
Les fondamentaux de l’intelligence artificielle
Ce que nous allons découvrir

Dans un monde où l’intelligence artificielle redéfinit les paradigmes technologiques, maîtriser ses fondamentaux est plus que jamais une compétence centrale pour les professionnels de l’IT.
Ce chapitre s’inscrit dans une démarche pédagogique visant à vous permettre une compréhension approfondie des concepts clés de l’IA, de ses classifications, de ses technologies sous-jacentes et de son impact sur les métiers de l’informatique. L’objectif est simple : vous donner les clés pour naviguer avec aisance dans un environnement en constante évolution.
Nous commencerons par explorer dans ce chapitre les bases de l’IA en évoquant la distinction entre IA faible et IA forte, avant de plonger dans les approches symboliques et connexionnistes, piliers historiques de l’IA.
Nous mettrons bien évidemment en lumière l’émergence de l’IA générative et de ses applications révolutionnaires, notamment à travers les Large Language Models (LLM), capables de produire de manière autonome du texte, des images et bien plus encore.
Ces LLM, tels que GPT-4, Claude ou Mistral, représentent l’incarnation d’un aboutissement technologique en constante évolution, qui repose sur des avancées clés dans l’apprentissage...
Classification de l’intelligence artificielle
Pour bien comprendre le paysage complexe de l’intelligence artificielle, il est essentiel de classer les différents types de systèmes qui la composent. Cette classification permet non seulement de distinguer les niveaux de sophistication des différentes IA, mais aussi de cerner leurs capacités, leurs limites et leurs applications potentielles. Elle éclaire également les enjeux éthiques et les défis techniques propres à chaque catégorie. Dans ce qui suit, nous explorerons les principales classifications de l’intelligence artificielle, en détaillant leurs caractéristiques et en illustrant leurs applications concrètes. De l’IA réactive aux systèmes apprenants, en passant par la théorie de l’IA forte et de l’IA faible par laquelle nous allons commencer, nous en examinerons les différentes facettes.
1. L’intelligence artificielle faible
L’IA faible, également connue sous les noms d’IA étroite, de Narrow AI ou plus régulièrement de ANI, fait référence à des systèmes conçus pour mener à bien une tâche précise de manière intelligente. Ces systèmes sont considérés comme monotâches car ils sont conçus pour accomplir une unique tâche spécifique. L’IA faible se définit par la simulation d’un comportement humain, mais avec des contraintes qui limitent son champ d’action à la tâche à accomplir. Elle est experte dans son domaine de prédilection, mais ses capacités sont limitées et ne peuvent pas être généralisées à d’autres domaines.
Les systèmes d’IA faible sont très courants et peuvent être trouvés dans de nombreux aspects de notre vie quotidienne. Par exemple, les systèmes de recommandation utilisés par les sites de commerce en ligne pour vous suggérer des produits en fonction de vos préférences, ou bien encore les chatbots (programmes informatiques conçus pour simuler des conversations avec les humains)qui nous aident à résoudre des problèmes ou à obtenir des informations, les moteurs de recherche qui nous...
L’intelligence artificielle générative
Nous y voilà. Plongeons-nous désormais au cœur d’un domaine fascinant et en pleine expansion : l’IA générative.
Oubliez les algorithmes traditionnels cantonnés à des tâches prédictives. L’IA générative, c’est la capacité pour une machine de créer, d’innover et de produire du contenu original, qu’il s’agisse de texte, d’images, de musique, de code informatique ou même de design 3D, en soi tout ce que nous, êtres humains, avons déjà su produire.
L’IA générative repose sur ce que l’on appelle des réseaux neuronaux profonds. Retenez simplement à ce stade que nous sommes sur une technologie qui s’inspire du fonctionnement du cerveau humain. C’est ambitieux certes, mais ça marche car ces derniers sont entraînés sur des quantités massives de données. Ce processus d’apprentissage permet alors de générer de nouvelles données, inspirées par les données d’apprentissage, mais fondamentalement originales.
Une IA générative ne donnera généralement pas deux fois le même résultat. Ces modèles utilisent souvent des processus aléatoires pour générer du contenu, ce qui conduit à des variations même avec les mêmes entrées. Cela permet de produire une diversité de résultats créatifs. Toutefois, certains modèles peuvent être configurés pour générer des résultats identiques en fixant une « graine » aléatoire spécifique.
Imaginez un artiste s’imprégnant de différents styles picturaux avant de créer sa propre œuvre. L’IA générative fonctionne de manière similaire, en synthétisant l’information pour produire un résultat unique.
Un aspect crucial de l’IA générative est sa capacité « multimodale ». Cela signifie qu’elle peut opérer sur différents types de données, parfois même simultanément.
Par exemple, une IA générative pourrait être capable de générer...
