
Algorithmes d’apprentissage non supervisés
Les tâches en apprentissage non supervisé
L’apprentissage non supervisé permet d’analyser un grand volume de données, sans a priori ce qui est recherché.
Il couvre quatre tâches principales :
-
Le clustering : le but est de regrouper les données en paquets dits clusters, pour mieux les étudier ou les comprendre.
-
La réduction des dimensions : le but est de passer d’un dataset contenant de multiples attributs à un contenant uniquement les attributs les plus importants dans l’explication du phénomène étudié.
-
Les systèmes de recommandation : le but est de conseiller des produits ou des services à des clients en fonction de données historiques.
-
Les associations : le but est de faire le lien entre des évènements, pour créer des règles de type « si A et B alors C dans x% des cas ».
Chacune de ces tâches sera traitée séparément dans ce chapitre, en reprenant le même déroulé : l’explication de la tâche elle-même accompagnée d’exemples, les différentes métriques d’évaluation, les principaux algorithmes et le code Scikit-learn correspondant lorsque la librairie fournit des algorithmes.
La documentation complète de Scikit-learn pour l’apprentissage...
Clustering
1. Définition
Le clustering (ou partitionnement de données en français, même si le terme n’est quasiment pas utilisé) consiste à créer des clusters. Chaque cluster est un ensemble de données regroupées selon leurs similitudes.
Contrairement à une classification, les classes ne sont pas connues à l’avance. C’est à l’algorithme de les déterminer mathématiquement.
Une analyse manuelle est ensuite nécessaire pour associer à chaque classe des labels.
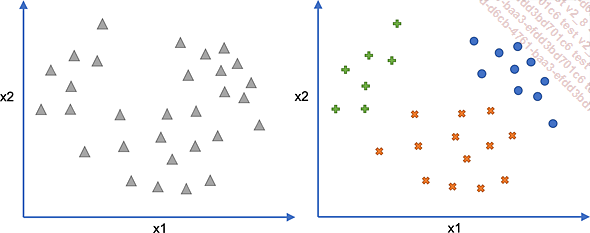
Dans le schéma précédent, les données d’origine (à gauche) sont représentées par les triangles. Un clustering en trois classes (à droite) pourrait donner les catégories suivantes : les croix (x), les ronds (o) et les plus (+).
Dans chaque classe, il y a une cohérence : les points d’une même classe sont proches entre eux. À l’inverse, les classes sont différentes entre elles.
Ici, une analyse des classes permettrait de les définir comme telles :
-
Classe croix (x) : valeur de x2 faible
-
Classe plus (+) : valeur de x2 importante et x1 faible
-
Classe rond (o) : valeur de x2 importante et x1 importante
2. Exemples de cas pratiques
La principale utilisation consiste à analyser des bases de données de clients, de manière à les segmenter en « profils types ». Chaque profil type pourrait ensuite recevoir des offres dédiées selon leurs centres d’intérêt.
Le clustering se retrouve dans d’autres cas d’utilisation, par exemple :
-
Segmentation des produits pour les catégoriser automatiquement sur un site de vente en ligne ou pour trouver des produits similaires.
-
Classification des usages, ce qui permet de différencier des comportements types ou bien potentiellement des usages frauduleux.
-
Sélection de publicités ciblées, en les regroupant par similitude et en proposant les publicités appartenant aux mêmes clusters que les publicités déjà vues et/ou cliquées.
-
Détection d’anomalies, en créant des clusters d’images ou de cas similaires et en marquant comme anomalie toute donnée éloignée des clusters existants.
-
Création de propositions...
Réduction des dimensions
1. Définition
La tâche de réduction des dimensions est particulière. Elle ne sert en général que d’étape dans un processus plus complexe.
En effet, les datasets possèdent souvent de très nombreuses caractéristiques (colonnes). Étudier des données ayant autant d’information n’est pas facile, d’autant plus que les représentations graphiques sont limitées à 3 dimensions.
De plus, pour certains algorithmes de Machine Learning, disposer de trop nombreuses dimensions peut ralentir l’obtention d’un bon modèle (voire rendre impossible l’entraînement si on ne dispose pas de suffisamment de mémoire).
La tâche de réduction consiste donc à prendre un dataset contenant de multiples colonnes et à en sortir les axes principaux limitant le nombre de caractéristiques à étudier.
