
Les données
Rappels
Tous les fichiers utilisés dans cet ouvrage, fichiers source ou fichiers Power BI, peuvent être téléchargés sur la page du site des Éditions ENI consacrée à ce livre depuis l’onglet Compléments.
Dans cette brève introduction, nous allons revoir les notions basiques et quelques évidences de la phase de requête. Pour plus de détails sur ces différents points, je vous renvoie à mon précédent ouvrage, Power BI Desktop, De l’analyse de données au reporting, paru aux Éditions ENI dans sa troisième édition en septembre 2024.
Je vous recommande toutefois de prendre le temps de lire les quelques lignes qui suivent, afin de poser les bases pour la suite du chapitre.
Avant toute chose, rappelons qu’une partie de la phase de requête a lieu avant que celle-ci ne soit envoyée à la source - autrement dit, une partie des actions d’enrichissement de la requête a pour objet d’optimiser celle-ci, et de déporter autant que possible le travail sur la source, pour éviter à Power BI de le faire en local (poste utilisateur).
Une partie de la requête est donc prise en charge par la machine où se trouve la source de données : nous parlons alors de « pliage » de requête pour désigner la part de la requête « traduite...
La préparation de données et le modèle sémantique
La connexion aux sources, les questions d’identification (utilisateur et mot de passe pour accéder à une base), la mise en place de passerelles ou encore la préparation des données (notamment pour des transformations complexes, la combinaison de tables pour construire le modèle en étoile ou lors du recours au langage M) sont toutes des opérations à la fois critiques, complexes et consommatrices de temps.
La délégation de ces tâches à une équipe experte dédiée est donc tout à fait pertinente, et c’est l’une des raisons d’être du modèle sémantique partagé que nous avons évoqué précédemment.
Il n’en reste pas moins vrai que Power Query est un outil formidable, dont l’interface graphique facilite considérablement la transformation des données.
Cas avancés d’import de fichier
Power BI fonctionne avant tout sur un modèle de données tabulaire structuré, à savoir, et pour simplifier, des tableaux composés de colonnes bien séparées avec les en-têtes sur la ligne supérieure, et aucun champ récapitulatif (sous-total, total) - ou encore les colonnes d’une table. C’est le cas pour un fichier Excel simple ou pour une base de données.
Mais Power BI est aussi capable d’interroger des structures plus complexes, des données généralement moins « préparées » et moins propices à une intégration dans le modèle tabulaire.
Il n’est ainsi pas rare d’avoir à intégrer dans Power BI un tableau croisé dont les en-têtes de colonnes ou de lignes présentent une structure complexe, par exemple des champs fusionnés, des totaux ou des en-têtes sur plusieurs lignes.
Un autre cas de figure intéressant est celui d’une structure en sections, où les tableaux de données sont répartis dans différentes sections, et où la mise en forme tabulaire peut s’avérer délicate.
Importer un tableau croisé complexe
Fichier source : chapitre01_sources.xlsx, feuille tableau croisé complexe.
Le tableau que nous allons intégrer présente le nombre trimestriel de commandes pour différents clients, de 2023-T1 à 2025-T2 :
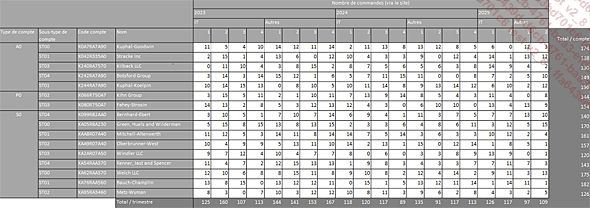
Ce type de structure rend impossible toute analyse dans Power BI. Il est nécessaire de mettre ces données « à plat », et de se débarrasser des éléments superflus : totaux en ligne et en colonne, cellules fusionnées, et en-têtes de colonnes sur plusieurs lignes.
Notons aussi que ce tableau est évolutif : il est probable que le troisième et le quatrième trimestre de 2025 s’ajouteront par la suite, et il est nécessaire d’anticiper leur apparition.
Après avoir lancé Power BI, allez dans l’onglet Accueil - groupe Données, cliquez sur le connecteur Classeur Excel, parcourez vos dossiers jusqu’à trouver le fichier chapitre01_sources.xlsx, puis cliquez sur Ouvrir.
Sélectionnez la feuille tableau croisé...
Les tables de dimensions transverses et les modèles de rapport
Qu’est-ce qu’une dimension transverse ?
Les modèles de source de données orientées BI reposent sur deux types de tables principaux : les tables de faits qui contiennent les données quantitatives (montants, quantités ou dénombrements par exemple) et les tables de dimensions qualitatives (clients, produits ou temps par exemple).
