
Détection
But du chapitre et prérequis
Le but de ce chapitre est de présenter la détection d’objets. Cette tâche est légèrement plus complexe que la tâche de classification sur laquelle nous nous sommes concentrés jusqu’à présent.
Nous allons d’abord définir la détection, puis présenter les métriques permettant de mesurer les performances d’un réseau effectuant cette tâche. Nous décrirons ensuite le fonctionnement général d’un réseau de détection, puis plusieurs réseaux spécifiques permettant de réaliser la détection seront présentés et comparés.
Enfin, nous parlerons d’une librairie de TensorFlow permettant d’utiliser facilement plusieurs modèles de détection.
Pour bien comprendre ce chapitre, il est préférable d’avoir déjà lu ceux concernant la classification. En effet, les réseaux de neurones utilisés pour la détection sont très semblables à ceux développés pour la classification, et la logique utilisée pour entraîner un réseau et choisir ses paramètres est similaire.
Définition de la détection et spécificités
1. Définition de la détection
L’objectif de la détection est de localiser des objets d’intérêt dans une image.
Comme pour la classification, cela suppose que nous disposions au départ d’une liste de classes qui nous intéressent, par exemple les chats et les chiens. Ensuite, contrairement à la classification, où le but est simplement de savoir si l’image contient un objet d’une des classes d’intérêt, nous cherchons à localiser chacun des objets de chacune de ces classes dans l’image.

Comparaison des tâches de classification et de détection
Plus formellement, la sortie d’un modèle de détection pour chaque image est une liste, dont chaque élément correspond à un objet détecté. La classe et les coordonnées de chaque objet sont renvoyées. La manière précise de représenter les coordonnées d’un objet dépend des modèles, mais ce sont généralement les coordonnées du rectangle englobant qui sont utilisées.
2. Apport de l’apprentissage profond pour la détection
Le concours Pascal VOC, organisé de 2005 à 2012, avait pour but de réaliser la détection d’images sur une base de données ouverte....
Métriques de la détection
1. Indice de Jaccard
La plupart des métriques utilisées pour évaluer la détection se basent sur l’indice de Jaccard (on l’appelle aussi coefficient de Jaccard), qui doit son nom au mathématicien et statisticien français Paul Jaccard. Cet indice permet de distinguer d’un côté les détections correspondant à de vrais objets, et d’un autre côté les détections ne correspondant pas à de vrais objets.
Il est défini comme la taille de l’intersection entre la zone détectée et la zone réelle de l’objet, divisée par la taille de l’union entre ces deux zones.
Cet indice est également appelé IoU, pour Intersection over Union, c’est-à-dire « l’intersection divisée par l’union ».

Le résultat de ce calcul est compris entre 0 (aucun recouvrement entre la détection et l’objet) et 1 (parfait recouvrement entre la détection et l’objet).
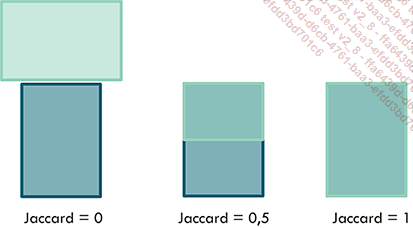
Exemples de détections avec les indices de Jacquard associés
Il est courant de choisir un seuil de 0,5 pour déterminer si l’objet a été détecté ou non.
C’est une mesure qui s’applique à une unique détection : pour chaque détection, il est possible de calculer son indice de Jaccard relatif à tous les objets de la scène qui appartiennent à la même classe que la détection.
2. Vrais et faux positifs, faux négatifs
À partir de cet indice de Jaccard, nous pouvons définir les vrais positifs, les faux positifs et les faux négatifs.
Les vrais positifs sont les détections qui correspondent à un objet avec un indice de Jaccard supérieur au seuil choisi.
Ainsi, dans l’image ci-dessous, la détection 1 a un indice de Jaccard de 0,8. Cet indice étant supérieur au seuil de 0,5, nous considérons que cette détection correspond effectivement à l’objet. C’est un vrai positif.
