
Principes fondamentaux
Positionnement de Docker
1. La problématique racine
L’informatique fait appel à de nombreux concepts totalement abstraits et sans lien apparents à une réalité concrète. Les logiciels sont la représentation sous forme binaire d’algorithmes, bref de raisonnements abstraits. Les notions de couches, de niveaux d’abstraction qu’on retrouve dans les programmes mais également pour décrire les réseaux sont elles aussi de pures vues de l’esprit. Bref, l’informatique baigne dans un océan de concepts.
Pourtant, pour que ces algorithmes s’exécutent, des ressources sont nécessaires et celles-ci, bien que présentées parfois de manière abstraite, nécessitent en fin de compte toujours une réalité concrète pour les supporter. Sans puce en matériaux semi-conducteurs, pas de déroulement des programmes ; sans fibre optique elle aussi basée sur du silicium, aucun réseau moderne ; même les réseaux sans fil ne sont pas sans matériel : il reste nécessaire d’utiliser un émetteur, bien concret, et un récepteur Wi-Fi lui aussi tout ce qu’il y a de plus matériel. Et quand on parle d’informatique serverless (sans serveur, en anglais), personne n’est dupe sur le fait que, quelque part, une machine reste indispensable pour réaliser les traitements.
Bref, l’informatique est d’une certaine manière coincée dans le monde réel, et les contraintes associées à cet état de fait peuvent être importantes. À l’échelle d’une machine, la contrainte réside principalement sur la quantité de ressources disponibles.
La mémoire ne sera jamais plus élevée que celle fournie par les barrettes...
Principe des conteneurs
1. Les apports de Docker
L’apport principal de Docker consiste, comme expliqué dans la section précédente, en une réduction drastique des ressources utilisées tout en conservant une étanchéité entre les applications. Encore une fois, les technologies de compartimentation mémoire existaient bien avant Docker. Ce dernier a toutefois apporté un certain nombre de fonctionnalités supplémentaires qui ont permis leur adoption au-delà du cercle restreint des utilisateurs confirmés de Linux.
Au premier rang de ces fonctionnalités se trouve la normalisation des conteneurs : Docker a eu du succès là où des approches purement techniques se sont arrêtées, car il a rendu extrêmement simple la récupération de conteneurs existants et leur création par des méthodes standards. Dans l’histoire de l’informatique, la normalisation et la standardisation ont quasiment toujours été des prérequis à la diffusion large d’une technologie donnée.
L’API Docker est désormais standardisée par le biais de deux spécifications de l’Open Container Initiative, un consortium web ouvert de normalisation de la gestion des conteneurs auquel adhèrent Docker ainsi que de nombreuses autres grandes sociétés d’informatique. La première de ces spécifications concerne la gestion de l’exécution des conteneurs (et donc l’API pour les démarrer, les arrêter, etc.) et la seconde la définition des images.
Le lecteur trouvera plus d’informations concernant la normalisation des interfaces liées aux conteneurs sur : https://www.opencontainers.org/
Il est notable que Microsoft, pour son implémentation de la gestion de conteneurs dans...
Les fondements de Docker
Comme expliqué plus haut, Docker s’est appuyé sur des fondements existants et rencontre un succès certain car il a rendu simple l’utilisation de ces technologies sous-jacentes. Sans rentrer dans les détails (Docker a justement pour but de nous cacher cette mécanique complexe), il convient toutefois de jeter un œil sous le capot pour mieux comprendre le fonctionnement de la machine Docker.
1. Les technologies Linux clés pour Docker
a. Namespaces
À la base de la technologie de conteneurs se trouve la notion de namespace. Ces "espaces de nommage" permettent de créer des ensembles de ressources gérées par Linux alors que, traditionnellement, elles étaient gérées en un seul bloc. Par exemple, les processus sont identifiés par un numéro, accessible dans une liste de tous les processus lancés par le système Linux. On parle d’identifiant de processus, ou PID.
