
Le modèle relationnel
Introduction
Si vous avez ouvert ce livre, c’est que vous souhaitez en savoir plus sur les bases de données sur SQL Server ! Vous vous posez sûrement beaucoup de questions concernant les bases de données, SQL Server et le langage SQL. Dans cette introduction, nous allons essayer de répondre brièvement à ces questions, avant de les développer plus en profondeur dans les chapitres suivants.
1. Qu’est-ce qu’une base de données ?
Voici la définition proposée par Wikipédia : « Une base de données permet de stocker et de retrouver l’intégralité de données brutes ou d’informations en rapport avec un thème ou une activité ; celles-ci peuvent être de natures différentes et plus ou moins reliées entre elles. » L’objectif premier est donc de stocker des données. Cela doit être un stockage organisé et pérenne :
-
Organisé, afin que les données puissent être retrouvées facilement et rapidement.
-
Pérenne, afin que les données restent présentes même en cas d’extinction de la machine ou de plantage de celle-ci.
2. Qu’est-ce qu’un système de gestion de bases de données ?
Un système de gestion de bases de données (SGBD) est un programme informatique...
Les tables
Le modèle relationnel organise les données en les répartissant dans des tables. Chaque table concerne une notion pour laquelle nous souhaitons enregistrer des données. Supposons que nous souhaitons créer une base de données pour gérer des commandes de produits. Il serait au moins nécessaire d’avoir une table pour enregistrer les produits, une pour les clients et une pour les commandes. Les noms des tables sont par convention toujours au pluriel : la table Clients, par exemple. Ceci s’explique par le fait que cette table contient les informations sur les clients.
Les tables sont parfois appelées relations dans certains ouvrages. Étant donné qu’elles sont mises en relation les unes avec les autres, ce vocabulaire n’est pas utilisé dans ce livre.
1. Les attributs
Chaque table contient des attributs correspondant aux informations qu’il est nécessaire de stocker à propos de celle-ci. Par exemple, la table Clients peut contenir le nom et le prénom du client, sa date de naissance et sa ville. Il est conseillé que les noms des attributs ne contiennent pas d’espace ni de caractères spéciaux. Les accents sont également déconseillés pour éviter un certain nombre de problèmes.
Le nombre d’attributs d’une table se nomme le degré.
Les attributs peuvent...
L’identification d’un enregistrement
Pour avoir une base de données efficace, il est nécessaire de pouvoir identifier de manière sûre un enregistrement. L’identification implique qu’il ne doit y avoir qu’un seul enregistrement qui réponde à cette identification.
1. Clé primaire
La clé primaire permet cette identification d’un enregistrement. Pour la constituer, il est possible d’utiliser un attribut seul ou un ensemble d’attributs. Par convention, la clé primaire est soulignée sur les représentations.
Pour un attribut seul, il est possible d’utiliser un attribut existant qui n’aura jamais la même valeur pour plus d’un enregistrement. Voici quelques exemples :
-
Le numéro de série pour un objet.
-
L’adresse MAC pour une carte réseau.
-
La plaque d’immatriculation pour un véhicule.
-
Le numéro de sécurité sociale pour une personne.
-
Un SIRET pour une entreprise.
-
Un ISBN pour un livre.
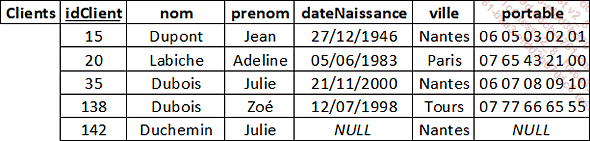
Parfois, aucun attribut ne peut être utilisé comme clé primaire. C’est par exemple le cas dans la table Clients. L’attribut nom a deux enregistrements ayant la même valeur (Dubois). Même chose pour l’attribut ville (Nantes). Pour l’attribut prenom, même s’il n’y a pas deux enregistrements ayant la même valeur pour cette...
La nullité
Il est parfois possible de ne pas avoir de valeur à renseigner pour un attribut d’un enregistrement. Cela peut être pour différentes raisons : par exemple, information inconnue, non pertinente ou inutile... Il est donc possible dans ce cas d’indiquer "non renseigné", c’est-à-dire une absence de valeur. Cela est indiqué par le mot-clé NULL.
Lors de la création d’une table, pour chaque attribut il faut indiquer s’il est obligatoire ou s’il est possible de ne pas le renseigner. Les attributs étant ou constituant la clé primaire d’une table sont nécessairement obligatoires. En revanche, il n’y a pas cette obligation pour les clés secondaires.
