
Création et gestion d'un cluster Kubernetes
Méthodes d’installation d’une plateforme Kubernetes
1. Plusieurs façons de faire
De nombreux outils existent pour installer un environnement Kubernetes, ce qui peut paraître étrange à première vue, mais correspond à un réel besoin, les usages de la plateforme pouvant être extrêmement différents. Certains outils comme Minikube permettent de configurer un environnement de développement local, dans lequel en guise de cluster, Kubernetes se retrouvera en fait cantonné à une seule machine, donc un seul node. D’autres outils sont spécialisés dans la construction d’un cluster sur des machines virtuelles ou des serveurs physiques (bare metal, selon l’expression anglaise). Enfin, une gamme supplémentaire de méthodes d’installation est portée par les fournisseurs d’infrastructure cloud (Google, OVH, Amazon, Microsoft, etc.) qui ont presque tous désormais leur outil de déploiement d’un cluster Kubernetes.
Quelques questions orienteront l’utilisateur dans son choix de l’outil adéquat en fonction de son contexte d’utilisation :
-
Si l’environnement Kubernetes est prévu à des fins de développement ou de démonstration, alors des outils comme Minikube ou MiniK8s sont indiqués.
-
Si le but est de disposer d’un environnement entièrement administré ou de déployer rapidement des applications sur un cloud, alors il sera pertinent de regarder du côté des offres dédiées sur les plateformes des fournisseurs : Google Kubernetes Engine pour Google, Azure Kubernetes Service pour Microsoft, Elastic Kubernetes Service chez Amazon, etc.
-
Si le besoin est de garder la main sur une infrastructure dans un datacenter privé, ou même sur des serveurs physiques ou virtuels locaux, alors des outils comme Kubeadm ou Kubespray seront idéaux.
Il est crucial, tant pour les administrateurs que pour les développeurs ou les décideurs, de se poser les bonnes questions sur le choix de l’implémentation technique de Kubernetes le plus en amont possible. Celle-ci sera réalisée d’une manière complètement différente (cloud, on premise, mixte ou hybride) en fonction des besoins architecturaux et applicatifs.
2. Environnement de développement
Dans le cas d’un environnement Kubernetes local destiné à des activités de développement ou de démonstration, le choix se fera entre Minikube ou MicroK8s sur des détails de fonctionnalités, car ces deux outils offrent des fonctionnalités assez similaires. L’un comme l’autre permettent de mettre en place un environnement Kubernetes allégé et optimisé, composé généralement d’un simple master assurant aussi le rôle de nœud de travail (worker node).
Une vidéo sur les premiers pas avec Minikube, réalisée par un des auteurs...
Installation d’une plateforme Kubernetes
1. Généralités et préparation
Dans la section précédente, les différentes méthodes d’installation d’une plateforme Kubernetes ont été présentées, mais deux d’entre elles ne méritent pas un réel approfondissement. L’installation d’une plateforme mono-machine avec Minikube se déroule à peu de choses près comme celle de n’importe quelle application, que ce soit sous Linux avec les gestionnaires de paquets ou bien sous Windows avec les assistants graphiques. De même, la mise en œuvre d’un cluster Kubernetes sur un service cloud peut se réaliser en quelques clics seulement et ne nécessite pas d’explications particulières.
Il n’y a donc que pour la mise en place d’un cluster sur des machines gérées par les soins de l’administrateur que des explications du mode d’installation font sens. La section qui suit se consacre donc à ce cas de figure et montre comment mettre en place un environnement Kubernetes hautement disponible selon deux méthodes. La première consistera à utiliser l’outil Kubeadm, qui permet d’installer rapidement et efficacement un environnement de production Kubernetes d’une manière contrôlée et locale. La seconde méthode consistera en une installation d’un cluster Kubernetes de manière automatisée et distribuée grâce à l’outil Kubespray, utilisant des rôles et playbooks Ansible pour effectuer toutes les opérations de configuration de l’environnement de manière automatisée.
L’architecture sera similaire pour les deux méthodes d’installation et constituée de :
-
trois serveurs master : ces serveurs hébergeront les composants d’infrastructure de Kubernetes (Etcd, Controller-Manager, Scheduler, API-Server), et disposeront également du rôle de node, leur permettant de recevoir les planifications de déploiement et d’exécution des tâches des applications correspondantes ;
-
deux serveurs Load Balancer : ces serveurs seront utilisés pour disposer d’un équilibrage de charge sur les flux vers le composant API-Server hébergé par les serveurs master ; ils disposeront d’une adresse IP virtuelle permettant l’accès aux API-Server Kubernetes par le biais du service HAProxy qu’ils hébergeront.
