
Analyse et amélioration des modèles
Simplification des programmes
 Ch04_1-MNIST_MLP-Apprentissage-v2.ipynb Ch04_1-MNIST_MLP-Exploitation-v2.ipynb
Ch04_1-MNIST_MLP-Apprentissage-v2.ipynb Ch04_1-MNIST_MLP-Exploitation-v2.ipynbDans le chapitre précédent, pour faciliter la compréhension, nous avons choisi de coder le perceptron en restant au plus près de la description visuelle du réseau de neurones. Maintenant que les notions de base sont comprises, des modifications peuvent être apportées pour alléger le code.
Les deux notebooks associés à cette section intègrent ces évolutions.
1. Format des images
La méthode .reshape() était utilisée pour adapter le format des images à celui des entrées du réseau :
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784) Cette manière de procéder n’est pas idéale, car si d’autres traitements sont à réaliser sur les images (affichage, symétries…), la représentation en vecteur ne convient pas. Il est préférable de les conserver sous une forme matricielle avec l’ajout d’un traitement Flatten en entrée du réseau. Il s’agit d’une couche particulière, qui ne réalise aucun calcul sur les tenseurs, mais qui modifie uniquement leur forme, avec une transformation en vecteur (tenseur de rang 1) :

Précédemment, le format des entrées était spécifié avec un objet InputLayer. Étant donné que Flatten fait ici office de première couche du réseau, il est possible d’ajouter, dans son instanciation, un paramètre input_shape pour spécifier...
Analyse des résultats
1. Visualisation du réseau
Ch04_2.1-MNIST_MLP-VisualisationModele.ipynbIl est toujours utile d’avoir une représentation visuelle d’un réseau codé dans un programme. C’est un outil précieux pour le développeur, pour vérifier que le résultat correspond bien à ce qu’il pense avoir programmé. Un support graphique est aussi indispensable, pour partager sous forme synthétique la description d’un modèle, l’analyser et proposer des corrections et/ou des améliorations.
Pour représenter un modèle codé avec Keras, nous disposons de deux solutions intégrées dans l’API, ainsi que la possibilité d’utiliser l’outil externe Netron.
a. Méthode .summary()
La classe Sequential dispose d’une méthode .summary() (les paramètres ne sont pas utiles pour le moment) :

Dans le notebook, l’instruction :
mon_reseau.summary() affiche le tableau suivant, qui décrit le perceptron :

Description du perceptron codé dans le programme
Chaque ligne correspond à une couche du réseau. Les informations sont organisées en colonnes :
-
« Layer » indique les noms des couches (’flatten’, ’dense’ et ’dense_1’) avec leur type (Flatten et Dense).
-
« Output Shape » renseigne sur la taille du tenseur en sortie de la couche (à l’exécution None est remplacé par la taille du lot).
-
« Param » contient le nombre de paramètres à calculer par l’apprentissage (poids des connexions et biais des neurones). Le décompte est facile à comprendre sur la figure ci-dessous :

Calcul du nombre de paramètres du perceptron multicouche
« Trainable params » est la somme des valeurs de la dernière colonne. C’est le nombre total de paramètres du réseau, dont les valeurs sont à déterminer par l’apprentissage.
« Non-Trainable params » renseigne sur le nombre de paramètres qui sont déjà définis et dont les valeurs ne doivent pas être modifiées par l’entraînement. Ce point sera approfondi dans les chapitres Programmation...
Optimisation des hyperparamètres
1. Différents paramètres d’un perceptron
Lors de la mise au point d’un perceptron multicouche, l’algorithme d’apprentissage calcule les valeurs des paramètres pour les poids et les biais.
D’autres éléments influent également sur les performances du modèle. Il y a bien entendu, la définition de l’architecture du réseau avec le nombre de couches, de neurones par couche et le choix des fonctions d’activation. Les conditions de l’entraînement avec le choix de l’algorithme et son paramétrage, ainsi que la taille des lots et le nombre d’époques impactent également les résultats.
Les paramètres d’architecture et d’entraînement sont appelés les hyperparamètres du modèle. Leur choix est de la responsabilité du concepteur du réseau. Comme il n’existe pas de méthodes systématiques pour les déterminer, il s’appuie sur son expérience et réalise souvent de nombreux essais avant d’obtenir un résultat jugé satisfaisant.
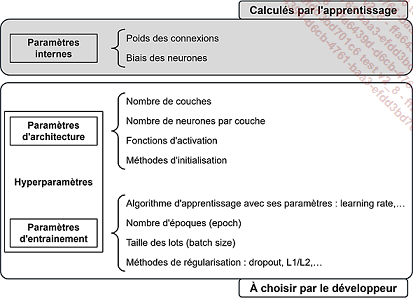
Paramètres et hyperparamètres pour un perceptron multicouche
Même si cela n’est pas mentionné ici, les jeux de donnée ont bien entendu également un rôle essentiel pour la qualité de l’entraînement.
2. Précaution avec Colab
Avec Keras, les paramètres d’architecture sont définis au moment de la construction du réseau (mon_reseau=keras.Sequential(...)), alors que ceux d’entraînement sont choisis lors de la compilation (mon_reseau.compile(...)) et du lancement de l’apprentissage (mon_reseau.fit(...)).
En conséquence pour modifier par exemple le nombre d’époques, il est tentant de ne relancer que la cellule qui lance l’apprentissage. Mais dans ce cas les poids et des biais ne sont pas réinitialisés et l’algorithme démarre avec les valeurs obtenues à la fin de l’entraînement précédent. Ce n’est pas forcément gênant, mais la forme des courbes d’apprentissage peut surprendre :

