
Interactions web
Notions de base
1. Page HTML et arborescence
La page HTML est composée de balises qui structurent la page entre les données et les déclarations pour aider le navigateur à les présenter. Lors de l’étape de parsing de la page, le navigateur construit une arborescence de nœuds faisant partie de l’API DOM. Travailler avec l’API DOM revient donc à travailler avec l’arborescence de votre document.
La spécification DOM est définie par le W3C (World Wide Web Consortium) : https://www.w3.org/
DOM est une API généraliste de manipulation d’arborescence, elle peut être utilisable avec HTML / XML. Elle est déclinée pour tous les langages supportant l’objet comme Java, C#, C++...
Exemple
<!DOCTYPE html>
<html>
<head>
<title>Hello World</title>
</head>
<body>
<h1>Ma page</h1>
</body>
</html> Est interprété par le navigateur comme cette arborescence :
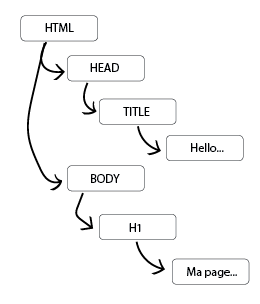
Figure 1 - Arborescence DOM
Voici la représentation sous la forme d’une arborescence de notre exemple HTML (figure 1). C’est cette représentation qui sera exploitée par le navigateur. Le passage de la version texte (les balises que vous saisissez) à la version par arborescence est faite par l’intermédiaire d’un parseur HTML interne au navigateur, cette opération est transparente à l’utilisateur et est effectuée au moment du chargement de la page.
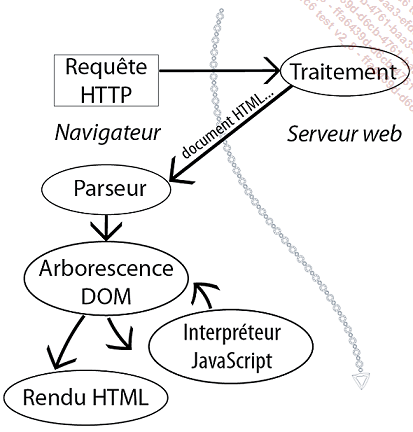
Figure 2 - Traitement d’une requête
Voici un résumé en figure 2 de ce qui se passe côté serveur et côté client lors d’une requête pour obtenir la page HTML.
Pour que l’interpréteur JavaScript vous permette l’utilisation de l’arborescence DOM, il faut être déjà certain que la lecture de la page est bien terminée (donc le parsing a été fait).
L’arborescence est accessible à partir d’un objet document toujours à disposition.
Lorsqu’un nœud est associé à une balise, on parle aussi d’élément.
Voici un contre-exemple
<!DOCTYPE html>
<html>
<head>
<title>Erreur...Modification de l’arborescence
1. innerHTML
La modification de l’arborescence DOM intervient pour effectuer des effets graphiques mais également pour mettre à jour votre page avec des données obtenues par les technologies AJAX/fetch par exemple.
Il existe différentes techniques de modifications d’une arborescence, la plus simple consiste à utiliser la propriété innerHTML. Celle-ci fonctionne à la fois en lecture et écriture et correspond au code HTML associé à l’intérieur d’un nœud.
Attention, la balise qui englobe le tout n’est donc pas prise en compte.
Dans l’exemple ci-dessous, nous allons mettre à jour le contenu d’une balise au chargement du navigateur.
Date est une classe prédéfinie pour travailler avec les dates et heures comme nous l’avons vu au chapitre précédent. Par défaut l’objet obtenu est initialisé à la date et heure système.
Il existe également une fonction toLocaleDateString qui prend en compte le pays pour l’affichage de la date.
Figure 6 - Résultat
Comme cela fonctionne en lecture, nous pouvons donc lire un code HTML avant de le modifier.
<!DOCTYPE html> <html>
<head>
<title>Modification DOM par innerHTML</title>
<script>
function modifNoeud() {
let d = new Date();
let tmp = document.getElementById( "date").innerHTML;
tmp = tmp.replace( "$1", d.getHours() );
tmp = tmp.replace( "$2", d.getMinutes() );
document.getElementById( "date").innerHTML = tmp; ...Interactions utilisateur
1. L’événement
Nous avons déjà évoqué l’usage d’onload pour connaître l’état de chargement de la page. onload joue le rôle de passerelle entre ce qui se passe dans la page et votre code JavaScript. Cela correspond à la notion d’événement. L’événement est une information qui ne peut être connue à l’avance et qui arrive suite à un changement généralement provoqué par l’utilisateur. Par exemple, onload est le résultat de l’action de chargement de la page par l’utilisateur. En captant ces événements, il est alors possible de rendre une page HTML vraiment interactive et de la transformer en application.
Il existe deux manières de gérer un événement, la première plus ancienne et limitée à des usages rapides consiste à passer du code JavaScript à un attribut HTML dédié. La deuxième un peu plus complexe, mais plus adaptée à un développement moderne et facilement maintenable en séparant bien présentation et traitement est l’usage de la méthode addEventListener.
Nous allons prendre l’exemple d’un clic de souris, il deviendra un attribut onclick en HTML et sera un événement...
Promesses
1. Principes
Les promesses vont nous servir à gérer de manière uniforme des traitements assez lourds qui ne doivent pas bloquer l’utilisateur d’une page HTML. Par exemple, vous avez une page HTML qui a besoin d’obtenir des informations d’un service météo, vous ne voulez pas bloquer l’affichage de cette page en attendant l’actualisation des données.
Prenons le cas d’une IA, vous avez un réseau de neurones d’une certaine taille que vous interrogez pour résoudre un problème, il n’est pas question de bloquer l’intégralité de la page HTML utilisée en attendant car cette dernière peut aussi offrir d’autres services utiles. Ces traitements sont dits asynchrones, car ils vont s’exécuter pendant que la page continue à s’exécuter normalement. C’est un peu comme si vous aviez une machine dédiée capable de travailler en arrière-plan.
Ce que cherche à normaliser une promesse est un cas assez simple, si nous exécutons un traitement asynchrone, il nous faut bien savoir à un moment si ce traitement a produit un effet ou pas. Cela va reposer sur une forme d’abonnement unique, on va exécuter un traitement si le traitement asynchrone a été traité.
2. La classe Promise
Une promesse est un traitement asynchrone qui sera soit garanti de succès, donc réalisé à un moment, ou bien soit qui ne pourra pas se réaliser (erreur ou timeout…). Comme il ne sera pas exécuté dans le moment, il faudra qu’un traitement lui soit associé puis exécuté pour indiquer qu’il a bien eu lieu et éventuellement la même chose en cas d’erreur.
Tout cela, se traduit par l’usage d’un objet de classe Promise. En argument du constructeur, on fournira une nouvelle fonction qui sera exécutée automatiquement par la classe mais qui prendra elle-même en arguments une fonction de traitement quand l’opération sera effectuée et une fonction pour prendre en compte une erreur. C’est à l’intérieur de cette fonction que le traitement asynchrone aura lieu. Ensuite, on utilisera autant de fois que nécessaire les méthodes...