
Les grandes solutions de gestion de données
Introduction
Dans les chapitres précédents, on a vu pléthore d’outils ou solutions permettant d’accéder, de déplacer, d’analyser, de redresser, de stocker et de valoriser les données. Cela fait en réalité, beaucoup d’approches et de concepts pour adresser les problématiques de données selon leurs natures et caractéristiques. Certes, cette multitude reflète les différents usages qui permettent de répondre à des besoins multiples et divers, mais cela prouve aussi que la data est un univers très complexe.
Heureusement, on dispose dorénavant d’une boîte à outils et de solutions suffisamment complètes afin de répondre à quasiment tous les cas d’utilisation de données. Néanmoins, si les possibilités d’imbrication de ces outils et solutions sont quasi infinies, on retrouve classiquement de grands patterns d’architecture de données, comme :
-
le Data Warehouse (ou entrepôt de données) ;
-
le Data Lake ;
-
le Lake House ;
-
les solutions de référentiel ou MDM (Master Data Management) ;
-
le Data Hub ;
-
les outils d’EDI.
Le Data Warehouse
Un Data Warehouse est un système centralisé de stockage de données conçu pour agréger et organiser de grandes quantités d’informations provenant de différentes sources. Il permet de faciliter l’analyse et le reporting en rendant les données accessibles et structurées. Les entreprises l’utilisent pour prendre des décisions éclairées en analysant les tendances et les performances historiques. On le retrouve plus dans le domaine décisionnel a contrario des applications ou plateformes d’échanges de données comme le Data Hub qui ont davantage une vocation de gestion de données opérationnelles (données chaudes). La différence est notable puisque l’objectif d’un tel stockage d’informations est de permettre à des utilisateurs d’analyser des données froides (stables) afin qu’ils en déduisent des tendances, qu’ils comprennent des évènements passés ou effectuent des prédictions. Le Data Warehouse est donc un espace de stockage conséquent et souvent redondant qui historise des données opérationnelles déjà existantes.
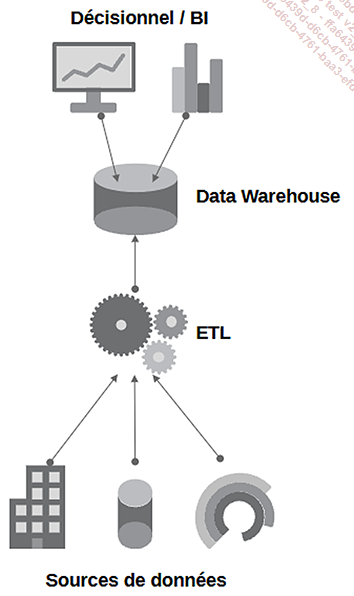
Schéma de fonctionnement du Data Warehouse
Le Data Warehouse porte plutôt bien son nom puisqu’il a pour vocation de stocker dans un espace géant les données stratégiques qui feront l’objet d’une analyse ultérieure. Il s’agit d’y copier de manière régulière les données opérationnelles et de constituer ainsi un historique de données accessible. La conséquence immédiate est que ce Data Warehouse va croître en volume. C’est d’ailleurs cette accumulation de données qui en fait sa richesse.
Dans un Data Warehouse, il est une règle de base qui est de ne jamais modifier les données existantes, mais plutôt d’ajouter de nouvelles informations. Cela garantit l’intégrité et la traçabilité des données historiques. Au lieu de supprimer physiquement des données de la base de données, il est préférable d’opter pour une suppression logique, par exemple en marquant les données à supprimer à l’aide d’un...
Le Data Lake
Un lac de données (ou Data Lake) est un espace de stockage généralisé dans l’entreprise. Sa vocation est de permettre l’agrégation de données de tout type, à tout moment et sans réelles limites. Un Data Lake doit donc permettre et faciliter l’ingestion et le stockage de tout type de données, qu’elles soient structurées, semi ou non structurées. Il doit donc être très flexible et l’immédiate conséquence de cette condition est de ne pas imposer de modélisation.