Les domaines de valeurs
Il est courant que pour un attribut, les valeurs possibles soient à choisir parmi un ensemble de valeurs qui ne changent pas. En base de données, cela se nomme un domaine de valeurs. Il existe des domaines de valeurs qui sont déjà définis : les nombres entiers, les dates… Mais il est également possible de définir de nouveaux domaines de valeurs.
Soit une table contenant les commandes effectuées par les clients. Ces commandes peuvent être de différents états : à préparer, en préparation, préparée, en cours d’acheminement, livrée ou en litige. Il est possible de définir un domaine de valeurs contenant : à préparer, en préparation, préparée, acheminement, livrée et en litige.
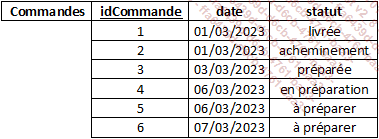
Cela se note :
etat = {"à préparer", "en préparation", "préparée", "acheminement", "livrée", "en litige"}
Si l’attribut statut est associé au domaine de valeurs etat, il n’est pas possible de mettre une valeur différente de celles présentes dans celui-ci.
À des fins d’optimisation, il est préférable d’avoir des chaînes de caractères courtes et de même taille pour un attribut. Il est alors possible...
Les contraintes d’intégrité référentielle et les clés étrangères
1. Entre différentes tables
Une contrainte d’intégrité référentielle (CIR) impose que toutes les valeurs utilisées pour un attribut d’une table apparaissent comme valeur d’une clé primaire choisie dans une autre table. La colonne sur laquelle est imposée la contrainte d’intégrité référentielle est nommée clé étrangère. Une contrainte d’intégrité référentielle est représentée par une flèche partant de la clé étrangère et pointant vers la clé primaire.
Très rarement, il est possible qu’une contrainte d’intégrité référentielle ne référence pas une clé primaire mais une clé secondaire.
Dans quel cas les contraintes d’intégrité référentielle sont-elles mises en place ?
Les tables d’une base de données peuvent être mises en relation de différentes manières, mais la plupart du temps par un mécanisme de jointure qui sera abordé plus en détail à la section Les jointures, plus loin dans ce chapitre. La jointure consiste à former une table avec les lignes de deux tables en joignant...
La normalisation des tables
Lorsque le schéma relationnel est défini afin de répondre à tous les besoins des utilisateurs, il est nécessaire de le normaliser afin d’éviter toute redondance d’information ainsi que toute structure non conforme avec le modèle relationnel. Lorsque cette opération est réalisée, à des fins d’optimisation, le schéma pourra alors être dénormalisé bien que cette opération soit rarement la meilleure. Si le développeur dénormalise le schéma, il doit également mettre en place l’ensemble du mécanisme qui permet de maintenir la cohérence des données. En effet, le modèle relationnel, et donc les SGBDR, ne peut garantir la cohérence des données que sur des modèles normalisés.
Les formes normales permettent de s’assurer que le schéma est bien conforme au modèle relationnel. Il existe de façon théorique cinq formes normales, mais dans la pratique, seules les trois premières sont appliquées.
L’application des formes normales nécessite de bien maîtriser le concept de dépendance fonctionnelle. Une donnée dépend fonctionnellement d’une autre lorsque la connaissance de la seconde permet de déterminer la valeur de la première. Par exemple...
Le schéma relationnel de la base de données et le dictionnaire des données
Le schéma de base de données permet de modéliser la structure de la base de données de manière non exhaustive mais avec les éléments les plus pertinents. Les tables sont représentées avec leur représentation condensée et les contraintes d’intégrité référentielles sont notées avec des flèches entre les attributs concernés.
Les exemples suivants de ce livre sont basés sur le schéma de base de données avec les tables suivantes respectant les trois premières formes normales :
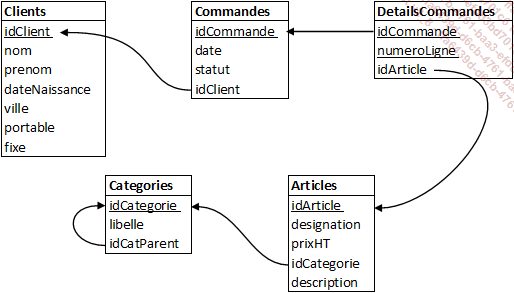
Le dictionnaire des données vient compléter le schéma de base de données en ajoutant des informations complémentaires sur chaque attribut. Cela permet d’indiquer par exemple :
-
le type de données utilisé,
-
si l’attribut utilise un domaine de valeurs,
-
si l’attribut est facultatif ou obligatoire,
-
s’il est une clé primaire, secondaire ou étrangère...
