
L'apprentissage machine
Introduction
L’apprentissage machine (Machine Learning), aujourd’hui au cœur de nombreuses innovations technologiques, a parcouru un long chemin depuis ses débuts avec le perceptron dans les années 50. Ce modèle simple et limité, inspiré du fonctionnement des neurones, a ouvert la voie à un tout nouveau domaine scientifique, à la croisée des mathématiques, des statistiques et de l’algorithmique. Au fil des décennies, ce domaine a vu de nombreuses avancées comme les réseaux neuronaux profonds qui ont permis aux machines de reconnaître des images, de comprendre le langage et de dépasser les humains dans certaines tâches complexes. Aujourd’hui les larges modèles de langage marquent une nouvelle étape. Nous sommes en effet entrés dans l’ère des modèles génératifs comme ChatGPT, qui représentent une nouvelle étape : les machines sont désormais capables de créer du contenu pertinent à partir d’instructions simples et de s’exprimer (presque) comme un humain.
Ce chapitre retrace cette évolution, depuis les premières tentatives jusqu’à l’impact majeur de l’intelligence artificielle moderne. Le domaine de l’apprentissage machine regorge d’approches, d’innovations, d’algorithmes...
Concepts de base
Outre les outils mathématiques mentionnés ci-dessus et disponibles dans l’annexe Arsenal mathématique, d’autres concepts de base méritent d’être expliqués au préalable de la découverte des formidables techniques d’apprentissage machine. Commençons donc par découvrir ces prérequis.
1. Des systèmes experts à l’apprentissage machine
Nous avons évoqué les systèmes experts dans le chapitre Des usages militaires à l’ère digitale du livre L’informatique - Des transistors aux microservices à la section L’informatisation massive des entreprises. Ces derniers ont inspiré la recherche sur la représentation des connaissances et la logique, des domaines qui ont influencé certains aspects théoriques de l’apprentissage machine. Leurs limites dans les environnements complexes, en raison de la nécessité de construire manuellement une base de connaissances étendue, ont conduit à la transition vers des méthodes basées sur l’apprentissage machine, où les machines peuvent apprendre automatiquement à partir de données. Bien qu’elles ne constituent pas la principale motivation des recherches en apprentissage machine, ces limites ont suscité un vif intérêt de l’industrie pour les techniques permettant de s’abstraire de la configuration manuelle des règles métier.
Les principaux cas d’usage actuels de l’apprentissage machine sont présentés sur la figure 5-1.

Figure 5-1 - Les cas d’usage de l’apprentissage machine
2. Apprentissage automatique ou apprentissage machine ?
Le terme « Machine Learning » a été introduit dans les années 50 pour qualifier la capacité d’un système informatique à apprendre des données sans être explicitement programmé pour chaque tâche. Lorsqu’il a fallu traduire ce concept en français, deux expressions ont émergé : « apprentissage automatique » et « apprentissage machine ».
« Apprentissage automatique » a été largement adopté dans la littérature...
Le perceptron
Le Perceptron est l’un des premiers algorithmes d’apprentissage machine, conçu pour modéliser un neurone artificiel. Il a établi les bases des réseaux neuronaux modernes.
1. Histoire du perceptron
En 1943, Warren McCulloch et Walter Pitts ont publié un article dans lequel ils proposent un modèle mathématique simplifié d’un neurone. Leur modèle, appelé le neurone de McCulloch-Pitts, est une représentation formelle d’un neurone biologique, avec des entrées et une fonction d’activation qui donne une sortie binaire. Leur travail a jeté les bases théoriques de ce que l’on appelle aujourd’hui les réseaux de neurones.
