
La pile technologique en Python
Les outils de la Data Science
Un bon artisan a besoin de bons outils. C’est également vrai en Data Science et en Machine Learning.
Il existe trois grandes catégories d’outils :
-
Des outils « intégrés » qui contiennent ce qui est nécessaire pour un projet : charger les données, les analyser, créer des modèles, les évaluer, les déployer, créer des rapports…
-
Des outils « Auto ML » qui simplifient le processus pour les non-experts, en automatisant au maximum les différentes phases.
-
Des outils de « développement » avec lesquels il est possible de faire plus de choses, à condition de tout coder, par exemple en Python.
1. Les outils intégrés
Il existe de nombreux outils dans la première catégorie, et chacun nécessite un apprentissage particulier permettant de s’en servir au mieux. De plus, ayant chacun leurs points forts et points faibles, il est important de pouvoir choisir le bon logiciel selon le but recherché.
Il est possible de citer : Dataiku DSS, SAS, QlikView, Tableau, Power BI, Snowflake, etc. Certains sont très orientés statistiques (SAS), d’autres visualisation de données (Tableau), mais tous couvrent au moins une partie du processus. Il s’agit principalement d’applications téléchargeables...
Langage Python
1. Présentation
Python est un langage de programmation dont la première version est sortie en 1991. C’est donc un langage mature, connu depuis longtemps des développeurs.
Il possède plusieurs caractéristiques :
-
Interprété : cela signifie qu’il n’y a pas de compilation avant de pouvoir exécuter le code. Il est donc facile à déboguer mais cela le rend moins efficace en termes de temps d’exécution que des langages compilés comme C/C++. Cependant, la majorité des librairies dites « bas niveau » étant codée en C, le code reste performant.
-
Multiplateforme : un code en Python ne dépend pas de la plateforme sur laquelle il s’exécute, ce qui le rend très portable et facile à partager. Il est en particulier compatible avec Windows, Unix, Mac OS, Android, iOS.
-
Multiparadigme : Python permet différentes formes de programmation et s’adapte donc à la majorité des développeurs. Il est ainsi possible d’écrire :
-
En programmation impérative, forme de programmation la plus ancienne
-
En programmation orientée objet, forme aujourd’hui préférée des développeurs tous langages confondus
-
Et en programmation fonctionnelle, permettant une évaluation de fonctions mathématiques...
Jupyter
1. Caractéristiques de Jupyter
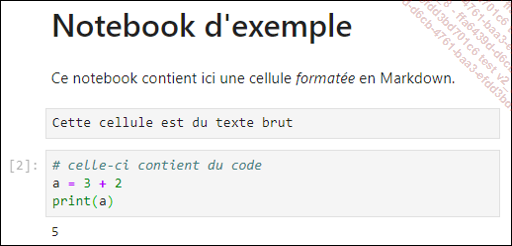
Jupyter est un logiciel qui propose de créer des « notebooks ». Chaque notebook est en réalité une page de taille non fixée, dans laquelle vont s’enchaîner des cellules.
Chaque cellule peut être de différents types :
-
Code, qui pourra être exécuté et dont le résultat s’affichera immédiatement sous la cellule à l’exécution.
-
Texte brut, non formaté et affiché tel quel.
-
Texte en Markdown, pour de la mise en page et même des formules en LaTeX.
Le Markdown est un langage de formatage léger créé en 2004 et utilisé dans de nombreux logiciels. Par exemple, les titres de niveau 1 commencent par #, ceux de niveau 2 par ##, etc. Les textes sont mis en italique et en gras en les entourant d’astérisques : *italique*, **gras**.
Le LaTeX est quant à lui un langage de composition de documents. Fortement utilisé dans les milieux académiques, il permet de dissocier l’écriture du texte de sa mise en page. En effet, celle-ci est calculée lors d’une compilation du texte brut, en respectant les contraintes typographiques et le modèle voulu. Le langage LaTeX est très réputé pour sa capacité à écrire facilement des équations complexes.
