
Ouvrir la boîte noire
But du chapitre et prérequis
D’une manière générale, il existe un compromis entre l’interprétabilité d’un modèle d’apprentissage automatique et sa performance : plus un modèle est performant, moins il est interprétable.
Ainsi, les modèles simples tels que les arbres de décision, les régressions linéaires, etc. sont directement interprétables. Ils ne sont cependant pas très performants pour des problèmes complexes.
Les modèles d’apprentissage profond, au contraire, sont très complexes. Ils peuvent être très performants, mais sont très difficilement interprétables directement.
C’est pourquoi plusieurs méthodes indirectes ont été développées pour expliquer leurs prédictions.
Ces méthodes font partie de ce qu’on appelle l’« IA explicable » (explainable IA, ou XAI, en anglais), qui fait l’objet d’importants travaux de recherche.
Dans ce chapitre, nous allons décrire plusieurs catégories de méthodes permettant d’expliquer les prédictions des modèles de classification. Nous expliquerons ensuite comment ces méthodes peuvent être adaptées pour améliorer l’explicabilité des modèles de segmentation et de détection....
Pourquoi ouvrir la boîte noire ?
Mieux comprendre le fonctionnement du réseau entraîné a plusieurs avantages.
Tout d’abord, cela peut permettre d’identifier les limitations du modèle, par exemple en repérant certains de ses biais, ou en identifiant des types de données pour lesquelles il fonctionne moins bien.
Prenons l’exemple d’un modèle de détection des cyclistes, destiné à être embarqué dans une voiture autonome. Une étude du fonctionnement du modèle pourrait montrer que le modèle se base sur la reconnaissance des deux roues pour reconnaître un vélo. Par conséquent, les vélos avec des sacoches cachant partiellement les roues pourraient éventuellement être mal détectés.
Identifier ces limitations peut en retour être utile pour améliorer le modèle. Ainsi, dans l’exemple précédent, ajouter des images de vélos avec les roues partiellement cachées pourrait améliorer la détection dans ces cas-là.
Pouvoir visualiser les rouages internes du modèle permet aussi d’augmenter la confiance des utilisateurs dans ses résultats, et donc l’acceptabilité du modèle.
Visualiser directement le modèle entraîné
Un modèle entraîné est composé de plusieurs couches de filtres qui, appliquées à une image d’entrée, produisent des cartes d’activation.
La méthode la plus évidente pour visualiser le fonctionnement du modèle consiste donc à visualiser ces poids et ces cartes.
1. Poids des filtres
Supposons qu’on entraîne un réseau convolutionnel à classifier les images du jeu de données MNIST. Comme nous l’avons décrit dans le chapitre Outils indispensables à la pratique, ces images représentent des chiffres manuscrits.

Images du jeu de données MNIST
Ce jeu de données est relativement simple à classifier, et un réseau peu profond y suffit généralement. Dans notre exemple, nous avons entraîné un réseau comportant quatre couches cachées :
-
Une première couche de convolution contenant 32 filtres de taille 5x5, suivie par une couche d’agrégation par maximum.
-
Une seconde couche de convolution contenant 64 filtres de taille 5x5, suivie par une autre couche d’agrégation par maximum.
-
Une troisième couche de convolution contenant 128 filtres de taille 5x5, suivie par une autre couche d’agrégation par maximum.
-
Une couche complètement connectée...
Réduire la dimension de la représentation latente de l’image
1. Représentation latente de l’image
La représentation latente de l’image est le vecteur de caractéristiques obtenu en sortie des couches de convolution. Ce vecteur correspond à la représentation des images d’entrée par le modèle, représentation qui est optimisée pour réaliser la tâche pour laquelle le modèle est entraîné.
Visualiser les représentations latentes de différentes images, appartenant à différentes classes, peut donc nous aider à comprendre comment le modèle classifie les images.
Cependant, ces représentations latentes sont généralement des vecteurs de très grande taille. Ainsi, AlexNet produit des vecteurs de caractéristique de taille 4096 ; EfficientNetB0 produit des vecteurs de taille 1280.
Afin de les visualiser, il est donc nécessaire de réduire leur dimension. Si chaque vecteur de caractéristique peut être résumé en un vecteur de deux ou trois dimensions, alors il devient possible de visualiser ces vecteurs sur un graphe.