En 1957, Frank Rosenblatt a introduit le Perceptron dans le cadre de recherches financées par la Navy des États-Unis. Il est le premier algorithme d’apprentissage supervisé basé sur l’idée des neurones artificiels. Le Perceptron est capable de modifier ses poids pour s’adapter aux données d’entraînement, ce qui en fait un véritable algorithme d’apprentissage machine. Ce modèle est aussi le premier à pouvoir être ajusté (ou entraîné) pour résoudre des problèmes de classification linéaire. L’objectif initial de Rosenblatt était de créer une machine capable de simuler le fonctionnement des neurones biologiques pour apprendre à partir de données, inspiré par les travaux de neurophysiologistes présentant la façon dont les neurones du cerveau fonctionnent.
Le perceptron est considéré comme la première tentative réussie de création d’un modèle d’apprentissage supervisé. En 1960, Rosenblatt a présenté...
Les modèles régressifs
Les modèles régressifs sont une famille d’algorithmes utilisés pour modéliser les relations entre des variables dépendantes (ou cibles) et des variables indépendantes (ou prédicteurs).
Ces modèles permettent de prédire une variable continue (en général) en fonction de plusieurs autres variables. La régression est un concept fondamental dans les statistiques et a été largement adoptée dans le domaine de l’apprentissage machine.
1. Histoire des modèles régressifs
Le concept de régression remonte à la fin du XIXe siècle, introduit par le statisticien britannique Sir Francis Galton. Il a utilisé le terme « régression » pour décrire la tendance des enfants à avoir des tailles plus proches de la moyenne, par rapport à la taille de leurs parents, ce qu’il a appelé la « régression vers la moyenne ». La technique des moindres carrés, aujourd’hui encore couramment utilisée dans les méthodes de régression linéaire, a été développée au début du XIXe siècle par Legendre et Gauss, et demeure aujourd’hui l’un des outils les plus utilisés en statistiques.
Au fil des années, plusieurs variantes de modèles régressifs ont été développées, comme la régression multiple, la régression logistique, et plus récemment des techniques plus complexes comme les régressions Lasso et Ridge ou même des forêts aléatoires (random forests) utilisées pour les tâches de régression.
Les réseaux de neurones sont également fréquemment utilisés pour des tâches de régression lorsque les données sont larges ou complexes. Lorsqu’elles sont très complexes ou non structurées (comme les images ou les séries temporelles), on utilise des architectures adaptées, comme les réseaux de neurones profonds (DNN - Deep Neural Network) ou les réseaux récurrents (RNN - Recurrent Neural Network), mais cela entraîne des besoins en calcul plus élevés.
Aussi, dans la pratique, on préfère...
Le clustering
Le clustering (ou « regroupement » en français, mais ce n’est pas utilisé), est une méthode d’analyse de données qui vise à regrouper des objets similaires en termes de propriétés au sein de structures, ou ensembles homogènes appelés clusters, de sorte que les points d’un même groupe soient plus similaires entre eux qu’avec ceux des autres groupes, permettant ainsi de révéler des structures cachées dans les données. L’idée du clustering remonte à plusieurs décennies, avec des racines dans des disciplines comme les statistiques et la géométrie computationnelle.
1. Histoire du clustering
Dans les années 1930, des concepts de « regroupements similaires » étaient utilisés dans des domaines comme la taxonomie (classification des espèces) et la psychologie pour organiser des données. Cependant, le clustering sous sa forme moderne a émergé avec l’évolution de l’informatique et de l’intelligence artificielle dans les années 1950 et 1960. L’un des premiers algorithmes de clustering, k-means, a été proposé par Stuart Lloyd en 1957. Depuis lors, diverses approches de clustering ont été développées pour répondre à des problèmes de classification non supervisée dans des ensembles de données toujours plus vastes et complexes.
2. Fonctionnement du clustering
Le clustering est une méthode d’apprentissage non supervisée, ce qui signifie qu’il n’y a pas de labels ou de catégories préalables pour les données. L’objectif est de regrouper des données en clusters, c’est-à-dire des groupes d’objets similaires les uns aux autres selon un certain critère, tout en étant différents des objets des autres clusters.
