
Les branches et les tags
Les tags
Un tag est un alias (un nom) défini par un développeur, dont le rôle est de pointer vers un commit. Il permet d’identifier facilement un commit. Les tags sont utilisés pour nommer à des moments précis l’état du dépôt. Les tags permettent d’éviter l’utilisation des hashs SHA-1 qui ne sont pas explicites et difficiles à retenir.
Les tags sont notamment utilisés pour marquer des numéros de versions du projet sur des commits. Les tags permettent également de figer un commit isolé, notamment afin d’empêcher le garbage collector (chargé de supprimer les objets inutiles du dépôt) de le supprimer.
1. Numérotation des versions
Il existe plusieurs manières de noter les versions d’un logiciel. Il n’y a pas de méthode parfaite pour choisir les numéros de versions. Il faut juste rester cohérent avec le système choisi.
Le système SemVer (pour Semantic Versioning) est un système dont la philosophie est de donner un numéro de version qui ait du sens dans le cycle de vie du logiciel. Ce système est utilisé sur des projets de grande envergure comme Python ou Django et est parfaitement adapté à des projets de petite taille.
Le numéro de version se construit à partir de trois nombres séparés de points : x.y.z où :
-
Le x va marquer une version majeure. Une version majeure est une version qui entraîne des modifications importantes dans le fonctionnement de l’application ou encore qui induit une incompatibilité avec une version précédente.
-
Le y va marquer une version mineure. Une version mineure est une version qui ajoute des fonctionnalités tout en conservant une compatibilité avec l’ancien système.
-
Le z va marquer un patch. Un patch correspond à des corrections de bugs sans ajout de fonctionnalités.
Ainsi, on peut imaginer un extrait de liste des modifications...
Les branches
Le système de branches est l’une des fonctionnalités les plus intéressantes de Git. Les branches sont un concept que l’on retrouve dans quasiment tous les autres systèmes de versionning.
Une branche correspond en réalité à une version parallèle de celle en cours de développement. Une branche peut servir à développer de nouvelles fonctionnalités ou encore à corriger d’éventuels bugs sans pour autant intégrer ces modifications à la version principale du logiciel. Les branches permettent de segmenter différentes versions en cours de développement.
Vous utilisez d’ailleurs déjà une branche depuis le début de ce livre, sans forcément y avoir fait attention. Par défaut, lorsqu’on travaille sur un dépôt Git, une branche master est créée. C’est sur cette branche qu’il faut effectuer toutes les manipulations.
En réalité, et à l’instar des tags, les branches sont des alias. C’est-à-dire qu’un tag ou une branche définit un nom sur un commit. La différence entre les deux, c’est que le commit lié au tag est statique là où pour une branche la référence est dynamique.
Ci-dessous se trouve un exemple de système de branches sous forme de graphique. Le projet est un logiciel de comptabilité avec l’enregistrement des commandes clients.
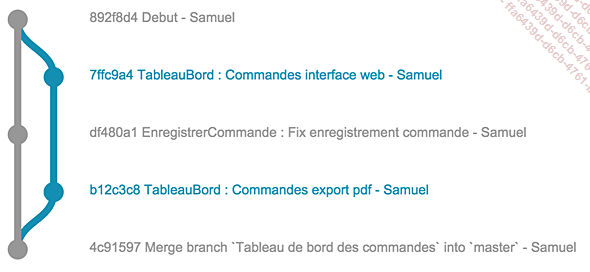
Graphique généré à l’aide de gitgraph.js disponible sur GitHub (https://github.com/nicoespeon/gitgraph.js)
Dans cet exemple composé de cinq commits, le premier représente la branche de développement. C’est dans cette branche que toutes les nouvelles fonctionnalités sont ajoutées.
Le deuxième commit (hash 7ffc9a4) correspond au premier commit après la création d’une branche. Voici les étapes qui ont permis d’arriver à ce commit :
-
Le développeur a créé une branche nommée tableau_bord_commandes à partir du commit 892f8d4.
-
Le développeur a ensuite développé la partie interface web de la nouvelle fonctionnalité et a enregistré ses modifications dans un commit. C’est après...
Mettre à jour des branches dépendantes
La méthode Git-Flow est très utilisée en entreprise. Cependant, comme cela est expliqué au chapitre Git-Flow : workflow d’entreprise, il ne faut pas l’utiliser de façon contrainte, il faut adapter les règles aux besoins de l’équipe.
En effet, parfois il est possible de créer des branches qui dépendent d’autres branches, notamment lors de développement de fonctionnalités. Dans de tels cas, il peut ne pas être évident de savoir comment mettre à jour la branche de fonctionnalité (feature) et la sous-branche de fonctionnalité.
Pour visualiser ce qui peut se passer dans ce genre de cas et tester le comportement de Git, nous allons créer un dépôt et ajouter deux commits :
mkdir git-test-branches
cd git-test-branches
git init
# branche main
echo "Ligne" > file1.txt
git add file1.txt
git commit -m "Commit 1"
echo "Ligne" > file2.txt
git add file2.txt
git commit -m "Commit 2" Nous créons une première branche nommée A et y ajoutons deux commits :
git branch A
git switch A
echo "Ligne" > file3.txt
git add file3.txt
git commit -m "Commit 3"
echo "Ligne" > file4.txt
git add file4.txt
git commit -m "Commit 4" Nous créons une deuxième branche nommée B depuis la branche A et nous y ajoutons deux commits :
git branch B
git switch B
echo "Ligne" > file5.txt
git add file5.txt
git commit -m "Commit 5"
echo "Ligne" > file6.txt
git add file6.txt
git commit -m "Commit 6" Pour les besoins du test, nous créons un nouveau commit dans la branche main. Le but de ce test est de mettre à jour les branches A et B en y intégrant ce nouveau commit.
git switch main
echo "Ligne" > file7.txt
git add file7.txt
git commit -m "Commit 7"
git tag commit-7 Une fois tout cela fait, il est possible de visualiser l’état du dépôt...