
Jeux de données avec des fichiers d'images
Manipulation des images avec TensorFlow/Keras
1. Codage et conversion des images
Comme nous l’avons vu au chapitre Programmation d’un perceptron multicouche, le format RGB est couramment utilisé pour coder les images couleur. Cette représentation correspond au fonctionnement des écrans, qui génèrent chaque pixel à partir de sources de lumière rouge, verte et bleue :

Principe de codage d’une image au format RGB
Il existe différents formats pour stocker des images RGB sur disque. Les fichiers non compressés comme BMP contiennent les matrices complètes de pixels. Ils conservent donc une qualité maximale, mais au détriment d’une taille souvent volumineuse.
Les formats compressés utilisent des algorithmes pour réduire la quantité d’informations mémorisées. On distingue ceux sans perte d’informations, comme PNG ou GIF, de ceux, à l’instar de JPEG, qui suppriment des éléments jugés non perceptibles par l’œil humain.
En mémoire, une image est généralement stockée sous la forme d’un objet PIL (défini par la bibliothèque Pillow), ou d’un tableau ndarray (module NumPy). TensorFlow met à disposition quatre fonctions de conversion entre ces représentations :

Fonctions de conversion entre les différentes...
Jeux de données du module tensorflow_datasets
 Ch07_2-TFDS_Chifoumi-Installation.ipynb
Ch07_2-TFDS_Chifoumi-Installation.ipynb1. Présentation du module
a. Catalogue de jeux de données
Tensorflow propose dans son écosystème l’accès à des collections de données, avec le module tensorflow_datasets. Il s’agit d’une bibliothèque complémentaire à TensorFlow, avec une documentation séparée, accessible en ligne à l’adresse : https://www.tensorflow.org/datasets.

Page d’accueil de la bibliothèque tensorflow_datasets
Le menu Catalog affiche sur la gauche de l’écran une liste avec toutes les catégories de jeux de données disponibles. Celles qui nous intéressent ici sont ’Image’ et ’Image classification’ :

Familles de jeux de données du module tensorflow_datasets
b. API intégrée au module
Le module met à disposition une API pour faciliter l’exploitation de ces collections de données :

API pour utiliser le module tensorflow_datasets
Trois fonctions seront utiles :
-
tfds.load() pour charger un dataset :

-
tfds.show_examples() pour visualiser des exemples d’images :

-
tfds.as_numpy() pour convertir un jeu de données TensorFlow en tableau(x) NumPy :

2. Exemple du dataset « rock_paper_scissors »
a. Chargement du jeu de données
Un jeu de données nommé « rock_paper_scissors » est disponible dans la catégorie ’image classification’. Il est composé d’images de mains avec les trois figures classiques du Chifoumi : la pierre, la feuille et les ciseaux :

Figures « pierre - feuille - ciseaux » du jeu du Chifoumi
En interface anglaise, ce dataset est classé dans ’Image’ ; en interface française, il apparaît dans ’Image classification’.
Le notebook associé à cette section commence par l’importation du module tensorflow_datasets, qui est une bibliothèque distincte de TensorFlow :
import tensorflow_datasets as tfds L’installation du jeu de données sur la VM de Colab est réalisée avec l’instruction :
(ds_train_org, ds_valid_org), ds_info = tfds.load(
'rock_paper_scissors', ...Exploitation d’objets Dataset par un modèle
1. Objectifs du programme
Le but du programme est d’exploiter les données de ds_train_org et ds_valid_org de la section précédente, pour entraîner et valider un modèle capable de reconnaître les figures « pierre », « feuille » ou « ciseaux » sur des images de mains.
Le réseau à utiliser possède l’architecture suivante :

Modèle à convolution pour la classification des images de mains
Les différents paramètres sont initialisés au début du notebook :
# Caractéristiques du jeu de données
NB_CLASSES = ds_info.features["label"].num_classes
HT_IMG_ORG = ds_info.features["image"].shape[0]
LG_IMG_ORG = ds_info.features["image"].shape[1]
DIM_TRAIN = ds_train_org.cardinality()
# Optimisation de l'exploitation du tf.data.Dataset
AUTOTUNE = tf.data.AUTOTUNE
# Construction du modèle
HT_IMG_EXP = 100 # hauteur des images en entrée
LG_IMG_EXP = 100 # largeur des images en entrée
NB_EPOQUES = 10 # durée de l'apprentissage
TAILLE_LOT = 20 # taille des lots Comme présenté en introduction, il existe deux approches pour la préparation des données : modifier directement les Dataset (avec un pipeline) ou réaliser les prétraitements dans les premières couches du modèle.
2. Solution avec prétraitement sur le Dataset
Ch07_3.2-TFDS_Chifoumi-PreparationDonnees-v1.ipynbCette approche correspond au cheminement avec les cases blanches :