Le processus de clustering repose sur la mesure de la similarité ou de la proximité entre les points de données, souvent basée sur des métriques de distance comme la distance euclidienne, la distance de Manhattan ou d’autres mesures de proximité.
Voyons les étapes générales du clustering :
-
Représentation...
Les réseaux de neurones multicouches (MLP)
Les réseaux de neurones multicouches (MLP - Multi-Layer Perceptron) forment certainement le pilier le plus fondamental de l’apprentissage machine moderne et du deep learning. Inspirés du fonctionnement du cerveau humain, ces réseaux sont capables de modéliser des relations complexes entre des variables et de résoudre de nombreux problèmes où les méthodes classiques échouent. Leur développement est étroitement lié à l’histoire de l’intelligence artificielle et à l’évolution des algorithmes d’apprentissage machine.
1. Histoire des réseaux de neurones
Comme évoqué précédemment lorsque nous avons parlé du perceptron, l’idée des réseaux de neurones est née dans les années 40, lorsque les chercheurs Warren McCulloch et Walter Pitts ont proposé le premier modèle mathématique d’un neurone artificiel. Mais c’est avec la création du perceptron en 1957 par Frank Rosenblatt que les réseaux de neurones artificiels ont vraiment pris forme. Le perceptron était un modèle de neurone simple capable de résoudre des tâches de classification linéaire.
Mais, en 1969, Marvin Minsky et Seymour Papert ont montré que le perceptron ne pouvait pas résoudre certains problèmes non linéaires comme le problème XOR, ce qui a entraîné un déclin de l’intérêt pour les réseaux neuronaux (appelé le premier hiver de l’IA).
Les années 1980 ont marqué une renaissance des réseaux de neurones avec l’introduction de l’algorithme de backpropagation - rétropropagation du gradient - permettant d’entraîner des réseaux de neurones multicouches.
Depuis les années 2010, avec la disponibilité de grandes quantités de données (big data) et des améliorations des processeurs graphiques (GPU), les réseaux neuronaux profonds (Deep Neural Networks) ont connu un essor fulgurant, révolutionnant des domaines comme la vision par ordinateur, le traitement du langage naturel, et la reconnaissance vocale. Nous y reviendrons.
2. Principe des réseaux de neurones...
La rétropropagation (BP)
La rétropropagation du gradient (backpropagation - BP) est le nom donné à l’algorithme utilisé dans les réseaux neuronaux artificiels pour entraîner le modèle en ajustant les poids des connexions neuronales afin de minimiser l’erreur de prédiction (la fonction de perte). La rétropropagation du gradient consiste à calculer le gradient de la fonction de perte par rapport aux poids du réseau tout en propageant l’erreur en arrière, couche par couche. Ces gradients sont ensuite utilisés par une méthode d’optimisation (comme la descente de gradient) pour mettre à jour les poids itérativement et ainsi minimiser l’erreur de prédiction du modèle.
1. Histoire de la rétropropagation
La rétropropagation a été popularisée dans les années 80 par des chercheurs comme David Rumelhart, Geoffrey Hinton, et Ronald J. Williams, bien que ses bases mathématiques aient été établies plus tôt. Elle est devenue l’outil central pour l’entraînement des réseaux neuronaux multicouches (perceptrons multicouches ou MLP), un type de réseau dont la popularité a explosé avec les progrès de l’apprentissage profond (deep learning) dans les années 2010.
Avant la découverte de la rétropropagation, l’apprentissage dans les réseaux neuronaux était limité à des architectures simples comme le perceptron monocouche. La rétropropagation a permis d’entraîner efficacement des réseaux multicouches en ajustant les poids à travers toutes les couches du réseau, ce qui a ouvert la voie à des modèles plus complexes capables de résoudre des problèmes non linéaires.