Un tel modèle aura donc une structure dite « en étoile », avec la table de faits au centre et les dimensions autour (comme des rayons).
Les tables de dimensions peuvent être spécifiques à un métier ou besoins particuliers (elles ne sont utiles que pour ce rapport), ou être communes à plusieurs rapports : ce sont des dimensions transverses, ou conformes (c’est comme ça que les appelle R. Kimball, qui a posé les bases de la modélisation dimensionnelle).
Plutôt que de recréer ces dimensions transverses dans chaque rapport, il peut donc être très pertinent - pour des raisons de qualité de données, de maintenance - de les mutualiser, autrement dit de les rendre disponibles en amont du rapport.
Il existe différentes façons d’implémenter cette approche :
-
Les tables peuvent être créées dans la source elle-même (approche centrée sur l’entreprise), et dans ce cas elles seront importées avec les autres données.
-
Les tables peuvent être générées dans un flux de données Flux de données Gen 2, c’est-à-dire la version web de Power Query, accessible depuis Power BI Service.
-
Et une autre solution consiste à les intégrer à un « modèle » de rapport qui sera utilisé comme base pour la création de nouveaux rapports.
Dans ce chapitre, nous traiterons les deux derniers cas avec comme exemple la table du temps, dont la présence dans votre fichier Power BI est essentielle.
Les dimensions transverses et les flux de données
Flux de données Gen 2 est la version web de Power Query. Vous y accédez à partir de Power BI Service, et créez ce flux dans un espace de travail Fabric.
Flux de données Gen 2 utilise donc le langage M. Voici le code...
Éléments du langage M
Présentation générale
Objectif et intérêt de ce chapitre
Nous allons découvrir le code M à travers un ensemble d’exemples concrets et utiles : vous apprendrez à injecter du code dans la requête, vous commencerez à manipuler les fonctions M et vous serez en mesure de découvrir par vous-mêmes d’autres utilisations et d’autres fonctions de ce langage.
Les cas que nous verrons ensemble relèvent de plusieurs catégories :
-
Exécuter un script technique
-
Afficher le dictionnaire des fonctions M
-
Capter une information qui n’existe que dans Power Query
-
Extraire la date d’actualisation
-
Exécuter un script pour accélérer le temps de préparation
-
Renommer plusieurs colonnes d’un coup
-
Nettoyer un champ Texte
-
Créer une fonction personnalisée
-
Exécuter un script pour rendre dynamique la requête
-
Changer facilement la source de données à l’aide de paramètres
-
Définir une période à l’aide de paramètres
-
Associer les paramètres et les modèles de document
Ces cas seront traités dans le chapitre consacré aux paramètres, où ils prennent tout leur sens.
Outre ces cas, vous constaterez que les manipulations proposées par la suite (le web-scraping, l’agrégation, l’utilisation de paramètres) impliquent a minima de savoir lire ce code, et bien souvent de savoir le modifier. En revanche, l’objectif de cette section n’est pas d’acquérir une connaissance approfondie, permettant d’écrire intégralement le script, mais de savoir s’appuyer sur celui que génère automatiquement l’interface : l’utilisateur de Power Query qui saura utiliser intelligemment l’interface et le code maîtrisera un outil d’une redoutable efficacité.
Rappelons d’abord que Power Query est une UI (interface utilisateur) dont l’objectif est de générer simplement du code M afin de construire la requête qui sera ensuite - au moment où vous cliquez sur le bouton Fermer & appliquer - envoyée en partie ou en totalité à la source.
Comme toute UI, celle de Power Query se concentre sur les fonctionnalités...
Comprendre l’actualisation incrémentielle
Pourquoi utiliser l’actualisation incrémentielle ?
Lors de l’actualisation d’un rapport, l’intégralité des données présentes dans le rapport (E) est effacée et remplacée par l’intégralité des données présentes dans la source, c’est-à-dire l’ensemble E (dont certains enregistrements ont pu être modifiés) plus les nouveaux enregistrements (apparus depuis la précédente actualisation).
C’est ce remplacement complet du jeu de données qui peut, à mesure qu’augmente le nombre d’enregistrements dans la source, allonger la durée d’actualisation du rapport.