Voici un exemple de dictionnaire des données associé au schéma de base de données précédent :
|
Attribut |
Table |
Type de données |
Clé |
Nullité |
|
idClient |
Clients |
Entier |
Primaire |
Obligatoire |
|
nom |
Clients |
Chaîne de caractères |
Secondaire |
Obligatoire |
|
prenom |
Clients |
Chaîne de caractères |
Obligatoire |
|
|
dateNaissance |
Clients |
Date |
Facultatif |
|
|
ville |
Clients |
Chaîne de caractères |
|
Obligatoire |
|
portable |
Clients |
Entier |
Secondaire |
Facultatif |
|
fixe |
Clients |
Entier |
|
Facultatif |
|
idCommande |
Commandes |
Entier |
Primaire |
Obligatoire |
|
date |
Commandes |
Date |
|
Obligatoire |
|
statut |
Commandes |
Domaine {"AP"... |
L’algèbre relationnelle
Nous avons tous été habitués à utiliser avec des opérateurs arithmétiques travaillant sur des nombres. Dans le cas des bases de données, ce sont des tables de données qu’il faut manipuler avec des opérateurs arithmétiques adaptés à cela.
L’algèbre relationnelle est une méthode d’extraction permettant la manipulation des tables et des colonnes. Son principe repose sur la production de nouvelles tables (tables résultantes) à partir des tables existantes, ces nouvelles tables devenant des objets utilisables immédiatement.
Les opérateurs de l’algèbre relationnelle permettant de créer les tables résultantes sont basés sur la théorie des ensembles.
1. Les opérateurs
La syntaxe et les éléments de notation retenus ici sont les plus couramment utilisés. Parmi ceux-ci, s’il ne faut bien en maîtriser que quelques-uns, ce seraient :
-
la restriction
-
la projection
-
les jointures
-
les calculs élémentaires
-
les calculs d’agrégat
a. L’union
L’union entre deux tables de même structure (degré et domaines) donne une table résultante de même structure que celles-ci.
Notation : Rx = T1  T2
T2 Exemples
Soient les tables Clients et ClientsArchives :
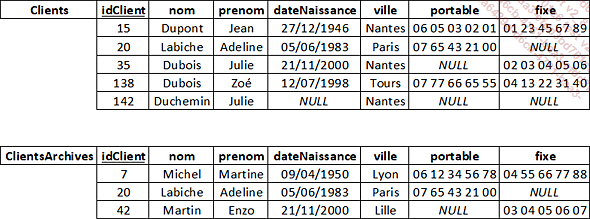
Clients actuels et archivés :
TousClients = Clients ClientsArchives 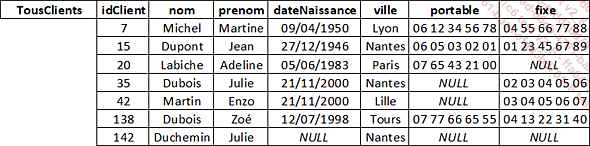
b. L’intersection
L’intersection entre deux tables de même structure (degré et domaines) donne une table résultante de même structure que celles-ci.
Notation : Rx = T1  T2
T2 Exemple
Clients qui sont présents à la fois dans les clients actifs et dans les clients archivés :
Acheval = Clients ClientsArchives 
c. La différence
La différence entre deux tables de même structure (degré et domaines) donne une table résultante de même structure ayant comme éléments l’ensemble des enregistrements de la première relation qui ne sont pas dans la deuxième.
Notation : Rx = T1 - T2 Exemple
Clients qui sont uniquement parmi les clients archivés :
AnciensClients = ClientsArchives - Clients 
d. La division
La division entre deux tables est possible à condition que la table...
Exercices
L’objectif est de créer une base de données pour gérer la location de matériel de ski. Les exercices se suivent et nécessitent de les réaliser dans l’ordre.
1. L’identification des clés primaires et des clés secondaires
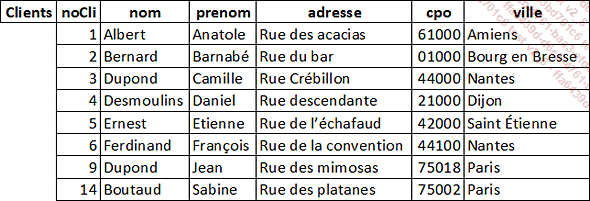
Pour chacune des tables suivantes, identifiez les clés primaires et les clés secondaires :
Afin d’avoir un jeu d’essai cohérent, et ne pas avoir des articles en cours d’emprunt depuis plusieurs mois, les dates du jeu d’essai dépendent de la date du jour (DDJ). Vous pouvez ainsi remplacer DDJ par la date actuelle au moment de réaliser cet exercice.
