
Maintenance après déploiement du modèle
But du chapitre et prérequis
Ça y est, vous avez entraîné un modèle d’apprentissage profond pour le traitement d’images. Votre modèle, entraîné sur une grande quantité d’images mises à votre disposition, a fait preuve d’une performance qui dépasse vos attentes, et il est prêt à être déployé. Félicitations !
Votre travail n’est cependant pas terminé. En effet, il est malheureusement très probable que les performances de votre modèle se dégradent avec le temps.
Nous allons voir dans ce chapitre pourquoi c’est le cas, comment surveiller les performances de votre modèle, et les solutions possibles quand celles-ci se dégradent.
Avant de lire ce chapitre, il est préférable d’avoir lu les chapitres Réseaux de neurones à convolution et Bonnes pratiques pour l’entraînement.
Dérive du modèle
Une étude menée en 2018 par Gartner, une entreprise de conseil, a montré que 85 % des projets d’IA échouaient à fournir les résultats escomptés. La plupart des modèles prédictifs voient leurs performances chuter dès la mise en production !
Cette baisse de performance est probable, même si vous avez pris toutes vos précautions pour fournir au modèle des données suffisamment variées et représentatives de la variabilité intraclasse (voir le chapitre Réseaux de neurones à convolution), et même si vous avez pris soin d’éliminer tous les biais et les corrélations fallacieuses potentielles (voir le chapitre Bonnes pratiques pour l’entraînement).
On parle de dérive (ou drift en anglais) du modèle pour qualifier cette perte de performance. Celle-ci peut être graduelle ou brutale, et elle est due au fait que l’environnement du modèle change après son déploiement, ce qui a pour conséquence de faire décroître sa performance.
Cette baisse peut être due à plusieurs causes.
Causes de la baisse de performance
1. Modification des images
La première cause de baisse de performance est liée aux images utilisées en entrée du modèle. Si leurs caractéristiques sont modifiées après le déploiement (par exemple si l’appareil photo utilisé pour acquérir les photographies est modifié, si le protocole d’acquisition change, si la saison ou le lieu d’acquisition est différent, etc.), les performances du modèle vont probablement s’en trouver affectées.
Voici deux exemples :
Tout d’abord, imaginons un capteur installé au-dessus d’une rivière, qui a pour but de détecter les déchets charriés par l’eau (ce genre de projet existe réellement, leur but est de mieux comprendre la provenance des déchets marins). Entraîné en été, ce modèle de détection a vu majoritairement des images où l’eau est bleue. Quand arrive l’automne, l’eau prend une couleur plus brune, ce qui peut potentiellement perturber la détection.
Un autre exemple est la classification d’images médicales, entraînée sur des images acquises par un scanner particulier. Si, après le déploiement, le scanner est remplacé, ou le protocole d’acquisition est mis à jour...
Détecter et quantifier la dérive
Afin de limiter cette dérive, il est important de la détecter le plus tôt possible.
Passons en revue les différentes manières possibles de détecter une éventuelle dérive du modèle.
Nous avons vu que cette dérive pouvait être due à la modification des images ou à la modification des étiquettes, et qu’elle avait pour conséquence une réduction de la performance.
Pour détecter la dérive, il est donc possible de surveiller chacun de ces éléments séparément : les images, les étiquettes, ou la performance.
Si les deux premiers éléments peuvent être surveillés relativement facilement (nous verrons plus précisément comment dans les sections Surveillance des images et Surveillance des prédictions de ce chapitre), la performance nécessite la connaissance de la vérité terrain. Or, après déploiement, la vérité terrain n’est généralement pas connue. De plus, elle est souvent très coûteuse à acquérir. Ce coût peut se traduire en temps de travail, si vous annotez vous-même les images, ou directement en argent, si vous faites faire ce travail d’annotation par une source externe.
Néanmoins, il est recommandé d’acquérir ponctuellement une certaine quantité de vérité terrain, afin de mesurer la performance du modèle sur les données utilisées actuellement.
Dans l’intervalle entre deux surveillances des performances, il faut utiliser des manières indirectes de détecter la dérive.
Détaillons maintenant comment ces différentes surveillances peuvent être implémentées.
1. Surveillance des images
La surveillance de la distribution des images, et notamment la détection d’anomalies, est un domaine de recherche en plein essor.
À partir d’un ensemble d’images de référence, un contrôle continu de toutes les nouvelles images permet de repérer si elles sont similaires aux données d’entraînement, ou si elles semblent être des anomalies.
Notons que le fait que les images soient différentes des images...
Corriger ou compenser la dérive
1. Réentraînement périodique
La solution la plus courante pour contrer la baisse de performance du modèle consiste à réentraîner celui-ci avec de nouvelles images.
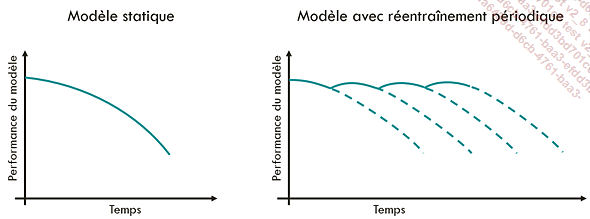
Représentation de l’évolution des performances d’un modèle sans réentraînement (à gauche) et avec réentraînement périodique (à droite)
La question se pose alors de savoir avec quelles données réentraîner le modèle : uniquement avec les nouvelles données ? Avec les anciennes données, auxquelles nous aurons ajouté les nouvelles données ?
Pour répondre à cette question, il est nécessaire de comprendre les raisons de la baisse de performance.
Si les nouvelles images représentent la variabilité normale des images (par exemple, si nous recevons des images issues de plusieurs appareils photo différents, et qu’un appareil additionnel est soudainement utilisé en plus des appareils précédents), alors il est préférable d’ajouter ces nouvelles images aux anciennes images d’entraînement.
Au contraire, si les nouvelles images représentent une évolution par rapport aux images d’entraînement (par exemple, si nous utilisons les images issues d’un unique appareil...
Conclusion
Dans ce chapitre, nous avons vu qu’il était important de surveiller un modèle après déploiement.
Si la vérité terrain est disponible, elle peut être utilisée pour mesurer directement les performances du modèle sur les nouvelles données. Dans le cas contraire, il est possible d’utiliser des indices indirects, comme la distribution des images, ou des prédictions faites par le modèle.
La meilleure manière de surveiller la dérive d’un modèle, et celle de corriger cette dérive, dépend grandement des cas d’usage. Cependant, nous pouvons définir certaines bonnes pratiques qui s’appliquent dans tous les cas.
Tout d’abord, il est important de penser à la maintenance dès la conception du projet. Ceci implique de se poser les questions suivantes : quelle performance est acceptable pour mon modèle ? Avons-nous une idée a priori de la durée de vie du modèle ? Comment surveillerons-nous la dérive ? Comment adapterons-nous le modèle lorsque la performance devient inacceptable ? etc.
Par ailleurs, il est indispensable, dès le premier entraînement, de respecter les bonnes pratiques permettant de s’assurer que le modèle est aussi généralisable que possible. Il faut ainsi veiller à appliquer toutes...



