
Programmation d'un réseau à convolution
Construction d’un modèle avec Keras
1. Continuité avec le perceptron multicouche
Nous avons vu, dans le chapitre précédent, qu’un réseau à convolution se composait d’une partie pour extraire les caractéristiques des images, suivie d’une étape de classification :
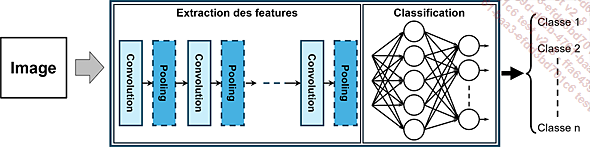
Principe d’un réseau à convolution
La programmation avec Keras va reprendre la même structure de code que celle utilisée pour les perceptrons multicouches, en ajoutant la description des couches de convolution/pooling. Les classes disponibles dans le module keras.layers pour les représenter sont détaillées dans les sections suivantes.
Tant que les modèles restent séquentiels, nous continuons à employer la classe keras.Sequential. Nous verrons un peu plus loin comment procéder avec l’API fonctionnelle pour décrire des branches parallèles.
2. Couche de convolution
La classe keras.layers.Conv2D opère des convolutions spatiales sur les feature maps en entrée :

Les deux syntaxes layers.Conv2D et layers.Convolution2D existent et font référence à la même classe, mais l’usage de Conv2D est à privilégier.
3. Couches de pooling
a. Pooling par moyenne
La classe keras.layers.AvgPool2D opère un pooling par calcul d’une moyenne par zone sur les feature maps en entrée :

Les deux syntaxes layers.AvgPool2D et layers.AveragePooling2D existent et font référence à la même classe, mais l’usage de AvgPool2D est à privilégier.
La classe keras.layers.GlobalAvgPool2D opère un pooling...
Programmation du réseau LeNet-5
1. Rappel de l’architecture du modèle
Le modèle LeNet-5 à programmer est le suivant :

Description détaillée du réseau LeNet-5
L’apprentissage utilise la même base MNIST de chiffres manuscrits que celle utilisée dans le chapitre Programmation d’un perceptron multicouche. C’est pourquoi la dimension des images en entrée du modèle est de 28×28 pixels.
Ce modèle comporte une petite différence par rapport à celui décrit dans le chapitre précédent, dans lequel la taille des images est de 32×32 pixels. C’est pourquoi la première couche de convolution utilise l’option de padding afin de n’avoir aucune réduction spatiale. Ainsi, on retrouve des feature maps de dimension 28×28 comme précédemment.
2. Programme avec des explications détaillées
 Ch06_2.2-MNIST_LeNet5-Apprentissage-v1.ipynb
Ch06_2.2-MNIST_LeNet5-Apprentissage-v1.ipynbLa structure du programme est identique à celle du chapitre précédent. Les seules modifications concernent le bloc de description du modèle, dans lequel le réseau LeNet-5 est construit :
# Instanciation d'un modèle "Sequential"
mon_reseau = keras.Sequential()
# Couche d'entrée avec la taille des images
mon_reseau.add(keras.layers.InputLayer(shape=(28,28,1)))
# 1ère couche de convolution
mon_reseau.add(keras.layers.Conv2D(
filters=6, # 6 filtres de convolution
kernel_size=(5,5), # noyau de convolution 5x5
strides=(1,1), # décalage horizontal=1 / vertical=1
activation='relu', # fonction d'activation=Relu
padding='same')) # ajout d'un bord à l'image
# 1ère couche de pooling (average)
mon_reseau.add(keras.layers.AvgPool2D(
pool_size=(2,2), #...Expérimentation de modèles avec ImageNet
Ch06_3-ImageNet-ReconnaissanceImages.ipynb1. Objectifs
Jusqu’à présent, nous avons uniquement expérimenté la base MNIST avec des images stockées dans des tableaux en mémoire. L’objectif est maintenant d’exploiter des jeux de données (datasets), archivés sur disque, avec des images de plus grande taille et en quantité plus importantes.
Pour débuter, cette section est consacrée à la classification de photos de la base ImageNet avec des modèles Keras déjà entraînés, tels que VGGNet ou Inception. Pour une description détaillée de ces réseaux et de la base, vous pouvez consulter le chapitre précédent.
2. Dataset ImageNet 1000
a. Téléchargement de la base d’images
Étant donné qu’aucun apprentissage ne sera réalisé dans cette section, il n’est pas nécessaire de disposer de la totalité de la base ImageNet (qui représente plus de 50 Go !). Une base réduite, nommée « ImageNet 1000 (mini) », à installer en local sur l’ordinateur, sera suffisante. Elle comporte des images d’apprentissage et de validation pour les 1 000 catégories, mais en nombres limités.
 « ImageNet 1000 » est
disponible pour téléchargement sur le site kaggle.com à l’adresse https://www.kaggle.com/datasets/ifigotin/imagenetmini-1000 :
« ImageNet 1000 » est
disponible pour téléchargement sur le site kaggle.com à l’adresse https://www.kaggle.com/datasets/ifigotin/imagenetmini-1000 :
Page « ImageNet 1000 (mini) » disponible sur le site kaggle.com
Pour enregistrer les images de ce dataset, il suffit de télécharger sur l’ordinateur le fichier zip (3,92 Go) et de le décompresser à l’emplacement souhaité (chaque opération pourra prendre plusieurs dizaines de minutes).
L’accès au téléchargement nécessite de disposer d’un compte Kaggle (gratuit). Si vous n’en possédez pas, il faut en créer un, avec la possibilité de l’associer au compte Google utilisé pour Colab.
Voici le résultat d’une installation dans le répertoire C:\Datasets\imagenet-mini :

