
Les données
Introduction
Comme le mentionnait Axelle Lemaire (secrétaire d’État chargée du numérique et de l’innovation en 2014) : « L’information ne donne pas le pouvoir, c’est l’utiliser qui le procure. »
Cette citation est intéressante dans le sens où les données sont devenues primordiales, on peut même dire vitales, ces dernières années et nous avons appris et continuons à apprendre à mieux les utiliser. Il faut admettre que nous ne l’avions pas réalisé avant et de fait, pas anticipé.
Aujourd’hui, les ressources informatiques qui étaient au centre des traitements et des solutions informatiques ont été reléguées au second voire au troisième plan et les données tiennent la tête de l’affiche. Elles nous sont apparues comme essentielles avec l’avènement des réseaux sociaux et des objets connectés et le contenu toujours plus important qu’ils transportent. Il est à noter que ce contenu n’est aujourd’hui ni complètement exploité, ni complètement exploitable. En fait, seule une infime partie de celui-ci est utilisée.
D’après Earthweb, 2022, 3 % du volume total des données produites serait à ce jour exploité.
Les applications...
Données structurées, non structurées, semi-structurées
Le volume de données que nous devrions avoir stockées sur tous les supports existants en 2035 est de 2142 Zeta Octets (Zo), c’est-à-dire 2142 x 1021 octets.
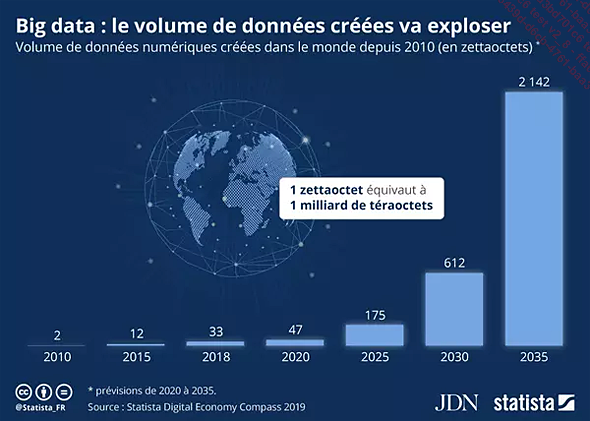
Le volume de données d’ici à 2025
Lorsque je parle de tous les supports, je fais référence aux unités de stockage dans les centres de données et dans les serveurs, aux disques durs, aux bandes, aux microfilms, aux CD et aux DVD, mais aussi aux téléphones intelligents, aux tablettes, aux objets connectés et toutes technologies intégrant un support physique de stockage de données.
Le correspondant anglais de l’octet est le Byte que l’on note « B » à ne pas confondre avec le bit que l’on note « b ». 1 octet = 1 Byte = 8 bits.
En rappel, quelques correspondances en octets :
|
Kilo |
103 octets |
1 ko |
1 000 octets |
|
Mega |
106 octets |
1 Mo |
1 000 000 octets |
|
Giga |
109 octets |
1 Go |
1 000 000 000 000 octets |
|
Tera |
1012 octets |
1 To |
1 000 000 000 000 000 octets |
|
Peta |
1015 octets |
1 Po |
1 000 000 000 000 000 000 octets |
|
Exa |
1018 octets |
1 Eo |
1 000 000 000 000 000 000 000 octets |
|
Zeta |
1021 octets |
1 Zo |
1 000 000 000 000 000 000 000 000 octets |
|
Yotta |
1024 octets |
1 Yo |
1 000 000 000 000 000 000 000 000 000 octets |
Le monde informatique mentionne fréquemment que 1 ko = 1 024 octets et que 1 Mo = 1 048 576 octets, même si cela n’a pas une énorme importance ni incidence, c’est une erreur. L’organisme mondial de standardisation IEEE a d’ailleurs précisé que l’utilisation de ko pour désigner 1 024 octets est erronée, mais tolérée. L’organisme de référence en matière de normalisation des unités dans le monde scientifique (BIPM) et ceux de la normalisation dans le monde technique et industriel (IEEE et NIST) considèrent tous que 1 kilo-octet = 10 puissance 3 (1 000), et non pas 2 puissance 10 (1 024).