Pas de schéma de stockage ni d’uniformisation des données, les flux de données entrants se contentent de déposer leurs données dans le Data Lake. La phase d’intégration est donc grandement simplifiée d’un point de vue contrôle mais elle doit en revanche faire face à la contrainte de volume. De plus, le Data Lake doit proposer aux utilisateurs bon nombre d’outils pour trouver, traiter et transformer a posteriori l’information souvent brute qui a été déposée.
Le véritable revers de la médaille d’une telle flexibilité est que le Data Lake peut devenir chaotique. En effet, sans une rigueur stricte de catalogage des données entrantes, le Data Lake peut contenir des données en double, incohérentes, voire totalement...
Le Lake House
Dans certains cas il est impossible de choisir entre Data Warehouse et Data Lake car les deux besoins sont nécessaires. Comment combiner alors les deux approches en une seule ? Le Lake House est né de ce constat. Son concept a concrètement émergé quelques années après l’apparition du Big Data en réponse aux défis rencontrés par les entreprises dans la gestion, l’analyse et l’exploitation de volumes massifs de données diverses (notamment avec la démocratisation de l’IA). Bien que l’idée de combiner les avantages des Data Warehouse et des Data Lake ait commencé à circuler au début des années 2010, le terme Lake House a été popularisé beaucoup plus récemment.
Databricks, une entreprise spécialisée dans l’analyse de données et cofondée par les créateurs d’Apache Spark, a d’ailleurs joué un rôle clé dans la promotion du concept de Lake House. En 2020, la société a introduit cette notion de Lake House dans le cadre de sa plateforme de traitement de données unifiée. Depuis lors, le terme n’a cessé de gagner en popularité.
Il est important de noter que l’évolution des (nombreux) concepts liés à la gestion des données est un processus continu et sans fin. Le terme Lake House continue lui aussi...
Le référentiel de données (MDM - Master Data Management)
Le Master Data Management (MDM) est une technologie utilisée pour gérer de manière centralisée et cohérente les données essentielles et partagées au sein d’une organisation. Il vise à garantir la qualité, l’intégrité et la fiabilité des données critiques telles que les informations clients, produits et partenaires. Le MDM permet aux entreprises de disposer d’une source unique et fiable de données de référence, facilitant ainsi la prise de décisions éclairées et la gestion efficace des processus métier.
1. Introduction
Aborder les référentiels d’entreprise revient à toucher au Saint Graal de la gouvernance pour les données de référence. N’oublions pas l’idée maîtresse de la gouvernance de données : fiabiliser et contrôler la gestion et la connaissance des données dans le temps. On a vu précédemment comment les solutions de gouvernance permettaient de cartographier, auditer et mieux comprendre les données telles qu’elles étaient stockées dans le système d’information. On a aussi abordé les moyens à mettre en œuvre pour fournir une donnée de qualité et de confiance à tout moment. Malgré cela, on se rend vite compte qu’il est complexe, voire impossible, de maîtriser l’inflation de données provenant de multiples sources opérationnelles (comme le Big Data, les capteurs, les IOT, les logs, etc.). Nous faisons face à un enjeu majeur : la maîtrise des données. Pour y parvenir, il est judicieux de commencer par une partie de ces données. Pourquoi ne pas débuter par contrôler la partie la plus stable et constante, à savoir les données de référence ?
En effet, contrairement aux données transactionnelles ou opérationnelles, les données de référence constituent un socle de données de base sur lequel les applications opérationnelles et décisionnelles peuvent et doivent s’appuyer en toute confiance. Les données de référence sont donc le dénominateur...
Le Data Hub
Le Data Hub a pour fonction de faciliter les échanges de données entre plusieurs systèmes disparates à des fins opérationnelles voire décisionnelles (a contrario d’initiatives uniquement décisionnelles). C’est donc un service global et centralisé d’interconnexion des données de l’entreprise. Certains définissent le Data Hub comme une zone virtuelle de stockage. En réalité c’est bien plus que cela car le Data Hub doit pouvoir aussi gérer les échanges à différentes latences entre des applications ou systèmes qui n’ont pas été conçus pour partager des informations.
