
Introduction au transfer learning
Solution « no-code » avec la Teachable Machine
1. Outils « no-code » pour la classification d’images
Sur Internet, de nombreux outils « no-code » sont proposés pour réaliser des applications de machine learning. La promesse est de démocratiser l’accès à l’intelligence artificielle en permettant à des utilisateurs non-experts en programmation, de construire, entraîner et déployer des modèles sans écrire une seule ligne de code.
La Teachable Machine développée à partir de 2017 par le Google Creative Lab est un excellent exemple de cette philosophie. Il s’agit d’une application web gratuite, accessible via un navigateur, qui permet d’entraîner facilement un modèle d’apprentissage automatique. La version actuelle est capable d’apprendre à reconnaître des images, des sons ainsi que des postures de corps humains :
 Accès à la
Teachable Machine : https://teachablemachine.withgoogle.com
Accès à la
Teachable Machine : https://teachablemachine.withgoogle.com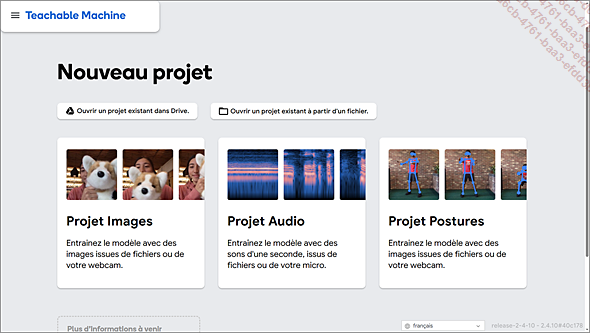
Projets possibles avec la Teachable Machine
Microsoft proposait un logiciel directement concurrent baptisé Lobe, à installer sur sa machine en local. Mais, la firme de Redmond ayant décidé de prioriser ses efforts sur les solutions intégrées à Azure Machine Learning, la maintenance n’est plus assurée.
 Vidéo
de présentation de Lobe : https://lobe-ia.vercel.app/tour
Vidéo
de présentation de Lobe : https://lobe-ia.vercel.app/tour2. Exemple d’utilisation de la Teachable Machine
a. Création d’un projet de classification d’images
Dans un premier mode d’utilisation de la Teachable Machine, les exemples d’apprentissage sont construits avec les capacités d’acquisition de l’ordinateur : webcam pour les images et micro pour le son. Cet usage présente surtout un intérêt ludique et démonstratif, pour réaliser rapidement des expérimentations illustrant le potentiel du machine learning. Sur Internet, de nombreuses vidéos expliquent ce fonctionnement, par exemple :
Une seconde approche consiste à utiliser des fichiers comme données d’apprentissage....
Modèles cachés dans la Teachable Machine
1. Apprentissage par transfert
a. Principes du transfer learning
Le transfer learning (ou apprentissage par transfert) consiste à adapter des réseaux pré-entraînés, dont les performances sont déjà reconnues, à une utilisation spécifique. Pour chaque type d’application - comme la classification, la segmentation, la détection d’objets ou l’analyse de postures - la communauté scientifique a mis au point des modèles de deep learning particulièrement performants. Ces derniers ont été entraînés sur de vastes collections de données, couvrant des configurations très variées.
Dans le domaine de la classification d’images, la base de données ImageNet est fréquemment utilisée. Elle contient 1,2 million de visuels répartis en 1 000 catégories (cf. chapitre Solution des réseaux à convolution). Pour réutiliser un modèle entraîné sur ces données, le principe du transfer learning consiste à conserver la partie d’extraction des caractéristiques et à ne modifier que les couches de classification, pour les adapter au nouveau problème à traiter :

Principe du transfer learning en classification
On part du principe que si une topologie de réseau a démontré une capacité à extraire des motifs discriminants sur une base d’images, elle restera performante sur d’autres visuels. Bien entendu, cette approche fonctionnera d’autant mieux que les images utilisées lors de l’entraînement initial, présentent des similitudes avec celles de la nouvelle étude.
Une fois le nouveau modèle défini, un apprentissage est nécessaire pour l’adapter à sa nouvelle tâche. Pour cela, il faut disposer d’un jeu de données d’entraînement composé d’exemples représentatifs du nouveau comportement attendu. Pour éviter des temps d’apprentissage trop longs, seuls les poids des couches de classification sont recalculés. Pour le bloc d’extraction des caractéristiques, les valeurs des paramètres du réseau de base, déjà entrainé...
Programmation du transfer learning avec Keras
1. Architecture du code
Le module applications de la bibliothèque Keras met à disposition de nombreux modèles entraînés avec la base ImageNet. Dans le chapitre Programmation d’un réseau à convolution, nous avons montré comment les utiliser pour classer des images qui appartiennent à l’une des 1 000 catégories de ce jeu de données.
L’intérêt principal de ces réseaux est la possibilité de les employer pour l’apprentissage par transfert. La manière de procéder est extrêmement simple, avec la structure suivante de code :

Structure du code pour l’apprentissage par transfert
Pour chaque modèle il existe une fonction applications.NomModele() pour le charger en mémoire. En fixant le paramètre include_top à False, seule la partie d’extraction des caractéristiques est sélectionnée. Pour conserver les valeurs des filtres de convolution, l’attribut trainable est forcé à False pour les couches de ce bloc, ce qui interdit toute modification lors d’un apprentissage.
Le nouveau modèle est construit, avec l’ajout des traitements pour la classification. Ils se composent au minimum d’une couche de sortie avec des activations ’softmax’, possiblement complétée avec d’autres couches Dense() entièrement connectées. Si nécessaire des opérations d’augmentation de données peuvent être ajoutées au début du réseau.
La variable mon_reseau est un objet de type keras.Model, qui fonctionne comme les modèles construits jusqu’à présent : apprentissage avec les méthodes .compile() et .fit(), possibilité d’utiliser des pipelines de données…
2. Classification des images de mammifères
 Ch08_3.2-Kaggle_Mammals-TransferLearning.ipynb
Ch08_3.2-Kaggle_Mammals-TransferLearning.ipynba. Construction du modèle
Nous proposons d’appliquer la construction d’un réseau par transfer learning avec la collection d’images des 45 espèces de mammifères, déjà utilisée à plusieurs reprises. MobileNet V2 sera employé comme modèle de base afin de comparer les résultats...
Conclusion
Le thème de ce chapitre est le transfer learning, qui offre la possibilité d’adapter, à un problème spécifique, un modèle déjà entraîné et éprouvé dans d’autres contextes. Bien que cette approche puisse paraître surprenante au premier abord, elle est très souvent plus rapide et plus efficace que la construction « à la main » d’un nouveau modèle complet.
Après avoir présenté le concept d’outil « no-code », nous avons détaillé le fonctionnement de la Teachable Machine. Cette application web permet d’entraîner un modèle d’apprentissage automatique, avec des images ou des sons, sans avoir à écrire la moindre ligne de code. En utilisant notre collection d’images de mammifères, il a été possible de créer en quelques minutes un modèle capable d’identifier un animal avec une fiabilité supérieure à 85 % ! Une fois élaboré, le modèle peut être exporté pour être exploité dans un programme Python, de manière totalement indépendante de l’application qui a permis de le créer.
Même si les résultats obtenus peuvent sembler spectaculaires, ils n’ont rien...