
Modélisation physique et conceptuelle OLAP
Principes fondamentaux de la conception OLAP
Le chapitre précédent a évoqué les bases des différents modèles. À présent, il convient d’étudier la manière dont est conçu, concrètement, un système OLAP.
L’objectif ne change pas : il s’agit toujours de préparer le travail d’analyse sur d’énormes historiques de données pour faciliter la prise de décision. Pour que le cube multidimensionnel remplisse son rôle efficacement, sa conception doit impérativement respecter quatre règles d’or :
-
Facilité d’utilisation : la conception doit être simple et facile à comprendre pour les utilisateurs finaux, qui sont souvent des analystes métier et non des experts techniques. L’interface doit permettre d’interagir avec les données de manière naturelle, par des actions simples comme le glisser-déposer.
-
Cohérence des données : les informations doivent être fiables et précises. La conception OLAP s’appuie généralement sur un entrepôt de données ou un datamart, qui agrègent des données provenant de différentes sources pour assurer leur uniformité et leur exactitude.
-
Performance : les systèmes OLAP sont optimisés pour des requêtes...
Modèle en étoile (Star Schema)
1. Structure et organisation des tables
Dans un modèle en étoile, la structure des tables est conçue pour optimiser l’analyse des données. Ce modèle est le plus simple et le plus couramment utilisé en conception de base de données décisionnelles, notamment pour les systèmes OLAP.
Il se compose de deux types de tables :
-
La table de faits (Fact Table) : c’est la pièce maîtresse du modèle. Elle contient les mesures (chiffres, montants, quantités) que l’on souhaite analyser, comme le nombre de ventes, le chiffre d’affaires, ou le bénéfice. Chaque ligne correspond en général à un événement ou une transaction précise. Comme elle enregistre un grand volume de données, c’est souvent la table la plus imposante du schéma. On y retrouve également les clés étrangères, servant de lien vers les différentes tables de dimensions.
-
La table de dimensions : elle apporte le contexte nécessaire à l’interprétation des faits. Elle comporte les informations qui permettent de qualifier et de détailler les mesures : qui a acheté ?, quoi ?, où ?, quand et de quelle manière ?. Chaque dimension ouvre un angle d’analyse différent, par exemple : le temps, le produit, le lieu ou encore le client. Par rapport à la table de faits, les tables de dimensions sont généralement...
Modèle en flocon (Snowflake Schema)
1. Impacts sur la normalisation des données
Le modèle en flocon de neige est très proche du modèle en étoile, car il reprend la même logique. Une table de faits centrale reliée à des dimensions mais avec une différence de taille : les tables de dimensions sont normalisées.
En effet, au lieu de regrouper toutes les informations d’une dimension dans une seule table, on les décompose en plusieurs niveaux hiérarchiques. Par exemple, une dimension Produit ne contiendra pas directement la catégorie et la sous-catégorie : ces informations seront stockées dans des tables séparées, liées entre elles par des clés étrangères.
Le modèle en flocon pousse plus loin la normalisation en réduisant les redondances car les informations partagées ne sont enregistrées qu’une seule fois. La maintenance est alors plus simple, si une catégorie change de nom il suffit de le mettre à jour dans une seule table.
En revanche, cette normalisation augmente le nombre de tables et donc la complexité du schéma.
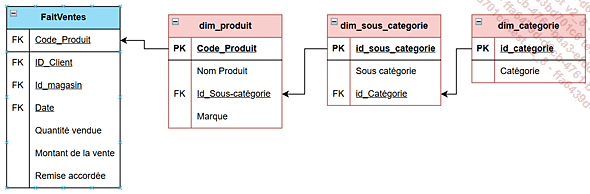
Exemple de modèle en flocons
2. Optimisation des jointures et performances
En augmentant le nombre de tables, le modèle en flocon augmente le nombre de jointures contrairement au modèle en étoile. Par exemple :...
Modèle en constellation de faits
1. Gestion des relations complexes
Contrairement au modèle en étoile qui privilégie la simplicité et la rapidité d’analyse, le modèle en flocon pousse la normalisation pour réduire la redondance des données au prix d’un nombre plus élevé de jointures. Le modèle en constellation de faits (Galaxy schema) répond à une évolution des besoins analytiques devenant encore plus complexes et avec plusieurs processus métier à analyser et des dimensions partagées entre ces processus.
Le modèle en constellation se caractérise par la présence de plusieurs tables de faits reliées à un ensemble de tables de dimensions communes.
Plutôt qu’une seule étoile ou un seul flocon, on obtient une constellation, où plusieurs tables de faits gravitent autour des mêmes dimensions.
Ce modèle trouve toute son utilité lorsqu’il faut gérer plusieurs processus métiers liés.
Par exemple :
Si l’on reprend l’exemple précédent d’une entreprise de distribution. Cette dernière aimerait analyser, en plus des ventes (FaitVentes), les stocks (FaitStocks) ainsi que les achats fournisseurs (FaitAchats).
Ces trois faits partagent souvent les mêmes dimensions communes : Produit, Temps, Magasin...
Comparaison des performances entre étoile, flocon et constellation
La comparaison des performances entre les trois modèles peut être résumée en quelques repères opérationnels :
|
Critères |
Modèle en étoile |
Modèle en flocon |
Modèle en constellation |
|
Complexité des requêtes |
Faible |
Moyenne à élevée (plus de JOIN) |
Variable (souvent élevé) |
|
Coût de maintenance |
Redondance acceptée |
Centralisée, plus propre |
Idem + gestion conformité |
|
Adhoc/Self-Service |
Très favorable |
Correct si vues aplaties |
Délicat sans couche sémantique |
|
Performance brute (agrégations) |
Excellente en colonne |
Bonne si les vues sont matérialisées/agrégats |
Bonne si agrégats et filtres simples |
|
Évolutivité et Multi-processus |
Limitée |
Limitée |
Naturelle (plusieurs faits) |
L’arrivée des bases de données colonnaires a bousculé certaines certitudes ancrées dans la modélisation multidimensionnelle. En changeant la manière dont la donnée est physiquement stockée, ces systèmes ont remis en question la suprématie absolue du modèle en étoile pour les performances.
Une base de données colonnaire se définit avant tout par son modèle de stockage : contrairement aux bases de données...
Hybridation des modèles et cas d’usage spécifiques
Le choix d’un schéma de données ne doit pas reposer uniquement sur la théorie. Une campagne de tests ciblée sur un échantillon représentatif (idéalement plusieurs dizaines de millions de lignes pour outrepasser les effets de cache) constitue la méthode la plus fiable pour valider une architecture.
Un protocole de test efficace se concentre sur trois à cinq types de requêtes standards :
-
Top-N (classements).
-
Agrégats temporels (sommes mensuelles, annuelles).
-
Slice-and-dice (filtrage multidimensionnel).
-
Jointures inter-faits (croisement de deux processus).
-
Distinct count (dénombrement d’éléments uniques).
Les mesures doivent porter sur la latence (médiane p50 et p95 pour les cas extrêmes), le différentiel de performance entre un cache vide et plein (effet cold/warm), ainsi que la tenue du système sous concurrence.
Les résultats de ces mesures empiriques permettent généralement de trancher objectivement vers le modèle le plus adapté aux contraintes réelles du projet :
-
Le schéma en étoile s’avère souvent le plus performant pour les usages interactifs, car il minimise mécaniquement les jointures sur le chemin critique des requêtes.
-
Le schéma en flocon devient pertinent lorsque...