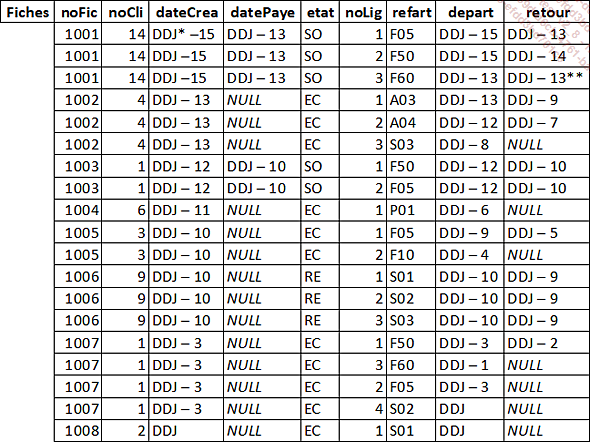
* DDJ = date du jour
** Le matériel est rendu 6 heures après avoir été emprunté.
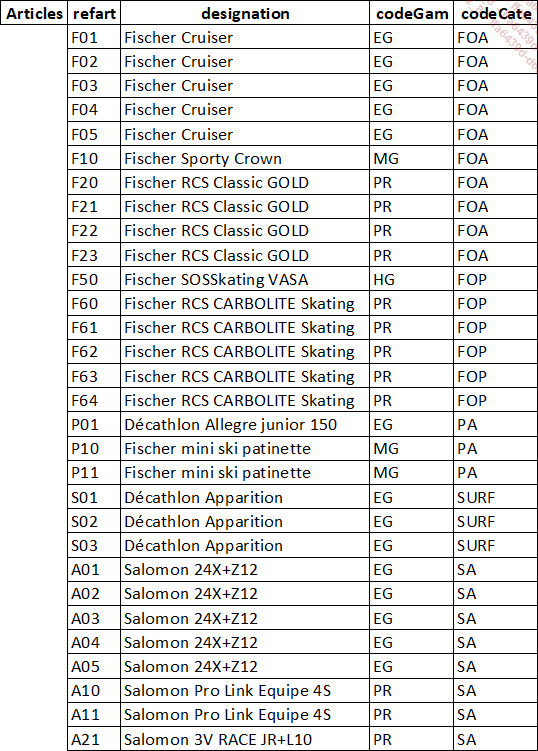
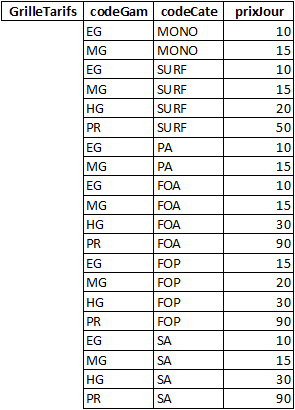
2. Les formes normales
Vérifiez si les tables respectent les trois formes normales. Pour celles qui posent problème, trouvez une solution pour que toutes les tables respectent bien les trois formes normales.
3. L’identification des contraintes d’intégrité référentielle
Identifiez les contraintes d’intégrité référentielle à mettre en place sur cette base de données et créez le schéma de la base de données en représentant chaque table en forme condensée avec les clés primaires soulignées et les contraintes d’intégrité référentielle indiquées avec des flèches.
4. La réalisation du dictionnaire des données
Réalisez le dictionnaire des données en complétant pour chaque attribut le tableau suivant :
|
Attribut |
Table |
Type de données |
Clé |
Nullité |
|
|
|
|
|
|
5. L’algèbre relationnelle
Indiquez les données répondant aux questions suivantes, d’après le jeu d’essai donné précédemment. Indiquez également les opérations d’algèbre relationnelle à réaliser.
La liste des clients (toutes les informations) dont le nom commence par un « D »
|
N° Client |
Nom |
Prénom |
Adresse |
Code postal |
Ville |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Les noms...