2. Principe de la rétropropagation
Le principe de la rétropropagation repose sur l’usage d’une méthode d’optimisation (la descente de gradient ou similaire) pour ajuster les poids dans un réseau de neurones en fonction de l’erreur commise lors des prédictions. L’objectif est donc de minimiser une fonction de perte, qui mesure l’écart entre les prédictions du réseau et les valeurs...
Les arbres de décision
Les arbres de décision sont des algorithmes d’apprentissage supervisé utilisés pour des tâches de classification et de régression. Ils sont appréciés pour leur simplicité d’interprétation, leur capacité à gérer des données complexes, et leur flexibilité.
1. Histoire des arbres de décision
L’idée des arbres de décision remonte aux années 70, lorsque des chercheurs ont cherché des moyens d’automatiser la prise de décision et la classification dans les systèmes d’intelligence artificielle. Cependant, les premiers travaux significatifs ont été réalisés par Ross Quinlan en 1986 avec l’algorithme ID3 (Iterative Dichotomiser 3), qui a ensuite évolué pour donner des variantes améliorées comme C4.5 et CART (Classification and Regression Trees).
Ces algorithmes ont marqué un tournant en offrant un moyen simple et efficace de prendre des décisions en s’appuyant sur des règles simples de type si ... alors, modélisant ainsi le processus de décision humaine de manière hiérarchique.
2. Principe des arbres de décision
Un arbre de décision se compose de nœuds et de branches :
-
Nœud racine : il représente le point de départ du modèle, où la première question est posée.
-
Nœuds internes : ils représentent les décisions intermédiaires qui divisent les données en sous-ensembles.
-
Feuilles : ce sont les nœuds terminaux, où une décision ou une classification est effectuée.
L’arbre de décision est construit de manière récursive. À chaque niveau de l’arbre, une caractéristique (feature) est sélectionnée pour diviser les données en deux sous-groupes ou plus, selon une règle de décision basée sur une valeur seuil. Ce processus est répété pour chaque sous-ensemble de données, jusqu’à ce que certains critères soient atteints (comme une pureté maximale des nœuds, ou un nombre minimal de résultats dans une feuille).
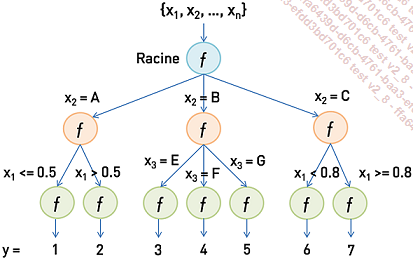
Figure 5-10 - Les arbres de décision
3. Fonctionnement...
Les réseaux neuronaux convolutifs (CNN)
Les réseaux neuronaux convolutifs (CNN - Convolutional Neural Networks) sont une architecture spécifique de réseaux de neurones artificiels, principalement utilisée pour les tâches de vision par ordinateur comme la reconnaissance d’images et la classification d’objets. Leur architecture est adaptée à l’analyse de données ayant une structure spatiale, comme les images.
1. Histoire des réseaux neuronaux convolutifs
Les CNN ont été introduits dans les années 80 par Yann Le Cun, un pionnier en intelligence artificielle. Le réseau LeNet-5 développé par Le Cun en 1998 pour la reconnaissance des chiffres manuscrits sur les chèques bancaires a marqué l’une des premières utilisations pratiques des CNN.
Cependant, les CNN sont devenus largement populaires à partir de 2012, avec l’architecture AlexNet qui a remporté la compétition de reconnaissance d’images ImageNet avec une performance impressionnante, surpassant de loin les méthodes classiques.
Depuis lors, les CNN sont devenus l’architecture dominante pour la vision par ordinateur et ont été utilisés dans de nombreuses applications, des systèmes de reconnaissance d’images aux voitures autonomes.