Les échanges de données étant opérationnels, cela signifie qu’ils sont nombreux et moins volumineux. Cela implique aussi que les temps de réponse (parfois temps réel) sont un aspect important de ce type de plateforme. Initialement, les grandes solutions de Data Hub géraient uniquement les données structurées ou semi-structurées, mais avec l’avènement du Big Data, cela évolue et il n’est plus rare de trouver un Data Hub en amont d’un Data Lake par exemple.
1. Les types de Data Hub
Les Data Hub peuvent être de plusieurs types :
-
Le hub applicatif : au sein d’un applicatif ou d’une solution complexe...
L’EDI
Les EDI (Échange de Données Informatisées ou Electronic Data Interchange) sont des solutions qui ont été conçues pour que des entreprises différentes puissent échanger des données. Le besoin est donc très loin d’être nouveau et les premières solutions d’EDI ont vu le jour dans les années 1980, voire même avant. Ce qui a fait (et continue de faire) leur succès est la notion de standard qui y est bien souvent apposée.
1. Principes de fonctionnement de l’EDI
L’idée de l’EDI est très simple : il doit rendre possible des échanges de données B2B (Business To Business) entre des organisations différentes. Mais, qui dit organisations différentes, dit données différentes, structures différentes, qualités de données différentes, organisations différentes. Il est donc nécessaire de réunir ce que tout oppose.
Il a fallu commencer par définir a minima les protocoles (normes) d’échange de ces données afin de prendre en compte les différentes typologies de données à échanger puis les données échangées elles-mêmes.
On parle de message EDI et de transaction EDI pour nommer les données qui vont transiter entre les différentes organisations. Très concrètement, ces messages EDI sont des fichiers normés (et on verra plus loin qu’il existe aujourd’hui énormément de normes, chacune dépendant du type d’échange et de la nature des données échangées). Ces fichiers normés qui vont transiter peuvent être des bons de commande, des descriptifs de produits, des factures, des demandes de devis, des transactions bancaires, etc.
Quand on parle d’EDI, il faut donc avoir en tête que la plupart du temps des organisations indépendantes ont défini - et sont donc garantes - des normes permettant de mettre en place :
-
la structure et le format des messages EDI ;
-
les transactions EDI et les protocoles associés ;
-
les règles de gouvernance adéquates (notamment en ce qui concerne la qualité de données) ;
-
la sécurité des échanges....
Guide comparatif des solutions de gestion de données
À titre informatif, voici un tableau récapitulatif des différentes grandes solutions de gestion de données et leurs caractéristiques :
|
|
Data Hub |
Data Warehouse |
Data Lake |
MDM |
EDI |
|
Données opérationnelles |
Oui |
Non |
Oui |
Oui |
Oui |
|
Données décisionnelles (analytique) |
Non |
Oui |
Oui |
Non |
Non |
|
Données de référence |
Non (sauf MDM en mode hub) |
Non |
Non |
Oui |
Non |
|
Chargement via ETL/ELT |
Possible |
Oui |
Oui |
Oui |
Possible |
|
Données structurées |
Oui |
Oui |
Oui |
Oui |
Oui |
|
Données semi-structurées |
Oui |
Non |
Oui |
Non |
Oui |
|
Données non structurées |
Non |
Non |
Oui |
Non |
Oui |
|
Gestion de gros volumes |
Non |
Oui |
Oui |
Non |
Non |
|
Modélisation |
Oui |
Oui |
Non |
Oui |
Non (sauf si gestion de cache) |
|
Certification des données (Qualité de données) |
Oui |
Oui |
Non |
Oui |
Partiellement |
|
Intégration de données bidirectionnelle |
Oui |
Non |
Non |
Oui |
Oui |
|
Intégration de données en temps réel |
Oui |
Non |
Non |
Oui |
Oui |
|
Besoin de gouvernance forte |
Oui |
Non |
Non |
Oui |
Non |
Bilan
|
À retenir |
|
|
Aller plus loin |
|
Marché et éditeurs |
|