Les faux positifs sont des détections ne correspondant pas à un objet. Elles sont définies comme des détections qui ont un indice de Jaccard inférieur à 0,5 avec tous les objets de l’image....
Ingrédients généraux des réseaux de détection
1. Localisation et classification
Un réseau de détection d’objets doit effectuer deux tâches différentes : trouver des objets dans l’image, et identifier la classe de chacun de ces objets. Pour ce faire, il existe deux types de stratégies.
La première est basée sur la proposition de régions. Les réseaux l’utilisant opèrent en deux phases successives. Tout d’abord, des régions étant susceptibles de contenir un objet sont définies. Ensuite, un réseau de classification est appliqué à chacune de ces régions, afin d’estimer quelle classe d’objet elle contient.
Ces réseaux sont généralement très précis, mais relativement lents.
La seconde stratégie consiste à réaliser la détection en un seul bloc. Elle est appliquée par des réseaux de régression, qui estiment directement les coordonnées de la boîte englobante et la classe de l’objet à partir de l’image.
Ces réseaux sont généralement moins précis que les premiers, mais ils sont beaucoup plus rapides.
2. Représentation des détections
Les réseaux de détection nécessitent également une manière de représenter la vérité terrain (classe, position du centre et taille de chaque objet) d’une manière utilisable par un réseau de neurones.
En effet, comme nous l’avons mentionné, un réseau ne peut pas donner directement en sortie une liste de taille indéterminée.
a. Ancres
La plupart des réseaux considèrent un nombre fixe de régions dans chaque image, appelées des ancres. Ces ancres sont généralement définies par une taille et une forme donnée, et centrées en chaque pixel d’une version sous-échantillonnée de l’image.

Exemples d’ancres définies en un point. Les mêmes ancres sont définies en tous les autres points d’une version sous-échantillonnée de l’image
Grâce à ces ancres, le problème de détection peut être décomposé en deux sous-problèmes...
Réseaux basés sur la proposition de régions
1. Premières versions
Le premier réseau de cette famille a été proposé en 2014 par Ross Girshick. Dans cette première version, nommée R-CNN (pour Region-based Convolutional Neural Network, ou réseau de neurones convolutionnel basé sur des régions), la première partie, chargée de proposer des régions susceptibles de contenir des objets, était basée sur une méthode de traitement d’images conventionnel, l’algorithme de selective search. Les régions proposées passaient ensuite par un réseau de neurones à convolution pour classifier l’objet représenté dans la région, et ajuster les coordonnées de la région.
Ce réseau était très lent. Le long temps de calcul était tout d’abord dû à l’algorithme de selective search, qui nécessite jusqu’à une minute de calcul pour une image de taille 1024 x 1024, ce qui pouvait être considéré comme rapide en 2014, mais est rapidement devenu plus lent que les autres méthodes disponibles. Une autre raison est que chacune des régions proposées devait passer par le réseau de neurones à convolution pour la seconde étape.
Les années suivantes, les mêmes auteurs ont proposé des améliorations visant à augmenter la performance, tout en réduisant le temps de calcul.
La première amélioration a donné lieu au réseau nommé Fast R-CNN, dont l’architecture permet d’appliquer une seule fois le réseau de neurones à convolution, et plus pour chacune des régions d’intérêt. Cette modification a permis d’accélérer énormément le temps de calcul.
La dernière amélioration a donné lieu à Faster R-CNN, qui est encore utilisé aujourd’hui.
2. Faster R-CNN
a. Architecture générale
Le réseau Faster R-CNN est composé de plusieurs blocs appliqués successivement.
Décrivons tout d’abord rapidement l’architecture générale du réseau, avant de détailler le fonctionnement de chacun des blocs....
Réseaux en une seule passe basés sur des ancres
Plus récemment, des réseaux en une seule passe ont été proposés. Tout comme Faster R-CNN, ces réseaux sont basés sur des ancres.