Voici un exemple de rendu d’un notebook :
Chaque notebook doit être associé à un kernel. Il s’agit d’un environnement contenant le langage de programmation principal du notebook ainsi que les packages installés. Cela permet d’avoir en parallèle différentes versions d’un même langage.
Il est ainsi possible d’avoir dans le même Jupyter un kernel en Python 3.6 et un en Python 3.9, avec différents modules. En effet, chaque kernel peut avoir ses propres librairies ou des versions différentes de celles-ci, ce qui évite en partie les conflits potentiels.
Actuellement, Jupyter supporte plus de quarante langages dont Python, R, Julia, Scala… De plus, il s’intègre avec Spark, qui permet de gérer des gros volumes de données partitionnés sur plusieurs nœuds.
Le format d’enregistrement des notebooks est un fichier .ipynb qui est en réalité un...
Librairies de Machine Learning
Le langage Python seul n’est ni rapide en temps d’exécution ni facile à utiliser pour faire de la Data Science et du Machine Learning. Il est donc nécessaire de s’appuyer sur des bibliothèques permettant de simplifier le code tout en le rendant plus efficace. En effet, la majorité des frameworks est en réalité codé en C/C++.
L’installation des librairies est assez simple et peut s’effectuer via une commande pip (https://pypi.org/project/pip/) ou via Conda (https://docs.conda.io/en/latest/).
Il est aussi possible de compartimenter les librairies installées par projet grâce aux environnements virtuels, via par exemple virtualenv (https://virtualenv.pypa.io/en/latest/) ou pipenv (https://github.com/pypa/pipenv).
Des extraits de code sont donnés avec la présentation des principales librairies, mais plus de détails seront fournis dans les chapitres suivants.
1. NumPy
La première bibliothèque très utilisée en Data Science date de 1995. Elle facilite la manipulation des matrices et la réalisation des opérations sur celles-ci. Disponible en open source, elle est codée principalement en C, ce qui la rend très rapide.
La majorité des algorithmes de Machine Learning effectue de nombreux calculs matriciels, d’où la présence de cette librairie.
Le site web de NumPy (https://numpy.org/) propose d’accéder aux dernières versions, à des tutoriels et à la documentation de la librairie.
La première caractéristique importante de NumPy est qu’elle inclut un nouveau type de données : les ndarray, pour N-Dimensional Array.
Ces tableaux, représentant en réalité des matrices à N dimensions, ne sont pas dynamiques : la taille doit être choisie avant utilisation et ne peut plus être modifiée ensuite. De plus, ils doivent être homogènes : ils ne peuvent contenir qu’un seul type de données. Cependant, comme il est possible de définir de nouveaux types (via des classes dédiées), il est aisé de pouvoir y stocker ce qui est nécessaire en fonction du problème.
Il existe plusieurs façons de créer un ndarray. Ici nous donnerons directement les valeurs...
Bibliothèques de Deep Learning
De nombreuses bibliothèques de Deep Learning se partagent le marché. Elles sont toutes en open source.
La plupart des librairies proposent les mêmes possibilités. Selon le matériel ou l’architecture choisis, certaines peuvent être un peu plus optimisées que d’autres. Un autre critère de choix peut être la communauté derrière la librairie, pour avoir du support en cas de question.
Les principales librairies sont :
-
TensorFlow, créée par l’équipe Google Brain. Elle est particulièrement optimisée dans le cas d’entraînements distribués sur plusieurs GPU.
-
PyTorch, créée par Meta. La librairie propose de nombreux exemples et cas d’utilisation. De plus, il est possible de compiler les modèles pour optimiser encore plus la phase d’inférence.
-
MXNet, de la fondation Apache et soutenue par AWS et Microsoft (entre autres). Comme TensorFlow, elle est particulièrement optimisée en cas de calcul distribué sur plusieurs CPU ou GPU et s’intègre très facilement dans les différents cloud providers. De plus, cette librairie peut s’utiliser à partir de différents langages, ce qui simplifie l’utilisation des modèles : Python, mais aussi C++, JavaScript, R, etc.
-
Microsoft Cognitive...