Comme je vais l’expliquer dans les sections qui suivent, les données sont scindées en trois types distincts :
-
Les données structurées : elles résident dans des formats et des modèles...
La donnée : une ressource naturelle
La donnée est aujourd’hui considérée comme une ressource naturelle dans le sens où elle est la « nourriture nécessaire au bon fonctionnement de l’informatique cognitive et de l’intelligence artificielle ».
|
La donnée est au centre des systèmes informatiques, c’est un paradigme qui est apparu ces dernières années. |
Avec l’apparition de l’informatique, les entreprises pour concevoir leurs solutions se sont focalisées sur l’infrastructure et les moyens de traitement, qu’ils soient physiques (le matériel) ou logiques (le logiciel). Seules les données d’entreprise étaient considérées et traitées au travers de ces solutions. Aujourd’hui, l’essentiel n’est plus dans les moyens, mais plutôt quelles sont les données dont je dispose et quelle peut être leur utilisation.
Du fait de leur nombre et volume, les données ne peuvent physiquement plus transiter facilement sur les réseaux, il faut dès lors considérer les données différemment. Trois types de données peuvent être définis. Ils sont basés essentiellement sur la localisation des données :
|
1. |
Data@Edge (Data at the Edge) : que l’on peut traduire par « données sur le bord ». Ce sont des données qui vont rester là où elles sont produites. |
|
2. |
Les données distribuées, liées sémantiquement : ce sont des données non structurées qui nécessitent un accès rapide. Elles sont distribuées sur un ensemble d’unités de stockage et sont gérées par un système de fichiers distribué (SFD) ou Distributed File System (DFS). |
|
3. |
Les données classiques stockées dans les centres de données : en général, ce sont des données structurées stockées dans des bases de données classiques, majoritairement relationnelles, mais il existe aussi des bases de données transactionnelles ou des bases de données hiérarchiques, accessibles par des jeux d’instructions fournis par un moteur de base de données. |
1. Data@Edge
Les systèmes...
Les architectures de données liées à l’informatique cognitive
L’objectif de l’informatique cognitive est de tirer parti au mieux du volume important de données qui est généré. Pour ce faire, des architectures de données ont émergé, soit nouvelles, soit enrichissant des modèles déjà existants.
1. L’architecture de Business Intelligence
Elle a été la fondation des outils, méthodes et techniques utiles au « Data Mining » prémisse du « Big Data » qui a son tour a servi de base l’informatique cognitive.
|
Le Data Mining ou exploration de données, fouille de données, forage de données, prospection de données, extraction de connaissances à partir de données, a pour objet l’extraction d’un savoir ou d’une connaissance à partir de grandes quantités de données, par des méthodes automatiques ou semi-automatiques. Elle se propose d’utiliser un ensemble d’algorithmes issus de disciplines scientifiques diverses telles que les statistiques, l’intelligence artificielle ou l’informatique, pour construire des modèles à partir des données, c’est-à-dire trouver des structures intéressantes ou des motifs selon des critères fixés au préalable, et d’en extraire un maximum de connaissances. |
|
Le Big Data désigne des ensembles de données devenus si volumineux qu’ils dépassent l’intuition et les capacités humaines d’analyse et même celles des outils informatiques classiques de gestion de base de données ou de l’information. De nouveaux ordres de grandeur concernent la capture, le stockage, la recherche, le partage, l’analyse et la visualisation des données. |
2. Le Big Data
Il était admis que le Big Data pouvait être défini par 3V : le volume, la variété et la vitesse. Aujourd’hui viennent s’y ajouter trois autres V que sont la valeur, la véracité et la variabilité. Tous ces attributs sont importants et doivent être pris en compte lorsque l’on désire effectuer du traitement sur la donnée.
|
1. |
Volume : il est une composante essentielle... |
La sécurisation des données (non structurées)
La sécurité des données structurées est aujourd’hui connue et assez bien maitrisée. Tout du moins, si on prend conscience de son importance. Dans tous cas, les outils à notre disposition permettront d’agir de manière efficace.