Nous verrons dans la prochaine section de ce chapitre, Réseaux en une seule passe n’utilisant pas d’ancres, des réseaux en une seule passe qui s’affranchissent totalement du concept d’ancres.
Les réseaux en une seule passe, qu’ils utilisent des ancres ou pas, sont plus rapides que Faster R-CNN, mais généralement moins précis.
1. YOLO
Le réseau YOLO (You Only Look Once, qui peut se traduire par « Vous ne regardez qu’une seule fois ») a été proposé en 2015. Il a été suivi de plusieurs améliorations. La version la plus récente, décrite dans une publication de 2023, est YOLOv8.
Toutes les versions partagent globalement la même architecture générale. Nous allons décrire ici en détail celle de YOLOv3, proposée en 2018, puis nous décrirons simplement les améliorations apportées par les versions suivantes.
a. Principe général
Comme son nom l’indique, c’est un réseau qui réalise un seul passage sur l’image. Il prédit les coordonnées des boîtes englobantes et la classe de chaque objet en une seule fois.
Contrairement à Faster R-CNN, qui consiste en un réseau de localisation suivi par un réseau de classification, YOLOv3 est un réseau de régression pure : à partir d’une image, il estime un certain nombre de valeurs.
La régression est une tâche qui a pour objectif de prédire une valeur continue en fonction d’entrées données.
C’est un réseau purement convolutionnel, c’est-à-dire qu’il ne contient que des couches de convolution. Ainsi, il ne contient aucune couche complètement connectée. Au lieu d’être réalisé par des couches d’agrégation, le sous-échantillonnage est réalisé par des couches de convolution avec un pas supérieur à 1.
Cette caractéristique permet au réseau d’être plus rapide. Elle permet également...
Réseaux en une seule passe n’utilisant pas d’ancres
1. Problèmes des ancres
Tous les réseaux dont nous avons parlé jusqu’à présent utilisent des ancres pour réaliser leurs prédictions. En sortie, ils renvoient donc une prédiction pour chacune de ces ancres. Ceci résulte en une très grande quantité de prédictions (YOLOv3, par exemple, revoie plus de 7 000 prédictions par image), qui doivent ensuite être triées en utilisant l’algorithme de suppression des régions non optimales.
Cet algorithme peut être relativement long, pour deux raisons.
Tout d’abord, comme il regarde chaque paire de détections, son temps de calcul est proportionnel au carré du nombre de détections.
Ensuite, il nécessite d’analyser chacune des prédictions, c’est-à-dire de convertir les vecteurs donnés en sortie par le réseau en boîtes englobantes. Ceci rajoute des opérations supplémentaires, et donc augmente le temps de calcul.
De plus, la définition des ancres ajoute un hyperparamètre à définir : combien d’ancres utiliser, quelles tailles et formes leur donner, etc. Autant de décisions qui affectent à la fois le temps d’entraînement et d’exécution du modèle, et sa performance, et qui sont très dépendantes des données.
2. CenterNet
C’est pour pallier ces inconvénients qu’en 2019, un groupe de chercheurs propose un premier réseau de neurones n’utilisant pas d’ancres, appelé CenterNet.
L’article décrivant cette architecture est intitulé "CenterNet: Objects as Points". La même année, un autre réseau, également nommé CenterNet, a été proposé, dans l’article intitulé "CenterNet: Keypoint Triplets for Object Detection". Il utilise une architecture légèrement plus complexe que le CenterNet dont nous parlons ici, pour des performances moindres. Lorsque vous entendez parler de CenterNet, c’est généralement de ce dernier qu’il est question.
a. Représentation de la vérité terrain
CenterNet représente la vérité terrain...
Comparaison des réseaux de détection
Nous avons vu dans ce chapitre un certain nombre de réseaux de détections, chacun avec ses spécificités. Le but de cette partie est de résumer les différences entre tous ces réseaux, aussi bien en matière de méthodologie qu’en matière de performance.