Il est possible de mettre en place des stratégies d’actualisation pour agir sur ce point : découper une grande table en plusieurs sections et n’actualiser que la dernière section, en prenant en compte la possibilité que les anciens enregistrements puissent être modifiés. Imaginez par exemple une très grande table dans laquelle sont stockés les passages en caisse pour un hypermarché. Les transactions, une fois enregistrées, ne changent pas, à moins qu’un client ne ramène un produit. Si la politique de retour est limitée à 7 jours, il est possible, moyennant quelques contorsions de la requête, de ne récupérer qu’une partie des enregistrements (après le 7 de chaque mois, uniquement ceux du mois en cours ; avant le 7, ceux du mois en cours et ceux du mois précédent).
Le principe ici est de découper la requête en fonction de la période...
Importer des données web : le web-scraping
L’extraction de données issues du Web a pris énormément d’ampleur et Power BI accompagne ce mouvement, en proposant quatre possibilités pour récupérer l’information, de la plus simple à celle qui va vous amener à travailler le code de la requête, en passant par l’aide qu’apporte l’intelligence artificielle de Power BI.
Extraire un tableau
C’est l’exemple d’extraction le plus basique, et il sera donc traité très brièvement.
Si la page dont vous fournissez l’adresse présente explicitement un ou plusieurs tableaux, le connecteur web de Power BI va les identifier et vous n’aurez qu’à choisir dans la liste celui ou ceux qui vous intéressent.
Cette technique a déjà été décrite dans mon précédent ouvrage, Power BI Desktop Reporting et analyse de données au quotidien (3e édition), en voici un bref rappel :
Ouvrez Power BI et, dans l’onglet Accueil - groupe Données, cliquez sur le bouton Obtenir les données puis choisissez Web.
Saisissez ou collez l’adresse https://fr.wikipedia.org/wiki/Population_mondiale dans la fenêtre, puis validez.

Utilisez l’accès anonyme et cliquez sur Se connecter.
Power BI analyse la page et propose l’ensemble des tableaux HTML (identifiés par le langage HTML) ou suggérés (par l’IA de Power BI).
Sélectionnez, par exemple, Évolution depuis 1950 et cliquez sur le bouton Transformer les données.
Le reste de cette démarche consiste à opérer certaines transformations (lignes d’en-tête, dernière ligne, type des données) qui ne présentent aucune difficulté particulière.
Extraire une liste structurée implicite
Si le cas précédent illustre un cas simple, ce n’est pas le plus fréquent. Les données sont en effet souvent présentées sous forme de liste plutôt que de tableau : c’est le cas par exemple des résultats de recherche ou encore des listes de produits d’un catalogue.
Pour ce type de page, Power BI propose une nouvelle approche, basée en partie sur l’IA....
Comprendre et appliquer le modèle en étoile
Si Power BI a d’abord séduit les utilisateurs d’Excel, qui y voyaient un outil complémentaire, il est essentiel de sortir de la logique Excel et d’adopter des pratiques de conception propres à Power BI afin d’exploiter pleinement ses capacités :
-
des performances meilleures (sur des volumes de données importants) ;
-
des formules DAX simplifiées ;
-
une approche adaptée à la manière dont fonctionne le moteur interne.
Le modèle en étoile est en outre particulièrement apprécié par Copilot lors de l’interrogation de données, ou lors de la création de formules DAX.
Ce chapitre est, par conséquent, entièrement consacré au modèle de données - c’est-à-dire à la façon de structurer les tables et leurs relations, en s’appuyant sur Power Query et sur la vue Modèle de Power BI.
Nous verrons pourquoi, par exemple, la grande table importée d’Excel, ou construite à partir d’un fichier texte, n’est pas une bonne idée. Mais nous verrons aussi qu’importer telles quelles les tables d’une base de données n’est pas non plus toujours une bonne pratique.
En définitive, Power BI fonctionne de manière optimale en s’appuyant sur une structure de tables bien spécifique - le modèle en étoile, dont nous allons détailler les caractéristiques et voir la mise en œuvre concrète, à partir de différents scénarios.
Quand (où) faut-il dessiner l’étoile ?
La règle est simple : plus c’est près de la source, mieux c’est.
Autrement dit, si le modèle en étoile peut être construit directement dans la base de données, c’est parfait. Si beaucoup d’utilisateurs y accèdent pour créer leurs rapports sous Power BI, alors c’est parfaitement justifié (en termes de coût, de temps de développement, de maintenance).
Si ce n’est pas envisageable, la deuxième option est de construire le modèle dans Power Query : la requête sera pliée, en partie ou totalement, et c’est donc la base source qui fera les calculs.
Power Query...
Agréger les tables avec Power Query
Définition de l’agrégation
L’agrégation est une technique d’optimisation qui consiste à créer une nouvelle table (la table d’agrégat) en résumant une table source (la table détaillée ou table de faits), ou encore en regroupant les colonnes provenant de plusieurs tables du modèle.