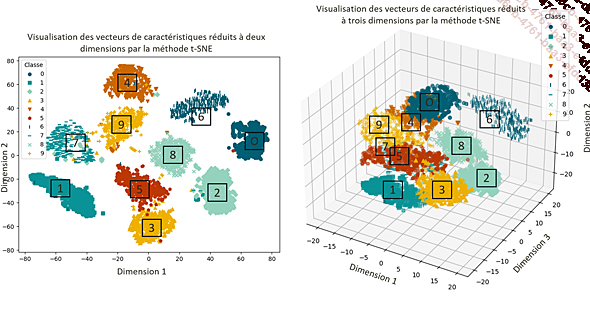
Visualisation des vecteurs de caractéristiques réduits à deux (à gauche) ou à trois (à droite) dimensions
Nous allons maintenant décrire t-SNE, une méthode de réduction de dimension.
2. Réduction de dimension par t-SNE
La méthode t-SNE (t-Distributed Stochastic Neighbor Embedding) est une méthode de réduction de la dimension qui a pour but de préserver la similarité entre les paires de points. Autrement dit, deux points proches dans l’espace de grande...
Visualiser les pixels importants
Les méthodes précédentes offrent une vue d’ensemble du réseau.
Les méthodes que nous allons décrire maintenant ont pour but de déterminer quelles parties d’une image donnée en entrée d’un réseau influent sur la classification.
Elles permettent de construire une image mettant en valeur les pixels les plus pertinents pour une prédiction donnée. Ces cartes sont appelées saliency maps en anglais.
1. Occlusion
Pour déterminer les pixels les plus importants, la manière la plus intuitive est de masquer une partie de l’image avant son entrée dans le réseau, et de calculer la probabilité que l’image soit correctement classifiée.
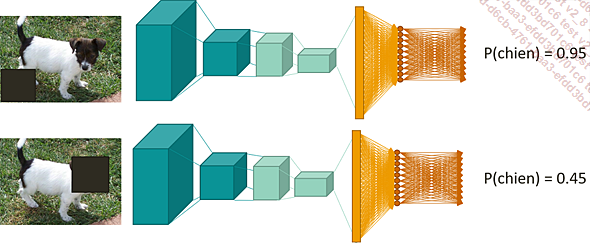
Probabilité d’obtenir la bonne classe lorsqu’une partie de l’image est masquée
Le processus est ensuite répété en déplaçant le masque. Ceci nous permet d’associer une valeur (égale à la probabilité que l’image soit correctement classifiée) à chaque portion de l’image. Une nouvelle image peut alors être construite, dans laquelle l’intensité en chaque portion de l’image est égale à cette valeur.
Ainsi, si nous cherchons à classifier une image contenant le chiffre « 9 », la boucle et la queue du chiffre sont les zones de l’image les plus importantes.

Probabilité d’obtenir la bonne classe selon les pixels masqués
Afin de mieux comprendre quelles classes sont proches les unes des autres, il est possible d’utiliser la même méthodologie pour visualiser la classe la plus probable prédite : nous masquons une partie de l’image avant son entrée dans le réseau, et calculons la classe la plus probable prédite par le réseau.
Si nous considérons la même image de chien que précédemment, nous voyons que, si sa tête est cachée, il risque d’être classifié comme un chat.
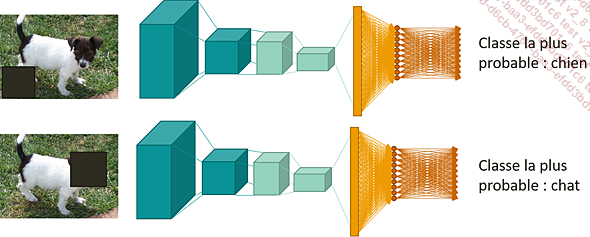
Classe la plus probable prédite par le modèle lorsqu’une partie de l’image est masquée
Là encore, si le processus est répété lors du déplacement du masque, il est possible de voir quelles parties...
Visualiser les modèles de classe ou de neurone
La visualisation de modèle a pour but de générer une image correspondant à ce que le modèle recherche.
Elle peut être utilisée à l’échelle du modèle entier, ou seulement pour un neurone particulier. Pour cela, nous allons générer l’image qui maximiserait le score d’une classe donnée, ou la carte d’activation d’un neurone donné.
1. Visualisation de modèle de classe
La visualisation de modèle de classe (class model visualization en anglais) a pour objectif de générer l’image maximisant le score d’une classe particulière.
Pour cela, il suffit de trouver l’image d’entrée I qui maximise la fonction suivante :
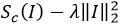
Dans cette équation :
-
Sc(I) est le score de la classe c obtenu par l’image I
-
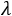 est un nombre strictement positif
est un nombre strictement positif -
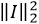 est le carré de la norme euclidienne
de l’image I
est le carré de la norme euclidienne
de l’image I
L’ajout de ce dernier terme permet de régulariser la fonction à optimiser, ce qui facilite son optimisation.