1. Récapitulatif des réseaux rencontrés
Le schéma ci-dessous résume les points essentiels des réseaux décrits plus haut.
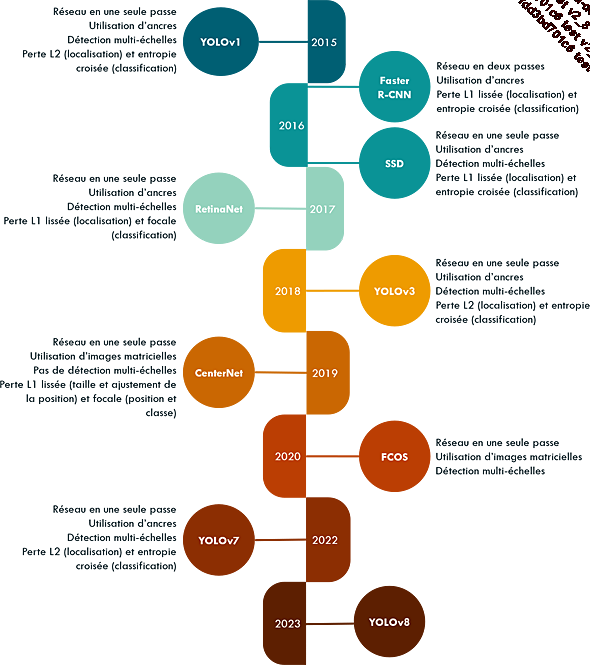
Date de publication et éléments principaux des réseaux décrits dans ce chapitre
2. Comparaison des performances
Comparons maintenant les performances de chacun de ces réseaux.
Contrairement à ce que nous pourrions croire, il est compliqué de comparer directement les performances décrites dans les articles présentant chaque réseau, même si elles sont mesurées sur la même base de données (généralement COCO).
En effet, la performance d’un réseau repose sur deux critères : la précision de ses prédictions, et leur temps de calcul, et tous deux sont difficilement comparables d’un article à l’autre.
Tout d’abord, la précision des prédictions, bien qu’elle soit généralement mesurée via la même métrique...
API de détection d’objet de TensorFlow
La détection est plus complexe que la classification, car ces réseaux comportent plusieurs éléments additionnels par rapport aux réseaux de convolution. De plus, la vérité terrain est également plus complexe, et il n’existe pas de standard concernant son format. De plus, la visualisation des résultats nécessite des fonctions spécifiques.
Ceci explique pourquoi les bibliothèques pour la détection sont plus compliquées à utiliser que celles dédiées à la classification.
Il existe de nombreux modèles de détection disponibles sur GitHub, chacun avec son format et ses spécificités d’implémentation. Utiliser un de ces modèles est approprié pour les utilisateurs expérimentés qui veulent tester un modèle qui vient d’être proposé.
Pour les utilisateurs moins expérimentés, ou qui veulent pouvoir tester une grande variété de modèles sans avoir besoin de changer de format d’entrée, de sortie, ou de type d’utilisation, la bibliothèque proposée par TensorFlow se montre très efficace.
Cette bibliothèque, appelée TF Object Detection, ou TFOD, est spécialement conçue pour la détection d’objets. Elle offre...
Conclusion
Dans ce chapitre, nous avons décrit le fonctionnement général d’un réseau de détection, et décrit en détail plusieurs réseaux.
De nombreux réseaux sont proposés régulièrement, chacun promettant d’être plus rapide et plus précis que tous les précédents ; c’est pourquoi nous avons également présenté des règles permettant de choisir quel réseau utiliser pour votre application particulière.
Le prochain chapitre vous présentera la segmentation. Comme nous l’avons fait pour la détection, nous décrirons tout d’abord les spécificités de la segmentation, puis nous présenterons les modèles les plus utilisés pour cette tâche. Enfin, nous implémenterons notre propre modèle de segmentation basé sur un des modèles décrits.