Le Machine Learning
Plongeons désormais au cœur des modèles fondamentaux d’intelligence artificielle, en commençant par l’apprentissage automatique (Machine Learning ou ML), pilier central de l’IA moderne.
Nous explorerons ses algorithmes clés et leurs applications pratiques. Ensuite, nous nous pencherons sur le traitement du langage naturel (NLP) qui permet aux machines de décoder et d’interagir avec le langage humain. Puis, nous aborderons l’apprentissage profond (Deep Learning ou DL), une sous-catégorie du Machine Learning qui utilise des réseaux de neurones complexes pour résoudre des problèmes plus sophistiqués.
Au fil de cette section, nous analyserons la manière dont chacun de ces modèles contribue à l’évolution rapide de l’IA et ouvre des perspectives révolutionnaires, en illustrant chaque concept par des exemples concrets et des cas d’usage pertinents. Nous verrons également comment ces modèles s’articulent entre eux et comment ils peuvent être combinés pour créer des systèmes d’IA encore plus puissants. Préparez-vous à découvrir les rouages de ces technologies et à comprendre leur potentiel transformateur.
1. L’interconnexion entre IA générative, LLM et Machine Learning
L’intelligence artificielle générative, et plus particulièrement les modèles de langage à grande échelle (LLM), représente une avancée majeure dans le domaine de l’IA. Les LLM, tels que GPT-3, GPT-4, Claude 2 et Llama 2, utilisent des réseaux de neurones profonds pour comprendre et générer du texte de manière autonome. Ces modèles s’appuient sur les principes fondamentaux du Machine Learning et du Deep Learning pour apprendre à partir de vastes quantités de données textuelles.
Pour entraîner un LLM, il est essentiel de lui fournir une quantité massive de données textuelles. Wikipédia, avec ses plus de 58 millions d’articles dans près de 300 langues, est une source inestimable pour cet entraînement. Les articles de Wikipédia couvrent un large éventail de sujets, offrant aux modèles une exposition complète...
Les réseaux de neurones (Neural Networks)
Nous avons exploré les bases du Machine Learning et ses divers systèmes d’apprentissage. Il est maintenant temps de plonger dans une composante essentielle de l’intelligence artificielle contemporaine : les réseaux de neurones. Bien que cet élément puisse sembler complexe, nous allons le rendre accessible et compréhensible.
Qu’est-ce qu’un réseau de neurones ? Est-il inspiré par le fonctionnement du cerveau humain ? La réponse est oui. Les réseaux de neurones artificiels s’inspirent du cerveau humain, qui est composé de milliards de cellules appelées neurones. De même, un réseau de neurones artificiels est constitué de petites unités appelées neurones artificiels. Ces neurones interagissent pour continuer à apprendre et résoudre des problèmes de manière similaire à notre système nerveux. Chaque neurone reçoit des informations, les traite puis les transmet à d’autres neurones. En collaborant, ces neurones artificiels peuvent apprendre à accomplir diverses tâches, comme identifier un animal dans une image.
On peut faire un parallèle avec notre apprentissage d’enfant par exemple lorsque nous avons appris à reconnaître les formes géométriques. Nos parents nous enseignaient à distinguer un carré d’un cercle et notre jeune cerveau a progressivement compris la différence. Les réseaux de neurones fonctionnent de manière comparable, apprenant par expérience et ajustements successifs pour améliorer leur compréhension et performance.
À retenir : les réseaux de neurones sont l’une des méthodes d’apprentissage automatique.
L’apprentissage des réseaux de neurones peut être comparé à l’apprentissage d’un nouvel instrument de musique par une personne. Au début, cela peut sembler complexe, mais à force de pratique, nous devenons de plus en plus compétents. De la même manière, les réseaux de neurones « écoutent » des tonnes d’exemples pour apprendre et s’améliorer.
Dans le domaine de l’intelligence...
Le traitement du langage naturel (NLP)
Le traitement du langage naturel est une branche de l’intelligence artificielle qui se concentre sur l’interaction entre les ordinateurs et le langage humain. Son objectif est de permettre aux machines de comprendre, interpréter et générer du langage humain de manière aussi naturelle que possible. Pour les professionnels de l’IT, le NLP ouvre un champ d’opportunités considérable pour optimiser les systèmes d’information et créer des applications innovantes.
