
Mise en œuvre pratique
Présentation de l’application exemple
Les précédents chapitres, bien que basés sur des exemples, montraient surtout une utilisation théorique de Docker. Nous allons dans ceux qui suivent tenter de donner un tour un peu plus industriel à l’utilisation de ces conteneurs. L’idée est de montrer ceci de manière progressive, en partant d’une application exemple architecturée avec plusieurs modules et en faisant évoluer progressivement le déploiement pour qu’il soit entièrement pris en charge par Docker.
1. Architecture
Pour la suite du livre, notre fil rouge sera un ensemble applicatif composé de services, dans une approche SOA (Service Oriented Architecture, c’est-à-dire architecture orientée services). Il ne s’agit pas d’une vraie application industrielle, car la complexité de celle-ci rendrait la lecture plus difficile et au final brouillerait les messages sur Docker. Il ne s’agira pas non plus d’une architecture microservices comme l’application exemple des éditions précédentes, car une saine découpe n’a pas nécessairement besoin d’être très granulaire et l’auteur souhaitait mettre l’accent sur la bonne définition des responsabilités et le couplage lâche autorisé par les approches standardisées. Toutefois, son architecture ainsi que l’infrastructure supportant son développement, sa compilation et sa mise en œuvre seront aussi proches que possible de celles mises en œuvre par l’auteur dans le cadre de sa profession de directeur technique d’un éditeur de logiciels.
L’application est disponible sur https://github.com/jp-gouigoux/TestOIDCBlazorWASM. À ce jour, la version 1.1.0 est la plus adaptée au suivi des exercices...
Adaptation à Docker de l’application exemple
1. Préparation de l’environnement
Pour rappel, le début de l’exercice nécessite de se positionner sur la version 1.1.0 du projet, de façon que le code source ne contienne pas déjà les fichiers nécessaires pour Docker et que le lecteur soit en situation de réaliser les manipulations par lui-même.
Positionnez-vous sur le répertoire TestOIDCBlazorWASM dans lequel le dépôt a été cloné.
Si ce n’est pas déjà fait, positionnez-vous sur la bonne version en tapant la commande suivante :
git checkout v1.1.0 2. Principes de construction
Le reste du présent chapitre est consacré au détail de comment modifier l’application exemple de façon à la déployer dans Docker. Nous allons pour cela utiliser l’environnement de développement intégré Visual Studio 2022 et en particulier la fonctionnalité de prise en charge de Docker :
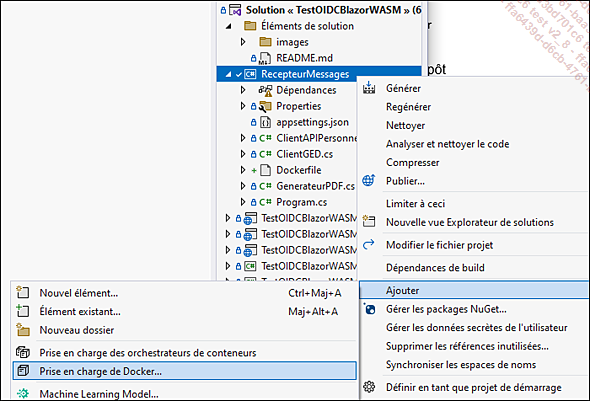
Mais le but ici est bien entendu de comprendre en profondeur les implications de cette simple commande, en décrivant les fichiers Dockerfile et en les adaptant si besoin. Et le fait de traiter l’application complète nécessite aussi de penser à son déploiement d’un seul coup, ce qui rendra nécessaire la création d’un fichier docker-compose.yml.
Enfin, pour compléter une approche qui se veut la plus proche possible d’un déroulement dans un cadre professionnel, le chapitre suivant montrera l’inclusion de tout ce travail dans une usine d’intégration et de déploiement continu, en utilisant une cible de déploiement qui ne sera plus une machine unique, mais un cluster Docker.
L’ordre choisi pour l’explication détaillée des services est celui...