En d’autres termes, le but de la maximisation est d’identifier l’image lisse pour laquelle le réseau prédit la classe c avec la confiance la plus grande.
L’optimisation est proche de celle visant à entraîner un réseau de neurones ; dans les deux cas, l’optimisation...
Explicabilité des réseaux de segmentation et de détection
1. Prévalence des méthodes d’explicabilité pour la classification
Toutes les méthodes présentées jusqu’à présent se concentrent sur la classification, ceci pour deux raisons.
Tout d’abord, les premiers réseaux développés ayant historiquement été des réseaux de classification, il est logique que les premières méthodes d’explication concernent également ces réseaux.
Ensuite, les réseaux de classification ont un plus grand besoin d’explicabilité que les réseaux de détection et de segmentation.
En effet, dans ces premiers, il est difficile de savoir quelle partie de l’image incite le modèle à choisir une classe plutôt qu’une autre. Plusieurs méthodes d’explication ont ainsi pour but d’identifier les pixels les plus importants. Pour la détection et la segmentation, au contraire, ces pixels sont directement visibles.

Cas d’échec de la détection. Dans l’image de gauche, un chat est détecté à tort dans la fourrure du chien. Dans l’image de droite, le chien n’est pas détecté, probablement car ni son visage, ni ses pattes, ni sa silhouette ne sont visibles.
Il est toutefois possible d’appliquer...
Bibliothèques et paquets pour l’explicabilité
Il existe plusieurs bibliothèques et paquets implémentant ces outils :
-
Captum (anciennement Interpretable AI) est développée par Facebook AI Research, et compatible avec PyTorch. Cette bibliothèque implémente plusieurs approches comme LIME, Grad-CAM ou les gradients intégrés.
-
tf_explain est une bibliothèque open source compatible avec TensorFlow. Elle propose des implémentations de Grad-CAM, des gradients intégrés, d’occlusion, et de la visualisation des cartes d’activation.
-
Il existe aussi un paquet nommé lime, contenant une implémentation en python de la méthode LIME.
-
La bibliothèque scikit-learn propose une implémentation de t-SNE.
Enfin, de nouvelles méthodes d’explication des prédictions des modèles sont continuellement développées, et la plupart sont accompagnées d’une implémentation en python disponible sur GitHub. Cependant, il est important de noter que certaines de ces implémentations peuvent ne pas avoir été rigoureusement validées et pourraient contenir des erreurs de code ; elles sont donc à utiliser avec précaution.
Exemple d’utilisation de la bibliothèque tf_explain
tf_explain est une bibliothèque open source proposant plusieurs méthodes de visualisation des pixels importants pour la classification.
Ces méthodes peuvent s’appliquer de deux manières :
-
Comme des fonctions de rappel : elles sont donc appelées à chaque itération pendant l’entraînement, et appliquées à toutes les images de validation. Les images résultantes sont ensuite sauvegardées dans un dossier.
-
Comme des classes avec des fonctions qui peuvent être appliquées à des images individuelles et à un modèle entraîné.
Un exemple de ce dernier usage est présenté dans le notebook ouvrir_la_boite_noire, disponible en téléchargement.
Dans ce notebook, nous allons charger la version 3 du modèle InceptionNet entraîné sur ImageNet, l’appliquer à une image pour prédire sa classe, et utiliser Grad-CAM et les gradients intégrés pour visualiser les pixels utilisés par le modèle pour faire sa prédiction.
Conclusion
Dans ce chapitre, nous avons décrit plusieurs manières d’expliquer les prédictions des modèles de classification :
-
La visualisation directe des poids des filtres et des cartes d’activation. Ces visualisations se révèlent cependant difficiles à interpréter.
-
La visualisation de la représentation latente des images apprise par le modèle (en réduisant ses dimensions par t-SNE). Cette représentation permet de vérifier que le modèle réussit à séparer les différentes classes. Elle peut également aider à repérer les erreurs de labellisation.
-
Les méthodes d’occlusion, LIME, Grad-CAM et des gradients intégrés permettent d’identifier les pixels les plus importants pour une classification donnée.
-
La génération d’images correspondant à ce que le modèle (ou un filtre individuel) recherche.
Toutes ces méthodes permettent de mieux comprendre les limitations et les biais éventuels du modèle. Elles font partie de ce que l’on nomme l’intelligence artificielle responsable, que nous décrirons plus en détail dans le chapitre Intelligence artificielle responsable.
Il faut toutefois garder à l’esprit qu’il est difficile de distinguer les erreurs du modèle des erreurs...