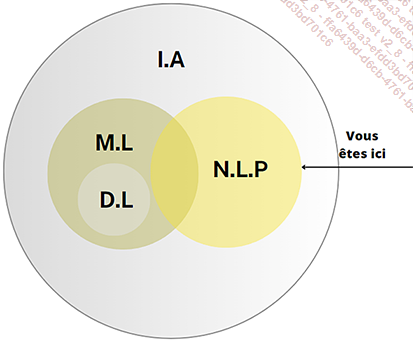
L’histoire du NLP remonte aux années 1950, avec les premiers travaux sur la traduction automatique. Les progrès significatifs ont cependant été réalisés ces dernières décennies grâce à l’essor du Machine Learning et du Deep Learning. L’utilisation de réseaux de neurones profonds a notamment révolutionné le domaine, permettant des performances remarquables dans des tâches telles que la traduction, la génération de texte et l’analyse de sentiments. Des projets phares comme GPT d’OpenAI, BERT de Google et RoBERTa de Facebook illustrent l’importance croissante du NLP dans le paysage actuel de l’IA.
Le NLP se divise en deux sous-domaines principaux :
-
La compréhension du langage naturel (NLU - Natural Language...
Le Deep Learning : apprentissage profond
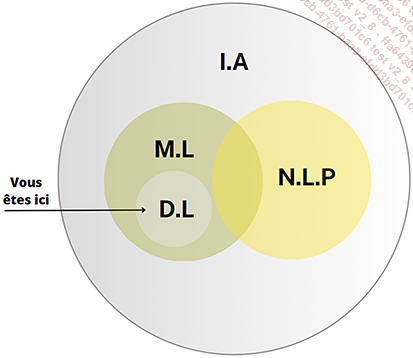
Le Deep Learning, sous-domaine du Machine Learning, est une technologie d’intelligence artificielle (IA) qui permet aux machines d’apprendre de manière autonome à partir de données massives, afin de résoudre des problématiques complexes. Pour les professionnels de l’IT, le Deep Learning représente un outil puissant pour transformer les systèmes d’information et créer des applications innovantes. Un analyste métier, par exemple, peut exploiter le Deep Learning pour automatiser l’analyse de données clients et prédire les tendances du marché, optimisant ainsi les stratégies marketing et commerciales.
L’histoire du Deep Learning est intrinsèquement liée à celle des réseaux de neurones artificiels, dont les fondements théoriques remontent aux années 1940 avec les travaux de McCulloch et Pitts. Cependant, c’est au début des années 2000 que le Deep Learning a véritablement pris son essor, grâce aux avancées technologiques telles que l’augmentation de la puissance de calcul des GPU, permettant l’entraînement de réseaux neuronaux profonds et le développement d’algorithmes d’apprentissage plus performants.
Le Deep Learning s’inspire du fonctionnement du cerveau humain, où...
Zoom sur les Large Language Models (LLM)
Continuons à descendre dans les profondeurs de l’IA et plus particulièrement ici vers les LLM, acronyme que nous utiliserons désormais pour parler des Large Language Models.
Nous venons de présenter dans le début du chapitre les diverses classifications, nous avons ensuite abordé les enjeux de l’IA générative et tout son potentiel dans le but de créer des contenus originaux de par son approche multimodale permettant, à partir d’un entrant, quelle qu’en soit sa forme, d’obtenir une création numérique, qu’il s’agisse de son, d’image ou de texte.
1. Définition technique des LLM
Les LLM représentent une avancée cruciale en intelligence artificielle. Ces systèmes sont dotés de la capacité d’analyser et de générer du langage humain de manière cohérente, ouvrant la voie à des applications innovantes qui vont bien au-delà de la simple interaction homme-machine. Par exemple, ils peuvent être utilisés pour la génération automatique de contenu, la traduction instantanée ou bien même la rédaction de textes complexes comme des scénarios de films ou articles scientifiques.
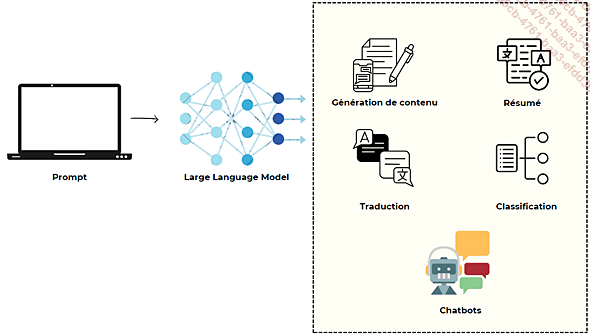
Il s’agit d’un type d’intelligence artificielle entraîné sur des quantités astronomiques de texte, lui permettant de comprendre les nuances du langage, de générer du contenu pertinent et même de traduire entre différentes langues.
L’IA générative est un type d’IA qui inclut les LLM mais aussi d’autres types d’IA tels que les Transformers, GAN et VAE vus précédemment, ceci dans le but de créer du contenu original, comme des images, de la musique ou bien encore des vidéos.
Pour générer du contenu nouveau, les IA génératives telles que Mistral, Claude, Llama ou encore ChatGPT vont préalablement passer par une phase d’apprentissage durant laquelle elles vont ingérer une quantité de données à plus ou moins grande échelle.