Deux lancements successifs de mon_reseau.fit() en modifiant epochs
Pour forcer une nouvelle initialisation des paramètres...
Influence du jeu de données
1. Augmentation du dataset
Ch04_4.1-MNIST_MLP-EnrichissementDataset.ipynba. Principe
Jusqu’à présent, les modifications pour améliorer les performances ont été apportées sur le modèle. Une approche complémentaire consiste à travailler sur le jeu de données afin d’améliorer sa représentativité. Pour les chiffres manuscrits, cela signifie ajouter de nouvelles images pour couvrir plus largement la diversité des styles d’écriture et les conditions de numérisation.
Avant d’imaginer collecter des pages d’écriture pour les numériser, une approche plus simple consiste à exploiter les images disponibles. L’idée est de les modifier légèrement par traitement, pour en créer artificiellement de nouvelles, qui correspondent à des variations réalistes.
Pour notre exemple, une solution consiste à décaler chaque image d’un pixel vers la gauche, la droite, le haut et le bas. Ainsi chaque donnée de la base d’apprentissage produira 4 nouveaux exemples. Bien entendu les labels associés aux images avec décalage restent les mêmes que ceux des visuels originaux.

Exemple d’images créées avec les décalages de 1 pixel
b. Décalage des images
Une manière simple de coder cette approche en Python est d’utiliser la fonction np.roll() qui déplace les éléments d’un tableau NumPy le long d’un axe. Les valeurs qui atteignent un bord sont réintroduites au début du côté opposé. Avec nos images cela signifie enlever et remettre des pixels de fond, ce qui est cohérent.
Le nouveau jeu de données (x_train_bis, y_train_bis) est créé avec le code suivant (np.tile(y_train,5) duplique 5 fois y_train).
# Images avec le décalage des pixels
G1 = np.roll(x_train,(0,-1), axis=(1,2))
D1 = np.roll(x_train,(0,+1), axis=(1,2))
B1 = np.roll(x_train,(+1,0), axis=(1,2))
H1 = np.roll(x_train,(-1,0), axis=(1,2))
# Nouveau tableau avec les images d'entraînement
x_train_bis = np.concatenate((x_train,G1,D1,H1,B1),axis=0)
# Nouveau tableau avec les labels des images d'entraînement
y_train_bis...Autres jeux de données
1. Introduction
La base MNIST est une référence incontournable en apprentissage machine, et particulièrement en vision par ordinateur. Son succès a entraîné la création d’autres datasets avec un format similaire. Ils sont utilisés à des fins pédagogiques, mais aussi pour évaluer de nouvelles approches.
Trois jeux de données, parmi les plus connus, sont détaillés dans les sections qui suivent. À chaque fois, un notebook est disponible pour montrer comment charger les images et les labels en mémoire dans des tableaux NumPy. L’objectif est de proposer le même format que celui des sections précédentes, afin de permettre au lecteur de reprendre et d’approfondir sur d’autres exemples, tous les éléments de ce chapitre.
La fonction plot_dataset() visualise pour un jeu de données, des exemples de contenu. Elle affiche les dix premières images de chaque classe à partir des données transmises : images et labels sont des tableaux NumPy avec les images et les labels du jeu de données ; lbl2txt mémorise dans un dictionnaire les intitulés associés aux labels :
def plot_dataset(images, labels, lbl2txt):
"""
---
Fonction pour afficher 10 images par classe dans un dataset
---
Args:
images (ndarray): tableau avec les images
labels (ndarray): tableau avec les labels
lbl2txt (dict) : correspondance entre labels et intitulés
Returns:
None
"""
# Parcours des labels
for no_label,nom_label in lbl2txt.items():
print(f"{no_label} --> {nom_label}")
no_image=0
# Pour chaque label affichage de 10 images
plt.figure(figsize=(8,1),dpi=100) # dpi à adapter à l'écran
for pos_img in range(10):
no_image+=1
# Recherche...Conclusion
Au début de ce chapitre, nous disposions du programme Python défini dans la section précédente. Ce code, destiné à reconnaître les chiffres manuscrits de la base MNIST, modélise un perceptron avec une seule couche de 50 neurones. Ce chapitre a été consacré à l’enrichissement de son fonctionnement, avec la poursuite de la découverte de la bibliothèque TensorFlow/Keras, et l’application de solutions pour améliorer ses performances.
Dans une première section certaines instructions de codage ont été simplifiées. Ces modifications, sans impact sur la logique d’exécution, allègent l’écriture du code et rendent sa lecture plus aisée.
Des outils d’analyse des réseaux de neurones ont ensuite été détaillés. La représentation graphique d’un modèle simplifie le partage d’informations, et permet de vérifier que le modèle décrit dans le programme correspond à celui souhaité. Le tracé des courbes d’apprentissage renseigne sur le déroulement de la phase d’entraînement, pour diagnostiquer d’éventuelles anomalies. L’affichage des résultats de classification, avec en particulier les images mal reconnues, aide à identifier...