
Gestion des données distribuées
Introduction
La gestion des données se fait de plus en plus dans des environnements réseau hétérogènes, c’est-à-dire avec plusieurs serveurs SQL Server qui doivent communiquer, ou avec des données autres que SQL Server installées sur des postes clients, ou encore avec des applications utilisant des données de plusieurs serveurs SQL et d’autres gestionnaires de données (Access, Oracle...).
Ces environnements vont donc poser de nombreux problèmes, parmi lesquels :
-
la mise à disposition des utilisateurs de toutes les données,
-
la concurrence des accès aux données,
-
la cohérence et l’intégrité des données,
-
la sécurité d’accès aux données,
-
les performances des serveurs de données.
Les différents rôles de l’administrateur et du développeur de bases de données SQL Server consistent à :
-
assurer la copie et le transfert des données entre plusieurs bases ou plusieurs serveurs,
-
établir la cohérence des données réparties dans plusieurs bases,
-
exporter et importer des données vers des gestionnaires de bases de données autres que SQL Server,
-
permettre aux utilisateurs d’un serveur d’accéder aux données d’un autre serveur.
Les développeurs d’applications utilisant...
SQL Server Integration Services
SQL Server propose avec SSIS (SQL Server Integration Services) un ensemble d’outils et de techniques puissants et conviviaux qui permettent d’importer rapidement un important volume de données dans une base SQL Server.
L’extraction, la transformation et le chargement de données (ETL pour Extract Transform and Load) sont les trois tâches qu’Integration Services doit remplir.
SSIS peut être utilisé pour récupérer des données stockées dans différents formats en vue d’une intégration dans une base SQL Server. Il peut aussi être utilisé pour consolider, dans une base de type Data Warehouse (ou entrepôt de données), des informations en provenance de plusieurs sources SQL Server par exemple. Il peut également être utilisé pour transférer facilement des données d’une base à une autre et profiter de ce transfert pour réorganiser les données afin de répondre aux nouvelles demandes d’évolution.
SSIS peut également être utilisé pour réaliser des tâches d’administration comme la sauvegarde de tables, de vues, de procédures... Il est ainsi possible d’automatiser ces tâches et de planifier leur exécution.
SSIS peut également être utilisé par l’administrateur pour intégrer dans une base les données d’un fichier plat.
1. Les principes de fonctionnement
Le service d’intégration de SQL Server (SSIS) repose sur quatre éléments principaux qui sont :
-
le service SSIS proprement dit, qui permet depuis SQL Server Management Studio, de suivre l’exécution en cours des lots et de gérer les stockages des lots,
-
le modèle d’objet (Object Model) de SSIS propose sous forme d’API d’accéder aux outils SSIS, aux utilitaires en ligne de commande et de personnaliser les applications,
-
le runtime SSIS permet l’exécution des lots et gère de ce fait tous les éléments liés comme les journaux, la configuration des connexions, les transactions...
-
le flux de données (Data Flow Task). Ce composant intègre le moteur de gestion des données qui lit l’information depuis la source, la stocke dans...
Le transport d’une base de données
Il est possible de détacher et d’attacher les fichiers de données et journaux d’une base de données SQL Server. Cette opération permet de déplacer rapidement et simplement une base depuis une instance SQL Server vers une autre instance située sur le même serveur ou bien un autre serveur. Il est également possible de profiter du moment où la base est détachée pour faire une copie des fichiers afin d’attacher immédiatement la base sur le serveur d’origine et d’attacher une copie de la base sur un serveur de secours ou de test. En effet, cette procédure est beaucoup plus rapide que le fait de passer par une étape de sauvegarde/restauration.
Les procédures sp_create_removable et sp_attach_db sont maintenues pour des raisons de compatibilité.
1. Le détachement d’une base
En détachant une base de son serveur, les fichiers de données et de journaux sont conservés dans leur état. La base pourra être rattachée à un serveur SQL Server, y compris celui à partir duquel la base a été détachée.
Cette opération est possible pour n’importe quelle base de données utilisateur, à condition qu’elle soit dans un état correct (par exemple, pas en cours de restauration), et qu’elle ne soit pas impliquée dans des opérations administratives au niveau de la base, comme un processus de réplication par exemple.
a. Depuis SQL Server Management...
Les exports et imports au format CSV
1. Les instructions BULK
Les instructions BULK permettent de travailler avec des masses de données présentes dans des fichiers au format Comma Separated Values (*.csv), mais également au format XML (cela est présenté dans le prochain chapitre : Les types évolués).
a. L’import
L’instruction BULK INSERT réalise l’import des données présentes dans le fichier CSV dans une table déjà existante de la base de données.
Syntaxe
BULK INSERT [[nomBaseDeDonnées.]nomDuSchema.]nomTableOuVue
FROM 'fichierDeDonnées' [WITH options][;] nomTableOuVue
Nom de la table dans laquelle insérer les données. Pour une vue, les données doivent toutes être des colonnes d’une même table afin d’y être insérées.