Avant de parler des prérequis techniques puis de passer à l’installation proprement dite avec les deux outils cités ci-dessus, il convient toutefois de présenter les deux méthodes de configuration possibles pour un environnement en mode haute disponibilité, ce qui va être réalisé dans les prochains paragraphes.
a. Description du mode stacked
La première méthode est nommée stacked etcd topology et consiste à déployer sur les mêmes hôtes master (il en faut trois minimum) d’une part les bases de données Etcd qui assurent le stockage distribué des données d’état du cluster et d’autre part les composants d’infrastructure (API-Server, Controller-Manager, Scheduler, etc.). Les accès à l’API-Server pour les nodes comme pour les utilisateurs sont quant à eux fournis par un Load Balancer qui transfère les requêtes aux différents API-Server du cluster.
Le schéma ci-dessous montre une infrastructure Kubernetes distribuée en mode stacked :
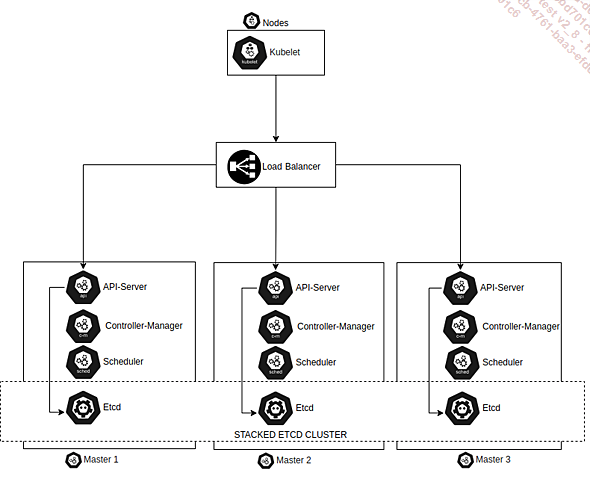
Ce mode de fonctionnement a l’avantage de simplifier la mise en place du cluster et sa gestion. Il comporte par contre un inconvénient majeur dû au fait que la disponibilité, contrairement à ce qu’on pourrait croire, n’est partiellement plus assurée lorsqu’un des serveurs devient indisponible, par exemple à cause d’une corruption système. Le fait que les services d’infrastructure (API-Server, Controller-Manager, Scheduler, etc.) soient distribués sur trois serveurs va effectivement leur permettre...
Mise en œuvre d’un cluster Kubernetes
1. Connexion au cluster
a. Les utilisateurs
Deux catégories d’utilisateurs existent dans un environnement Kubernetes : les comptes de services et les utilisateurs (users).
Les utilisateurs sont gérés par des services extérieurs à Kubernetes comme Keystone, Keycloak ou - plus simplement - au moyen d’un fichier avec une liste de noms d’utilisateurs et de mots de passe. Ils n’ont pas vocation à être créés et gérés par des appels d’API vers l’API-Server, dont ce n’est pas le rôle.
Au contraire des utilisateurs, les comptes de service (service accounts) sont gérés par l’API de Kubernetes. Ils sont liés à des namespaces et peuvent être créés automatiquement via l’API-Server ou manuellement via des appels d’API (par exemple en utilisant le client kubectl, qui peut en créer). Les comptes de services lient un certain nombre d’informations entre elles, à commencer par les Credentials qui sont des informations d’accès, stockées dans Kubernetes dans des ressources de type Secret, présentées dans le premier chapitre.
Les comptes de services peuvent être montés dans les pods afin que ces derniers puissent discuter avec les API de Kubernetes en consommant ainsi l’identité associée. Ils peuvent également être utilisés par des utilisateurs pour se connecter au cluster à l’aide d’un fichier config, comme cela a été démontré dans l’exercice précédent.
b. Modes de connexion
Les appels vers les API Kubernetes (API-Server) sont souvent liés à des utilisateurs ou des comptes de services, mais il est également possible d’envoyer des requêtes anonymes, sans utilisateur ni compte de service associé. Les quelques opérations autorisées selon ce mode seront alors associées à un utilisateur anonyme.
Diverses stratégies sont proposées par Kubernetes pour authentifier les appels d’API, parmi lesquelles l’authentification par certificat, le mécanisme dit token bearer ou encore l’authentification de type basique (Basic Authentification) qui est un des plus vieux standards web.
Pour des environnements de production où le surcroît de paramétrage est justifiable, il est également possible de connecter Kubernetes à des systèmes d’authentification externe comme tout serveur supportant la norme OpenID Connect.
Il conviendra d’éviter l’autorisation des requêtes anonymes permettant à n’importe qui de pouvoir accéder au cluster et donc de créer ou supprimer des ressources non protégées.
