée schéma de base de données. Elle peut contenir tout ou une partie simplement des tables présentes dans la base de données. Toutes les tables présentes sur un schéma appartiennent à la même base de données.
Les informations présentes au niveau de chaque table sont paramétrables, ce qui permet d’adapter la quantité d’informations présentes en fonction du nombre de tables et de l’espace dont on dispose.
Pour créer un schéma, il faut sélectionner, depuis l’explorateur d’objets, le choix Nouveau schéma de base de données dans le menu contextuel associé au nœud Bases de données - nomBase - Diagrammes de base de données.
Par défaut, les éléments système permettant la prise en charge des schémas ne sont pas installés. Aussi, lors de la création du premier schéma, une boîte de dialogue est affichée pour demander l’autorisation afin de créer les objets nécessaires :
Lorsque les objets sont créés, il est nécessaire de refaire la demande de création de schéma de base de données. SQL Server Management Studio propose alors de sélectionner les tables qui y seront présentes. Dans le cas où l’on souhaite rajouter une table sur le schéma, il suffit de passer par le menu contextuel associé au schéma.
SQL Server propose une organisation du schéma qu’il est possible d’adapter. Pour modifier la représentation graphique d’une table, il faut sélectionner l’option Vue table depuis le menu contextuel associé à la table sur le schéma.
Exemple
Ci-dessous une représentation graphique de la base GesCom utilisée dans ce livre.
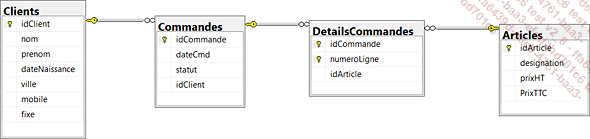
2. La gestion de l’espace de stockage
SQL Server utilise différents types de fichiers pour stocker l’ensemble des informations relatives à une base.
Fichier primaire
Il en existe un seul par base de données, c’est le point...
La surveillance et la vérification des bases et des objets
Après la création et l’utilisation des tables et des index, il est parfois utile de vérifier la cohérence des données et des pages.
L’instruction DBCC le permet :
DBCC CHECKDB [(nombase[,NOINDEX])] Elle vérifie, pour toutes les tables de la base, la liaison entre pages de données et d’index, les ordres de tri et le pointeur. Des informations sur l’espace disque du journal sont également fournies.
Pour effectuer ces vérifications, l’exécution de l’instruction DBCC CHECKDB entraîne automatiquement l’exécution des instructions DBCC CHECKALLOC et DBCC CHECKCATALOG au niveau de la base de données, DBCC CHECKTABLE pour chaque table et chaque vue.
L’instruction DBCC CHECKTABLE peut être exécutée de façon autonome au niveau d’une table en utilisant la syntaxe suivante :
DBCC CHECKTABLE (nomtable[,NOINDEX|identification index]) Si l’identificateur d’index est fourni, seul celui-ci sera vérifié. Si NOINDEX est spécifié, les index ne sont pas vérifiés.
Exercice
1. La création de la base de données
Créez à l’aide d’un script une base de données nommée Location. Choisissez celle-ci comme contexte d’exécution pour être prêt pour la suite des exercices.
Vous pouvez choisir de remplacer cet exercice par celui de la section La création d’une base de données si vous souhaitez vous entraîner à construire une base de données en paramétrant finement les fichiers à créer.
2. La création des tables
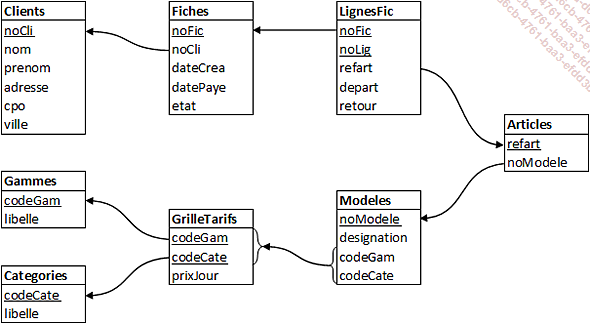
Créez les tables de votre base de données en respectant les règles suivantes :
-
Les contraintes de type clé primaire (éléments soulignés dans le schéma).
-
Les contraintes d’intégrité référentielle (flèches dans le schéma) :
-
Les fiches de location sont conservées (sans client associé) pour les clients qui sont supprimés (en application du droit à l’oubli du RGPD).
-
Suppression des lignes de location pour les fiches de location qui sont supprimées.
-
Modification de la valeur de refart répercutée en cas de changement.
-
Les contraintes d’unicité :
-
Les libellés des gammes et des catégories sont uniques.
-
Les contraintes de validation suivantes :
-
Le code postal est compris entre 01000 et 95999.
-
Les états possibles sont ‘EC’, ‘RE’ et ‘SO’ (en cours, rendue et soldée).
-
Le prix d’une journée est toujours positif.
-
La date de paiement d’une fiche est toujours, si elle est renseignée, postérieure à sa date de création.
-
La date de retour d’une ligne est toujours, si elle est renseignée, postérieure à sa date de départ.
-
La date de paiement d’une fiche est renseignée si l’état est soldé et n’est pas renseignée dans le cas contraire.
-
Les contraintes de non-nullité (valeurs requises) :
-
codeCate, codeGam, cpo, dateCrea, depart, designation, etat, libelle, nom, noModele...
Solutions des exercices
1. La création de la base de données
CREATE DATABASE Location;
GO
USE Location; 2. La création des tables
CREATE TABLE clients(
noCli NUMERIC(6) CONSTRAINT pk_clients PRIMARY KEY,
nom VARCHAR(30) NOT NULL,
prenom VARCHAR(30) NULL,
adresse VARCHAR(120) NULL,
cpo CHAR(5) NOT NULL
CONSTRAINT ck_clients_cpo
CHECK(cpo BETWEEN 1000 AND 95999),
ville VARCHAR(80) NOT NULL
CONSTRAINT df_clients_ville DEFAULT 'Nantes'
);
CREATE TABLE fiches(
noFic NUMERIC(6) IDENTITY(1001,1)
CONSTRAINT pk_fiches PRIMARY KEY,
noCli NUMERIC(6) NULL
CONSTRAINT fk_fiches_clients
REFERENCES clients(noCli)...