
Création et gestion d’images Docker
Création manuelle d’une nouvelle image
1. Objectif
Dans le chapitre précédent, nous avons étudié le fonctionnement de base de Docker en utilisant des images préparées à l’avance pour nos exemples : l’image hello-world pour les premiers tests, l’image ubuntu pour les approches interactives par la ligne de commande, et enfin l’image nginx pour les tests impliquant un processus serveur. Ces images ont été récupérées en ligne sur le registre Docker Hub.
Bien que cette façon de fonctionner puisse suffire à des mises en œuvre extrêmement simples, un moment survient où il devient nécessaire de créer ses propres images pour évoluer vers plus de complexité. C’est ce type de manipulation que nous allons illustrer dans le présent chapitre.
2. Approche
L’approche naïve pour créer sa propre image est d’utiliser la commande commit entrevu dans le chapitre précédent pour persister l’état d’un conteneur sous forme d’une nouvelle image, après avoir ajouté à celui-ci les modifications nécessaires. Pour cela, nous pourrions lancer par exemple un conteneur sur une image ubuntu comme base et installer un produit en ligne de commande dans le conteneur.
Ensuite, le conteneur obtenu serait sauvegardé sous forme d’une image qu’il serait possible d’instancier ensuite autant de fois que souhaité. Bref, nous aurions créé une image avec un processus intégré selon nos besoins.
3. Difficultés
Dans les précédentes éditions du présent ouvrage, cette méthode était montrée en détail, de façon à faire apparaître toutes les difficultés liées :...
Utilisation d’un fichier Dockerfile
1. Intérêt des fichiers Dockerfile
La "recette" dont nous venons de parler se présente sous la forme d’un fichier texte nommé Dockerfile, utilisant une grammaire particulière à Docker. Ce fichier contient toutes les opérations nécessaires à la préparation d’une image Docker. Ainsi, au lieu de construire une image par des opérations manuelles dans un conteneur suivie par une commande commit (voire plusieurs si l’on procède en étapes) comme nous l’avons évoqué ci-dessus, nous allons pouvoir compiler une image depuis une description textuelle de ces opérations.
Voici par exemple le contenu du fichier Dockerfile correspondant à l’image officielle MongoDB en ligne 3.6 (un système de gestion de base de données NoSQL) telle qu’elle peut être retrouvée sur le registre Docker Hub (version 3.6.19 de MongoDB, disponible sur https://registry.hub.docker.com/_/mongo/, pour être plus précis ) :
FROM ubuntu:xenial
# add our user and group first to make sure their IDs get assigned
consistently, regardless of whatever dependencies get added
RUN groupadd -r mongodb && useradd -r -g mongodb mongodb
RUN set -eux; \
apt-get update; \
apt-get install -y --no-install-recommends \
ca-certificates \
jq \
numactl \
; \
if ! command -v ps > /dev/null; then \
apt-get install -y --no-install-recommends...Partage et réutilisation simple des images
1. Envoi sur votre compte Docker Hub
Dans le chapitre précédent, nous avons montré comment se connecter à Docker Hub et associer le compte avec un dépôt sur GitHub. Par la suite, nous avons fait en sorte que ce dépôt crée une image Docker à jour à chaque commit de code source.
Il est également possible de pousser dans un registre Docker une image créée localement, comme celles que nous avons mises en œuvre dans le présent chapitre. Pour cela, nous utiliserons une commande que nous n’avons pas encore présentée.
Envoyer une image locale sur le registre Docker Hub
docker push [image] Pour que cette commande fonctionne, il faut toutefois que l’image possède un nom complet, préfixé du nom du compte Docker Hub. C’est la raison pour laquelle l’image créée plus haut avait été nommée jpgouigoux/repeater. Il aurait également été possible de la nommer simplement repeater tant que l’exercice était local, puis d’utiliser la commande docker tag pour lui adjoindre une étiquette supplémentaire correspondant à ce nom complet.
Au passage, le nom véritablement complet de l’image créée était docker.io/jpgouigoux/repeater, comme on peut le voir en bas de la capture de la commande de compilation ci-dessous :
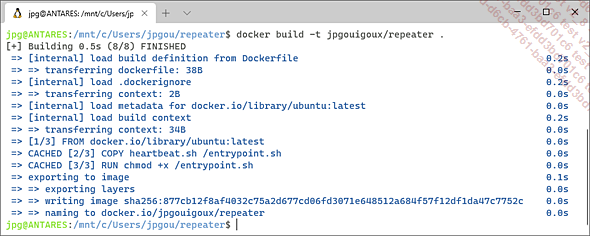
Par défaut, Docker part en effet du principe que nous utiliserons le registre d’images Docker Hub, dont l’adresse symbolique est docker.io. Il existe toutefois d’autres registres, comme celui de Microsoft. Pour donner un exemple, Docker Hub référence bien l’image de la runtime .NET :
En descendant dans la description, nous voyons d’ailleurs les différentes versions...