Il n’est d’ailleurs pas impossible que cette fonctionnalité soit, à terme, purement et simplement supprimée.
c. Le fichier KUBECONFIG
Le fichier KUBECONFIG est, par abus de langage, le fichier défini par la variable d’environnement nommée effectivement KUBECONFIG, et qui recense les informations d’un client pour accéder aux serveurs master Kubernetes. C’est ce fichier qui est consommé par le binaire kubectl pour se connecter au cluster Kubernetes.
Ce fichier KUBECONFIG correspond au fichier admin.conf des exercices précédents, récupéré après l’initialisation du cluster et recopié dans le répertoire /root/.kube/, sous le nouveau nom de config. En l’absence de variable d’environnement, c’est d’ailleurs dans cette localisation de fichier par défaut ~/.kube/config que les clients iront chercher les informations de connexion.
Le fichier lui-même contient entre autres les informations ci-dessous :
-
Le nom de l’utilisateur.
-
Les certificats clients de l’utilisateur, encodés en base64.
-
Les certificats d’autorité, encodés en base64.
-
L’adresse de connexion au cluster, sous la forme https://IP:port.
d. Gestion des contextes
Le fichier KUBECONFIG peut aussi permettre de mettre en place une organisation lorsque l’on...
Maintien en condition opérationnelle d’un cluster Kubernetes
La dernière section du présent chapitre concerne logiquement, après l’installation et l’exploitation d’un cluster Kubernetes, sa maintenance et les moyens à mettre en œuvre pour que son utilisation puisse se faire de manière efficace dans le temps.
Le monitoring du cluster sera donc réalisé, puis sa sécurisation de fonctionnement par du filtrage réseau et enfin des bonnes pratiques générales concluront le présent chapitre.
1. Surveillance de l’écosystème Kubernetes
La surveillance d’une plateforme Kubernetes nécessite deux types de surveillances pour être complète. Tout d’abord, il est nécessaire d’effectuer une supervision standard des services utilisés par Kubernetes (Kubelet, Docker, etc.) avec des outils connus comme Centreon, Nagios, et bien d’autres encore. Mais, en plus, il est également important de surveiller les applications déployées dans le cluster. Or, le fait que ces applications se trouvent sur un cluster Kubernetes modifie nécessairement la façon dont elles sont supervisées et dont les métriques de consommation sont récupérées. Ceci amène à s’appuyer sur de nouveaux outils de supervision qui seront montrés ci-dessous.
a. Surveillance du cluster
L’objectif de la surveillance du cluster est de surveiller l’intégrité du cluster Kubernetes. L’administrateur en charge du maintien en condition opérationnelle du cluster doit s’assurer que chaque composant et service est en fonctionnement, mais aussi que tous les membres sont opérationnels pour recevoir de la charge applicative et qu’ils ont la capacité (RAM, CPU, stockage) nécessaire pour héberger ladite charge.
Il est également de la responsabilité de l’administrateur de savoir combien d’applications sont lancées sur chaque nœud et en particulier de suivre la consommation globale du cluster afin d’ajuster sa taille si nécessaire.
Ceci inclut l’ajout de nœuds si le cluster atteint ses limites, mais aussi le retrait de nœuds si le cluster n’a pas besoin d’autant de ressources, de façon à limiter les coûts et l’impact environnemental.
Les principaux éléments à surveiller sont les suivants :
-
L’utilisation des ressources des nœuds. Beaucoup de métriques sont disponibles dans cette catégorie comme l’usage des disques, des CPU, l’utilisation de la mémoire vive ainsi que la consommation de la bande passante des interfaces réseau. Un administrateur exploitant ces métriques pourra détecter quand il est nécessaire d’ajouter ou supprimer des nœuds dans le cluster, en contrôlant leur consommation.
-
Le nombre de nœuds existants dans le cluster. Il s’agit d’une information primordiale puisqu’elle permet dans des contextes cloud de connaître la consommation et le coût de l’infrastructure. Cette information permet également de suivre la vitesse de croissance du cluster avec l’ajout et la suppression de nœuds.
-
Le nombre de pods déployés. Bien que les pods n’aient pas tous le même comportement, leur dénombrement global permet de vérifier que les nœuds ont la capacité nécessaire à recevoir toutes les charges de travail prévues.
-
Les services et composants. Cette catégorie consiste à surveiller les services clés de Kubernetes, comme Kubelet, Docker et l’API-Server. Il est essentiel de surveiller les services critiques, car la disponibilité des fonctionnalités offertes par le cluster Kubernetes (création de pods, mise à l’échelle, rolling updates) dépend de leur fonctionnement correct.
-
Les journaux d’évènements seront également à surveiller et à stocker sur des supports assurant une intégrité et une disponibilité à toute...