En dehors des namespaces, la commande ps renvoie la liste complète des processus tournant sur la machine Linux. Le principe du namespace est de réaliser des visualisations restreintes de ces ressources, selon une autre logique. Par exemple, dans le namespace 1, seul le processus de PID 10 est visible, et il apparaît sous une valeur de PID local de 3. Dans un second namespace, les processus 11 et 12 sont visibles, mais sous les identifiants 3 et 4.
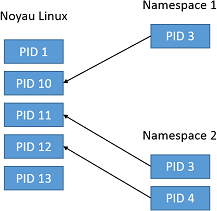
Ainsi, là où le noyau Linux empêche d’avoir le même identifiant pour deux processus séparés, il est possible, à condition de se positionner dans deux namespaces différents, de trouver deux fois le même PID. D’une certaine manière, on peut dire que l’identifiant du processus est en fait namespace1.pid3. En cela, les namespaces fonctionnent un peu à la manière...
Les plus de Docker
1. Au-delà du cloisonnement Linux
La liste des fondations technologiques sur lesquelles Docker s’appuie est, comme vu dans les pages précédentes, particulièrement étoffée. Ceci ne signifie en rien que Docker se contente d’assembler des modules existants, et Docker a eu un grand succès justement parce qu’il a habilement enrobé ces technologies avec des fonctionnalités permettant de les utiliser de manière très simple :
-
Tout d’abord, un format d’image pour démarrer les conteneurs avec un contenu applicatif, qui a rapidement été redonné à la communauté sous forme de standard.
-
Ensuite, un registre prérempli avec des milliers d’images pour la plupart des applications serveurs et, de plus, accessible à tout un chacun pour partager d’autres images réalisées par des particuliers ou des entreprises.
-
Toutes les commandes nécessaires pour gérer le cycle de vie d’un conteneur (lancement, pause, redémarrage, suppression, etc.).
-
Des commandes pour créer et manipuler facilement des images, mais aussi lister les conteneurs et leurs caractéristiques.
-
Une gestion des logs et de l’interaction avec le processus dans le conteneur par les flux standards, qui permet de piloter l’exécution du conteneur au travers d’un terminal interactif exactement comme un utilisateur le ferait pour n’importe quel autre processus.
-
Enfin, la capacité d’exposer des ports, de partager aisément des répertoires, etc.
En plus de ces fonctionnalités, Docker a accompagné, et même précédé parfois, un changement majeur dans les architectures logicielles, désormais plus modulaires. L’expression "philosophie de déploiement"...
Architectures de services
Toutes les sections précédentes de ce chapitre d’introduction ont servi à positionner Docker dans le paysage informatique, à expliquer sur quoi il se basait, son mode de fonctionnement et son écosystème. Dans la présente section se pose la question du pourquoi. À quoi sert Docker, finalement ? Pourquoi cette capacité d’économiser de la ressource, de mettre en commun des couches et d’étanchéifier des conteneurs légers est-elle si importante en pratique ? Bref, quel est ce besoin pratique fort qui a rendu Docker indispensable ?
Il y a de nombreuses raisons à l’explosion de l’utilisation de Docker dès ses premières années, puis à son positionnement comme un standard de facto plus récemment, mais la plupart de ces raisons se regroupent autour du fait qu’elles participent à la mise en œuvre des architectures de services, longtemps complexes à déployer et désormais une réalité en partie grâce à Docker.
1. Historique des architectures de services
a. Principes
La complexification des SI a mis au jour deux principes fondamentaux.
Le premier est que la valeur d’un SI réside plus dans ses interactions que dans ses applicatifs. Une application de caisse enregistreuse ne sert pas à grand-chose si elle n’est pas reliée à la comptabilité. Une application de gestion de paie voit son intérêt singulièrement limité si elle ne peut pas envoyer des demandes de transferts bancaires. Un logiciel de conception assistée par ordinateur est obsolète s’il ne peut pas être associé aux gammes de fabrication par les machines à commande numérique.
Le second principe - qui n’est pas lié qu’à...