Bonnes pratiques
1. Principe du cache local d’images
Un utilisateur attentif aura certainement noté la différence de temps entre la première exécution d’un conteneur et les suivantes. La différence est particulièrement notable lorsqu’un conteneur est basé sur une image "lourde" comme ubuntu, et un peu moins sur les images de type "slim" ou alpine. Lors de la première exécution, Docker télécharge alors presque une centaine de mégaoctets. À la seconde exécution ainsi qu’aux suivantes, ce téléchargement n’a plus lieu d’être, et le démarrage du conteneur est rendu beaucoup plus rapide.
Nous parlons de démarrage du conteneur, mais il peut aussi bien s’agir de la seule commande pull de récupération de l’image depuis le registre. Il se trouve que la commande run est plus souvent utilisée, et qu’elle lance de toute façon une commande pull si l’image n’est pas disponible localement.
Docker gère donc un cache pour les images. Ce cache est local, et il se trouve que nous avons déjà plusieurs fois observé son contenu par la commande docker images. Le cache est tout simplement ce que nous avions appelé jusqu’ici la liste des images locales. Une commande docker pull ne fait que rapatrier en local (donc mettre en cache) une image qui a une existence préalable sur le registre distant.
Comme nous l’avions vu dans le chapitre sur les principes de Docker, instancier un conteneur revient, du point de vue du contenu, à créer une nouvelle couche en écriture sur une pile de couches existantes qui sont accédées uniquement en lecture. En pratique, ces couches sont systématiquement présentes lors du lancement, mais pour des raisons différentes...
Mise en œuvre d’un registre privé
1. Objectifs
Dans la précédente section de ce chapitre sur les images Docker, nous avons longuement exploré les bonnes pratiques pour créer une image, mais finalement peu parlé de comment stocker et mettre à disposition le résultat, hormis une explication de l’importance de Docker Hub dans l’écosystème Docker ainsi qu’une démonstration de sauvegarde d’une pile d’images en un fichier unique d’archive. Dans un contexte un peu plus industriel (ce qui est l’objet du présent chapitre), la manipulation de fichiers d’archive reste une approche un peu simpliste et générant de gros volumes à transporter. D’un autre côté, l’utilisation d’un registre, même aussi sophistiqué que Docker Hub, peut être rédhibitoire pour des raisons de confidentialité. Heureusement, il existe une solution idéale cumulant les avantages des deux solutions, à savoir le registre privé.
Nous avons vu précédemment qu’il était possible de bénéficier dans l’offre gratuite d’un dépôt privé pour une image sur le registre Docker Hub, mais nous parlons ici de créer notre propre registre, et donc de lever cette limitation. Les outils nécessaires sont eux-mêmes gratuits, les coûts résidant dans l’exploitation et l’hébergement éventuel du serveur (ce qui ne veut pas dire qu’ils sont négligeables, loin de là).
Il existe de nombreuses façons de mettre en œuvre un registre privé Docker. Dans les éditions précédentes, nous avons montré comment mettre en œuvre un registre entièrement par nos soins, en utilisant l’application...
Incorporation dans le cycle de développement
Docker est désormais tellement profondément intégré dans le cycle de développement des logiciels que bon nombre d’IDE (Integrated Development Environment, pour Environnement de Développement Intégré en français) incorporent directement la composition de fichiers Dockerfile dans leurs fonctionnalités. On trouvera ainsi de nombreux plugins pour éditer des fichiers selon cette grammaire, mais aussi des intégrations encore plus poussées, à l’intérieur des projets de développement proprement dits.
Il est donc logique de montrer dans le présent livre la façon dont cette intégration peut être réalisée, non pas pour l’expliquer en soi (car comme il s’agit justement de faciliter le travail du développeur, le lecteur n’apprendra rien de plus que ce qui a été expliqué plus haut, lors de manipulations directes du fichier Dockerfile) mais surtout pour illustrer les choix d’écriture et montrer quelles bonnes pratiques sont intégrées dans les fichiers générés. La section ci-dessous expose le sujet de manière théorique et le dernier chapitre montrera l’application pratique des cas les plus standards sur l’application qui servira d’exemple, en utilisant le service Azure DevOps comme support d’usine logicielle.
1. Positionnement de Docker dans une usine logicielle
Docker est très utile dans les usines logicielles : il participe au fonctionnement fluide de l’ALM (Application Lifecycle Management, soit la gestion du cycle de vie des logiciels, de la conception au décommissionnement) en s’intégrant de tout un tas de manières à ces outils.
Il se trouve que les points d’intégration...