’fichierDeDonnées’
Chemin complet vers le fichier contenant les données à importer. Il est possible d’utiliser un chemin réseau en utilisant l’adresse UNC de la ressource (exemple : \\serveurA\Data\nomFichier.txt).
options
Permet de spécifier des informations complémentaires comme l’encodage du fichier (CODEPAGE), le choix du séparateur de champs (FIELDTERMINATOR), un fichier de correspondance entre les champs du fichier CSV et les colonnes de la table (FORMATFILE)...
Exemple
BULK INSERT Clients FROM 'C:\data\nouveauxClients.csv'
WITH (CODEPAGE='65001', FIELDTERMINATOR=';'); La page de code 65001 correspond à de l’Unicode UTF-8, et dans cet exemple les champs sont séparés par un point-virgule.
b. L’utilisation comme une table
Il est parfois intéressant d’utiliser des données présentes dans un fichier CSV comme si elles étaient présentes dans une table. La méthode OPENROWSET permet cela, mais également avec des données provenant de n’importe quelle source OLEDB.
Il est nécessaire de produire un fichier de format (.fmt) décrivant la structuration des données dans le fichier.
Syntaxe
OPENROWSET({nomFournisseur, chaîneConnexion, requête
| BULK 'nomFichier',
{...Les serveurs liés
Un serveur lié est un serveur qui fait partie d’un réseau et auquel les utilisateurs peuvent accéder par l’intermédiaire de leur serveur local.
L’intérêt est de gérer les connexions en local et que les utilisateurs puissent quand même exécuter des procédures stockées ou accéder à des tables sur le serveur lié. Ce serveur peut être un autre serveur SQL Server, mais également un autre SGBDR accessible comme une source de données OLEDB (exemples : un serveur Oracle, un serveur DB2, un système de fichiers, une feuille de calcul Excel...). De cette manière, il est possible de gérer des données hétérogènes, par exemple Oracle, Access et SQL Server, à partir de l’instance de votre serveur SQL Server.
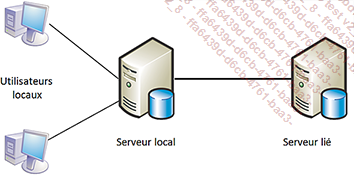
Ces utilisateurs de ce type de solution distribués sont appelés utilisateurs distants sur les serveurs liés et doivent posséder un nom d’accès sur chaque serveur lié.
Avant de pouvoir utiliser cette fonctionnalité, il faudra ajouter les serveurs liés, les configurer et gérer les utilisateurs distants.
Les serveurs liés doivent être paramétrés afin que les connexions distantes soient autorisées. En tant qu’administrateur, il faut exécuter le Gestionnaire de configuration SQL Server et activer le protocole TCP/IP.
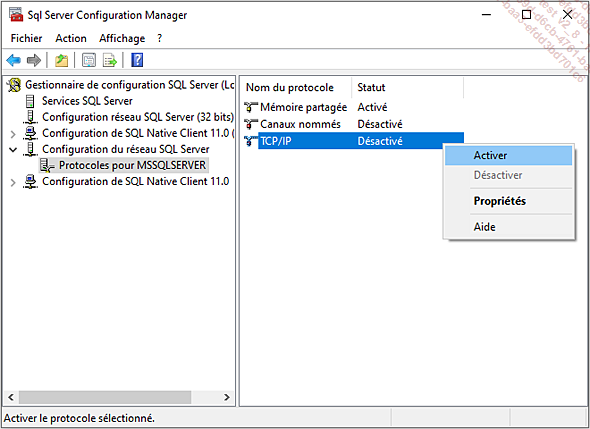
Il est ensuite nécessaire de redémarrer le service SQL Server pour que les chan-gements prennent effet.
Le pare-feu du serveur lié doit également être configuré pour laisser passer les trames réseau nécessaires. La procédure qui suit concerne le pare-feu Windows, mais avec un autre pare-feu le principe reste le même.
Il faut exécuter en tant qu’administrateur Pare-feu Windows Defender avec fonctions avancées de sécurité. Dans Règles de trafic entrant, il faut cliquer sur Nouvelle règle.
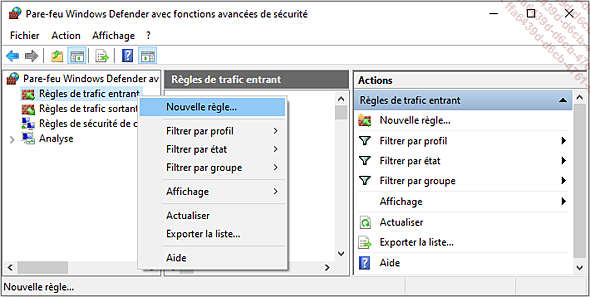
Il faut ensuite choisir de créer...