2. Exemples de cas pratiques
Les deux principaux cas pratiques se rapportent soit à la compréhension/visualisation des données, soit à la préparation des données avant un autre algorithme de Machine Learning.
Dans le cas de la compréhension et/ou visualisation des données, voici les principales utilisations :
-
Visualiser des données complexes, par exemple pour avoir une indication des graphiques les plus parlants et expliquant au maximum les données.
-
Découvrir des tendances non visibles sur les axes initiaux, en faisant des changements de repères qui peuvent permettre de faire apparaître des limites de type linéaire.
-
Estimer le bruit dans des données, en calculant la partie expliquée par uniquement quelques caractéristiques.
Dans le deuxième cas, celui de la préparation des données, voici quelques utilisations :
-
Limiter les dimensions aux principales, pour avoir moins de caractéristiques à prendre en compte ensuite dans le processus, ce qui peut aussi simplifier la préparation (seules les colonnes utiles sont préparées).
-
Éliminer la redondance dans les caractéristiques. La plupart des algorithmes donnent de très mauvais résultats s’il existe des redondances, colinéarités ou corrélations entre les différents...
Systèmes de recommandation
1. Définition
Un système de recommandation (ou recommander system) est un algorithme qui permet de recommander du contenu en fonction d’un historique.
Les systèmes de recommandation se retrouvent sur toutes les plateformes de divertissement :
-
Musiques (Deezer, Spotify...)
-
Vidéos (YouTube...)
-
Films et séries (Disney +, Netflix, Amazon Prime Videos...)
-
Produits (Amazon, Cdiscount...)
-
Contacts ou flux (LinkedIn, Facebook, Instagram...)
-
Formations (LinkedIn Learning...)
-
Etc.
Il n’existe pas d’algorithme directement implémenté dans Scikit-learn. Bien qu’il existe des librairies dédiées, dans la majorité des cas, il est nécessaire de reconstruire les algorithmes en Python (via des comptages et statistiques). Le code sort donc du cadre de ce livre.
Quel que soit l’algorithme choisi, il y a deux cas plus complexes qui seront gérés séparément, sauf mention contraire :
-
Le nouvel utilisateur : comme il n’a encore rien consommé, il est difficile de savoir quoi lui proposer pour commencer. Sur Netflix par exemple, lors de la création d’un profil, l’utilisateur doit choisir des séries qu’il aime pour démarrer les propositions.
-
Le nouveau contenu : comme personne ne l’a encore consommé, il est difficile de savoir à qui il pourrait plaire. Dans la majorité des cas, il sera aléatoirement proposé à des utilisateurs jusqu’à trouver « son public ».
2. Principales approches
a. Modèles basés sur la popularité (popularity-based...
Association
1. Définition
La tâche d’association permet de trouver des liens entre produits qui peuvent être achetés ensemble, comme les pâtes et la sauce tomate, généralement sous la forme pâtes => sauce tomate (indiquant qu’un achat de pâtes entraîne souvent un achat de sauce).
Une fois que ces liens sont découverts, il est alors possible d’agir pour en tirer un avantage.
Par exemple, dans une boutique, s’il existe un lien d’achat entre deux produits A et B, il est possible :
-
De faire une promotion si le client achète A et B.
-
De placer A et B proches physiquement pour que le client achète bien les deux.
-
De séparer au maximum A et B si l’achat est vraiment toujours cumulé, de manière à faire parcourir le maximum de rayons.
-
D’envoyer une promotion sur B aux acheteurs de A.
-
Etc.
La principale utilisation des algorithmes d’association est celle permettant de déterminer quels produits se retrouvent dans un même panier d’achat (association d’achats).
Il existe cependant d’autres cas d’usage de cette tâche : au lieu de produits, elle peut chercher des liens entre des évènements, par exemple pour comprendre quels incidents mènent souvent à un accident. Elle est aussi utilisée en bio-informatique sur des processus complexes, en détection de fraude ou encore en fouille du Web.
2. Évaluation des algorithmes
La tâche d’association produit des règles sous la forme A => B. Pour estimer la qualité de celles-ci, trois indicateurs sont utilisés : le support, l’indice de confiance et le lift.
Chaque partie, A et B, peut contenir en réalité plusieurs éléments. S’il s’agit de A, cela signifie qu’il faut le cumul de chaque élément pour obtenir la conclusion B. Dans le cas où c’est B qui contient plusieurs éléments, cela signifie que la règle a plusieurs conclusions.
Voici par exemple...