Par exemple, des modèles de langage comme ChatGPT peuvent être entraînés sur des milliards de mots provenant de diverses sources comme...
Le RAG, architecture et cas d’usage : l’exemple Google
Continuons maintenant notre chemin dans l’exploration technologique de l’intelligence artificielle à partir de l’exemple Google avec sa plateforme d’IA Vertex AI, ceci afin de vous expliquer une nouvelle notion essentielle dans votre quête d’apprentissage à l’IA : le RAG.
Le workflow de l’IA générative commence, vous le savez désormais, par un prompt : une requête envoyée au modèle de langage d’IA générative pour obtenir une réponse en retour grâce aux LLM et à leur capacité à générer du contenu de manière cohérente et contextuelle. Jusqu’à présent rien de bien nouveau.
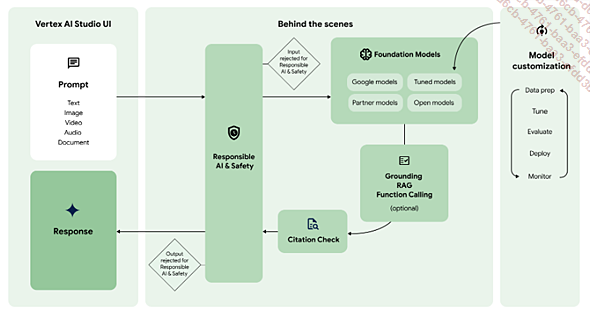
Cependant, les LLM ont des limites, notamment en termes de capacité à traiter des informations complexes et à prendre en compte des connaissances spécifiques et contextualisées à un domaine.
C’est là que l’architecture RAG (Retrieval-Augmented Generation) entre en jeu.
Le RAG combine les capacités des LLM avec celles des systèmes de récupération d’informations (IR) pour générer des réponses plus précises et plus pertinentes et contextualisées.
L’architecture RAG se compose de trois étapes :
-
Retrieve : à cette étape, le système récupère des informations pertinentes à...
Fine-Tuning
Le Fine-Tuning marque une avancée clé pour personnaliser les modèles de langage selon les exigences métier.
Cette technique permet de personnaliser un modèle existant pour des cas d’usage précis, offrant ainsi une solution sur mesure pour diverses applications métier.
Dans les faits, le Fine-Tuning consiste à réentraîner un modèle préexistant sur des données spécifiques à un domaine ou une tâche particulière. Contrairement à l’apprentissage traditionnel, cette approche conserve les connaissances générales du modèle tout en affinant sa compréhension pour un contexte spécifique.
Un exemple concret serait l’adaptation d’un modèle pour le support technique IT dans un système d’information. En utilisant des milliers de tickets de support résolus comme données d’entraînement, le modèle peut apprendre à générer des réponses techniques précises et pertinentes, en utilisant la terminologie appropriée du domaine.
Cet apprentissage nécessite toutefois quelques considérations pratiques pour l’implémentation, le volume de données nécessaire étant de fait la première des clés. Pour une tâche simple comme la catégorisation de tickets incidents, environ 500 exemples peuvent suffire. Pour des tâches complexes comme la génération de documentation technique, plusieurs milliers d’exemples sont recommandés. Dans le cas d’applications critiques comme l’analyse de logs de sécurité, on peut aller jusqu’à des dizaines de milliers d’exemples.
Le Fine-Tuning nécessite des ressources significatives et un budget conséquent. Un projet typique de Fine-Tuning peut coûter entre quelques centaines et plusieurs milliers d’euros, selon la taille du modèle et le volume de données.
Dans un contexte d’entreprise...
Conclusion
Dans ce chapitre, nous avons exploré les bases essentielles de l’intelligence artificielle, en fournissant un cadre solide pour comprendre ses différentes facettes.
En partant des distinctions fondamentales entre les différents paradigmes d’IA, nous avons progressivement dévoilé les mécanismes qui font des systèmes génératifs une rupture technologique majeure.
Les architectures comme les Transformers et les LLM ne représentent pas simplement une évolution technique, mais bien une nouvelle façon d’envisager l’interaction entre machines et connaissances humaines.
L’analyse des technologies sous-jacentes en partant des principes du Machine Learning aux subtilités du NLP nous a permis de comprendre comment ces systèmes dépassent les limitations des approches d’IA traditionnelles. Le RAG, en associant recherche contextuelle et capacité générative, ouvre la voie à des applications plus précises et actualisées.
Le Fine-Tuning, quant à lui, permet d’adapter ces technologies puissantes aux spécificités de chaque domaine métier.
En tant que professionnel de l’IT, il est crucial de saisir ces concepts non seulement pour leur valeur technique, mais aussi pour leur impact stratégique. C’est d’ailleurs précisément...