Base « imageNet-mini » installée en local...
Identification d’objets avec la webcam
Ch06_4-ImageNet-ReconnaissanceWebcam.ipynb1. Utilisation de la webcam avec Colab
Pour terminer ce chapitre, nous proposons d’exploiter la fonction classer_image(), développée dans la section précédente, pour identifier des images acquises avec la webcam de l’ordinateur.
Bien entendu, cette application aura des limites, puisque par construction, elle ne répondra qu’avec des propositions parmi les 1 000 catégories d’ImageNet. Malgré cette contrainte, ce programme permet de se rendre compte de la puissance des réseaux à convolution pour la reconnaissance d’images, et parfois aussi de ses limites.
Pour trouver comment exploiter la webcam avec Colab, le plus simple est d’utiliser la fonction Extraits de code de la barre latérale. Cliquer sur l’icône <> (1) ouvre le volet Extraits de code, avec une zone de saisie pour filtrer les demandes. En renseignant « webcam », la proposition Camera Capture apparaît dans la partie grisée (3). Après un appui sur la commande Insérer (4) le code de la fonction take_photo() est transféré dans le notebook :

Commande Extraits de code pour utiliser la webcam
Cette fonction est développée en JavaScript ; les détails de son fonctionnement sortent du cadre de cet ouvrage.
Notre notebook intègre une fonction prendre_photo(), fortement inspirée de ce code. Elle gère une fenêtre pour afficher la webcam et retourne le contenu lorsque l’utilisateur appuie sur le bouton Capture. L’image est codée au format Data URL comme...
Conclusion
Dans ce chapitre nous avons développé la construction et l’exploitation de modèles à convolution avec la bibliothèque TensorFlow/Keras.
Il débute par l’examen détaillé des couches disponibles dans le module keras.layers pour coder les opérations d’extraction de caractéristiques. Les classes Conv2D, AvgPool2D, GlobalAvgPool2D, MaxPool2D, GlobalMaxPool2D, et Flatten ont successivement été décrites, avec leur fonction et leur syntaxe. La normalisation par lots (BatchNormalization) a également été abordée avec des précisions sur ses modes de calculs.
Ces connaissances ont ensuite été utilisées pour le codage du réseau LeNet-5. Le programme développé obtient de très bons résultats, avec un taux de bonnes classifications supérieur à 99 %, sur les images de validation de la base MNIST. Ces performances ont encore été améliorées avec l’utilisation du module Keras-Tuner. Grâce à l’ajout de nouvelles couches de convolution et de pooling, et à l’augmentation de la profondeur des filtres, le taux d’erreurs a été réduit à 0,5 %. L’intégration de ce réseau avec l’interface interactive, développée dans le chapitre...