Correction des exercices
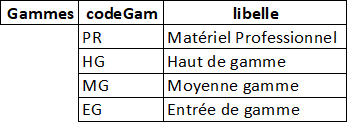
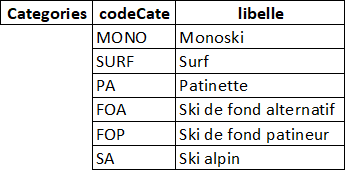
1. L’identification des clés primaires et des clés secondaires
|
Table |
Attribut(s) formant la clé primaire |
Attribut(s) formant une clé secondaire |
|
Clients |
noCli |
(éventuellement nom + prenom + ville) |
|
Fiches |
noFic + noLig |
|
|
Articles |
refart |
|
|
GrilleTarifs |
codeGam + codeCate |
|
|
Gammes |
codeGam |
libelle |
|
Categories |
codeCate |
libelle |
2. Les formes normales
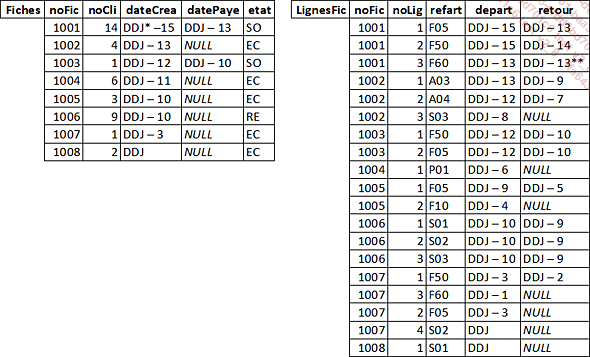
La table Fiches
La table Fiches ne respecte pas la deuxième forme normale car les attributs noCli, dateCrea, datePaye et etat ne dépendent que de l’attribut noFic qui n’est qu’une partie de la clé primaire. Il faut donc scinder cette table en les deux suivantes :
La table Articles
La table Articles ne respecte pas la troisième forme normale car la désignation d’un article détermine le code de sa gamme et le code de sa catégorie. Par exemple, un Fischer Cruiser a pour codeGam EG et pour codeCate FOA. Cette information est dupliquée. Il serait d’ailleurs incohérent si un article ayant Fischer Cruiser avait un codeGam ou un codeCate différent. Il est donc nécessaire de scinder cette table en deux tables comme ceci :
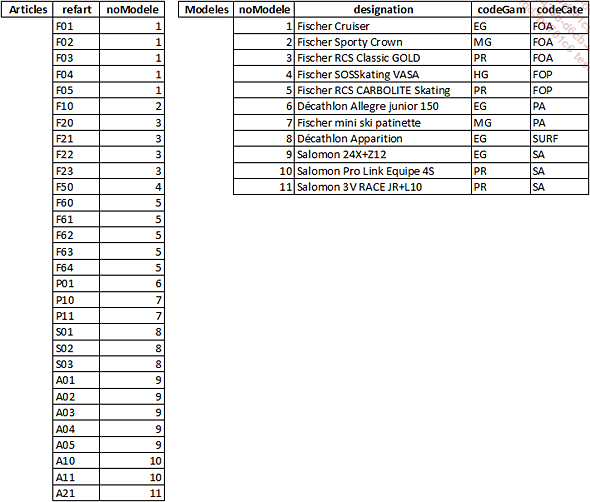
3. L’identification des contraintes d’intégrité référentielle
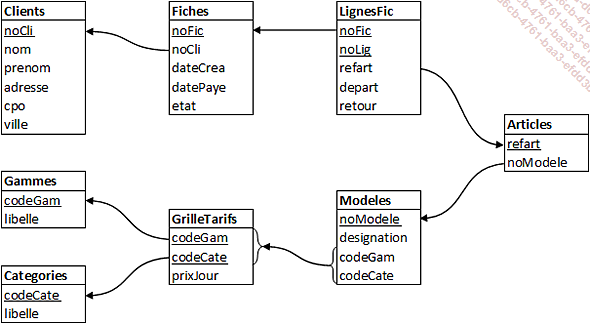
Ce schéma de base de données est disponible en annexe de ce livre et en fichier à télécharger afin que vous puissiez avoir ce schéma sous les yeux pour la résolution de la suite des exercices.
Entre Modeles et GrilleTarifs, il y a une contrainte d’intégrité référentielle portant sur un couple d’attributs : il faut que le couple de valeurs dans Modeles corresponde à un même couple de valeurs dans GrilleTarifs afin que pour chaque modèle d’article soit associé un tarif de location.
Il est envisageable de mettre en plus des contraintes d’intégrité référentielle entre les attributs codeGam de Modeles et de Gammes et entre les attributs codeCate de Modeles et de Categories. Néanmoins, comme les valeurs de codeGam présentes dans Modeles ne sont que des valeurs de codeGam de GrilleTarifs et que ces valeurs ne sont que des valeurs présentes pour l’attribut codeGam de Gammes, il y a donc une contrainte d’intégrité...