Démarche d’exploitation des images avec prétraitement sur les Dataset
a. Mise en forme des images
Les images de notre dataset ont une résolution de 300×300 pixels codés avec des entiers sur l’intervalle [0..255]. Il faut les redimensionner à la dimension des entrées du modèle et normaliser leurs valeurs avec des réels entre 0 et 1.
Les dimensions (hauteur/largeur) des images sont stockées dans les variables HT_IMG_ORG et LG_IMG_ORG (ORG pour « origine ») et celles des entrées du modèle dans HT_IMG_EXP...
Exploitation directe de fichiers d’images
1. Origine des fichiers
Les sections précédentes étaient consacrées à l’exploitation des jeux de données disponibles dans le module tensorflow_datasets. Nous nous intéressons maintenant aux collections de fichiers d’images accessibles via la plateforme Kaggle ou directement depuis une adresse URL :
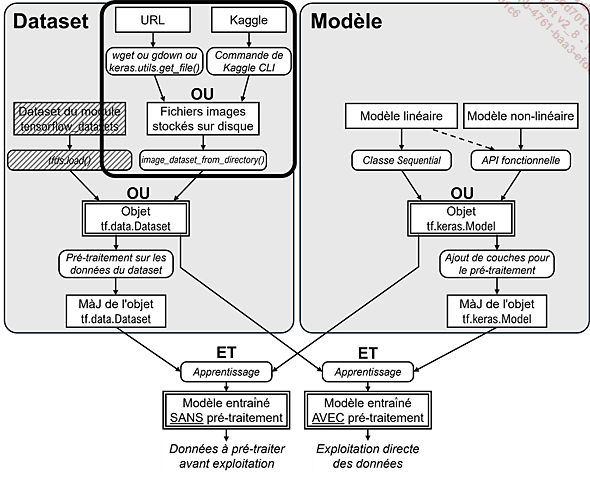
Démarches pour exploiter des fichiers d’images avec Keras
Dans les deux cas, la démarche est la même. Les fichiers doivent d’abord être transférés sur un disque directement accessible par le programme. Cette étape est essentielle pour ensuite permettre une exploitation sous la forme d’objets tf.data.Dataset, identique à celle développée précédemment.
2. Jeux de données de la plateforme Kaggle
Ch07_4.2-Kaggle_Mammals-Installation.ipynba. Présentation de la plateforme
Kaggle (kaggle.com) est une plateforme collaborative pour la science des données et l’apprentissage automatique. Créée en 2010 par Anthony Goldbloom, puis rachetée en 2017 par Google, elle est maintenant reconnue mondialement comme un lieu d’émulation et de partage d’informations. Les membres de la communauté scientifique, les ingénieurs et plus généralement tous les passionnés y partagent toutes sortes d’informations et de résultats autour du Machine Learning.
L’onglet Datasets nous intéresse plus particulièrement, avec la mise à disposition de milliers de jeux de données prêts à l’emploi. Les rubriques ’classification’ et ’computer vision’ proposent une multitude de bases d’images idéales pour expérimenter et entraîner des modèles de deep learning. Les domaines d’application sont extrêmement variés avec des exemples aussi bien dans le diagnostic médical, que dans la classification d’espèces animales ou végétales ou encore la reconnaissance faciale :

Nombreux jeux de données disponibles sur la plateforme Kaggle
Parmi les autres ressources disponibles, on trouve également de nombreuses formations interactives, une vaste collection d’exemples de code et de modèles...
Conclusion
L’objet de ce chapitre était de montrer comment exploiter avec TensorFlow/Keras des jeux de données archivés sur disque. Les solutions présentées sont indispensables pour pouvoir appliquer le deep learning sur des problèmes avec des images de grandes dimensions et des bases d’apprentissage composées de plusieurs dizaines, voire centaines de milliers d’exemples.
Les mécanismes de pipeline, disponibles dans TensorFlow, sont spécialement adaptés pour faire le lien entre un modèle développé sous Keras et une base d’entraînement avec des fichiers d’images. Ils simplifient considérablement l’écriture du code, tout en optimisant l’exploitation des ressources (mémoire, disque, processeur et GPU).
Après des rappels sur le codage et la manipulation des images, le module tensorflow_datasets a été présenté avec son catalogue de jeux de données. Pour les utiliser, il faut commencer par associer les images à des objets tf.data.Dataset. Ceux-ci servent ensuite à la création des pipelines qui alimentent les modèles pour l’apprentissage et les tests. Une collection de figures de mains au jeu du Chifoumi (pierre, feuille, ciseaux), a été choisie comme exemple pour illustrer le codage d’une solution.
La section suivante a été...