Le grain, ou la granularité, est une indication du niveau de détail d’une table : la table source a un grain plus fin que la table agrégat. Par exemple, la première peut indiquer des transactions au niveau journalier pour un produit, et la table d’agrégat peut consolider les chiffres soit au niveau journalier pour une catégorie de produit, soit au niveau mensuel pour le produit, soit encore au niveau mensuel pour une catégorie de produit.
Il y a en effet de nombreuses façons d’agréger les données, et il est possible d’avoir plusieurs tables d’agrégats dans le modèle.
La table de détail possède un très grand nombre de lignes, alors que la table d’agrégat en possède beaucoup moins, selon un facteur qui peut varier considérablement (de 1 à 1000, 10 000, 100 000, etc.). Plus le nombre de lignes est réduit, plus l’accès aux données est rapide, et moins la table occupe de place dans le modèle.
C’est le besoin en reporting, ainsi que le public visé, qui déterminent le recours à un ou plusieurs agrégats. L’exemple typique veut que plus le destinataire occupe une position élevée (direction générale), plus la vision est globale (« gros » grain). Et en revanche, plus le destinataire est proche de l’opérationnel, plus le niveau est détaillé.
La table agrégée peut être créée :
-
Dans la source de données elle-même : c’est le meilleur choix, mais il n’est pas toujours possible. Dans une base de données, les agrégats sont fréquents, créés par les équipes informatiques.
-
Dans Power Query : c’est un bon choix, car les calculs, qui peuvent être lourds, vont dans la plupart des cas être effectués...
Utiliser Copilot et l’IA générative pour la préparation des données
Après l’IA prédictive, utilisée depuis longtemps déjà en association avec le décisionnel, c’est au tour de l’IA générative de venir en appui de votre travail - et, à termes, de complètement transformer la manière dont nous interrogeons les données.
Il y a deux façons, aujourd’hui, d’utiliser l’IA générative avec Power BI : utiliser ChatGPT, c’est-à-dire vers une IA hors de l’application, ou appeler Copilot, directement dans Power BI, et même dans votre fichier.
Une IA générative va être en mesure de vous donner des conseils, qui seront pertinents dans la mesure où vous lui avez décrit en détail la structure de votre modèle (pour la préparation des données), ou, plus simplement, vous lui avez passé une image du modèle sémantique (une fois celui-ci prêt, et de préférence en étoile).
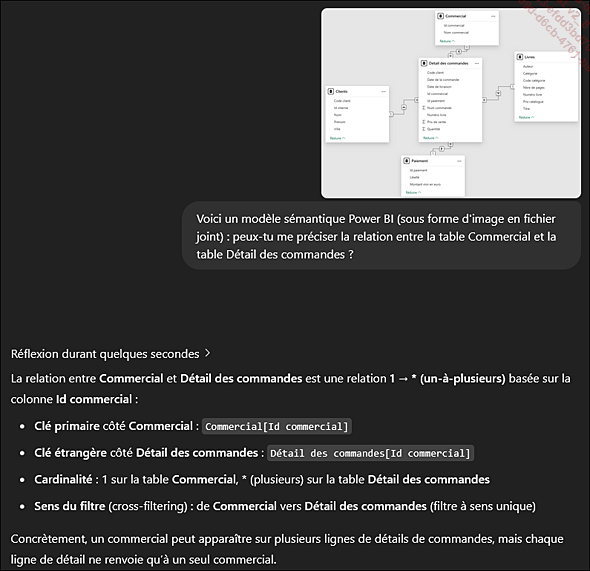
Dans la mesure où l’IA est capable de comprendre le modèle, elle pourra répondre à vos questions
En revanche, l’IA générative hors Copilot ne pourra pas effectuer d’actions, comme faire une transformation ou créer une table : c’est là un avantage incontestable de Copilot. Étant directement intégré à votre fichier Power BI, Copilot va pouvoir faire ce que vous lui demandez.
Notez toutefois que pour pouvoir utiliser Copilot, il faut que votre rapport ait été au préalable publié dans un espace Premium (ou de capacité Fabric), ou que votre flux Gen2 (voir ci-après), soit créé dans un espace Premium (ou de capacité Fabric).
Où trouver Copilot : les flux de données Gen2²
Ce chapitre n’a pas vocation à décrire en détail le processus, mais à proposer une approche, des prompts et des exemples.
Pour la préparation des données, Copilot n’est pas (encore) disponible dans Power Query, il faut passer par la version web de cet outil, à savoir les flux de données Gen2. Le flux, une fois publié, sera accessible...