Par contre, les données non structurées ne font pas l’objet du même intérêt, alors que comme on l’a vu précédemment, on estime que 80 à 90 % des données d’une organisation ne sont pas structurées. Une enquête publiée en 2021 par SailPoint montre que la majorité des entreprises n’est pas complètement équipée pour protéger ce type de données. En effet, les entreprises ont peu, voire aucune compréhension de ce qui se passe avec leurs données non structurées (voir dans les sources du chapitre : « Où se trouve l’ensemble de vos données et qui peut y accéder »).
En fait, un des problèmes majeurs est que les entreprises manquent de visibilité quant aux données non structurées dont elles disposent. Elles ne savent pas où elles sont localisées et par conséquent n’ont aucune connaissance des personnes qui y ont accès et surtout l’usage qui en est fait.
En règle générale, beaucoup d’entreprises sous-estiment encore trop souvent les menaces qui pèsent sur ces données non structurées. Pourtant, elles peuvent révéler, consciemment ou pas, énormément d’informations sur l’entreprise : des plans d’acquisition et de fusion, des renseignements concurrentiels, des recherches propriétaires, des données clients et autres données confidentielles....
L’utilisation illicite des données
1. Risques liés à l’utilisation illicite des données
On peut considérer deux utilisations illicites des données qui néanmoins peuvent être parfois interconnectées : l’utilisation illicite des données de l’entreprise ou de l’organisation et l’utilisation illicite des données personnelles.
a. Utilisation illicite des données de l’entreprise
Quels que soient les secteurs professionnels, les entreprises et les organisations détiennent de nombreuses informations ayant une valeur économique et stratégique. Ces informations sont importantes car elles composent le capital immatériel, intangible de l’entreprise. Dans un contexte concurrentiel mondialisé, ce capital permet à l’entreprise de progresser, perdurer, se démarquer de la concurrence, s’adapter aux changements, prendre en compte les besoins multiformes et évolutifs du marché.
Ces informations peuvent revêtir différentes formes et doivent être sécurisées pour éviter d’être volées et utilisées à l’insu de l’entreprise. Elles doivent aussi être marquées comme sensibles, confidentielles afin de les repérer facilement et éviter toutes divulgations non désirées. Ces informations...
Sources et références
Je cite ci-dessous quelques unes des sources que j’ai utilisées pour ce chapitre. La liste n’est pas exhaustive, mais elle recense la plus grande partie d’entre elles.
Introduction
-
Cyril de Sousa Cardoso, Emmanuelle Galou, Aurore Kervella, Patrick Kwok, Data power : Comprenez et exploitez la valeur de la donnée, Eyrolles 2020.
-
Earthweb, statistiques 2022. https://earthweb.com/big-data-statistics/
Données structurées, non structurées et semi-struturées :
-
Abhishek Andhavarapu, Learning ElasticSearch: Structured and unstructured data using distributed real-time search and analytics, Packt Publishing, 30 juin 2017.
-
Alain Couillault,Laurent Le Foll, Valorisation de l’information non structurée, Livre Blanc Apil - Aproged - Cigref, octobre 2007.
-
Alfred Aho, John Hopcroft, Jeffrey Ullman, Structures de données et algorithmes, IIA Informatique Intelligence Artificielle, 31 octobre 1995.
-
Bernard LAUXERROIS, Migration de données : D’un Système d’Information à l’autre : la démarche complète (2e édition), ENI, 2016.
-
Carlos Jaime, L’avenir de la santé repose sur l’exploitation et la valorisation de données structurées, Blog InterSystems, 03 mars 2021. https://www.intersystems.com/fr/impulsions-blog-fr/avenir-sante-donnees-structurees
-
Hritik Raj, What is Semi-structured...