2. Principe des réseaux neuronaux convolutifs
Un CNN fonctionne en extrayant automatiquement les caractéristiques locales d’une image grâce à des filtres convolutifs. Contrairement aux réseaux neuronaux traditionnels qui traitent les entrées sous forme de vecteurs plats, les CNN préservent la structure spatiale de l’image, ce qui leur permet de mieux reconnaître les motifs comme des bords, des textures, ou des objets entiers. La convolution est une opération mathématique qui permet de faire glisser un filtre sur l’image d’entrée pour extraire des caractéristiques spécifiques.
Les réseaux neuronaux convolutifs reposent sur les concepts suivants :
-
Convolution : opération mathématique clé dans les CNN qui consiste à appliquer un filtre convolutif sur chaque zone locale de pixels de l’image pour extraire des caractéristiques spécifiques (telles que des bords, des formes...
Les réseaux récurrents (RNN)
Les réseaux de neurones récurrents (RNN - Recurrent Neural Networks) sont une classe de réseaux de neurones particulièrement adaptés à l’analyse de séquences et de données temporelles. Contrairement aux réseaux traditionnels, ils intègrent des boucles dans leur architecture, permettant ainsi de mémoriser des informations provenant de précédentes étapes, ce qui leur confère une capacité à capturer des dépendances dans le temps.
1. Histoire des RNN
Le développement des RNN a commencé dans les années 80 et 90, en particulier grâce aux travaux de John Hopfield et David Rumelhart, et a connu une forte expansion avec les travaux de Jürgen Schmidhuber et Sepp Hochreiter. Les RNN ont été proposés pour résoudre les limites des réseaux neuronaux traditionnels (appelés en opposition feed-forward networks) qui ne peuvent pas gérer les séquences et sont incapables de mémoriser les informations passées.
Les RNN ont permis d’apporter une solution à ces problèmes en introduisant des cycles dans le réseau, ce qui leur permet de mémoriser des informations sur des séquences de données dans un contexte temporel. Ces propriétés les rendent particulièrement utiles pour des tâches telles que la prédiction de séries temporelles, la traduction automatique, la reconnaissance vocale, et le traitement du langage naturel.
2. Principe des RNN
Contrairement aux réseaux neuronaux traditionnels, où les connexions se déplacent uniquement dans une direction, des entrées vers les sorties, les RNN permettent des connexions récurrentes qui créent des cycles de rétroaction dans le réseau. Cela permet aux RNN de conserver un état interne qui capture les informations des étapes précédentes de la séquence de données.
Les RNN acceptent donc en entrée des séquences de vecteurs. L’un des avantages des RNN est leur capacité à traiter des séquences de longueurs variables. C’est-à-dire que le réseau peut recevoir des séquences d’entrée où...
La rétropropagation dans le temps (BPTT)
La Rétropropagation dans le temps (BPTT - Backpropagation Through Time) est une extension de l’algorithme classique de rétropropagation utilisé pour entraîner des réseaux neuronaux feed-forward, mais adaptée aux réseaux neuronaux récurrents (RNN). Non seulement la BPTT propage les erreurs en arrière dans les couches du réseau, mais également dans le passé au travers des états temporels précédents.
1. Histoire de la rétropropagation dans le temps
L’algorithme de rétropropagation, initialement popularisé dans les années 80 par David Rumelhart, Geoffrey Hinton, et Ronald J. Williams, est devenu l’algorithme standard pour entraîner les réseaux de neurones à plusieurs couches en ajustant leurs poids afin de minimiser l’erreur entre les prédictions du réseau et les sorties attendues.
Cependant, pour les réseaux neuronaux récurrents (RNN), qui traitent des données séquentielles et temporelles, une simple rétropropagation ne suffit pas, car les RNN impliquent des connexions cycliques et des dépendances entre des états successifs dans le temps. La BPTT a été développée à la fin des années 80 pour résoudre ce problème, en déroulant les RNN dans le temps et en adaptant l’algorithme de rétropropagation pour tenir compte des dépendances temporelles. Elle s’inscrit directement dans la continuité des avancées de la rétropropagation classique à cette époque.
2. Principe de la rétropropagation dans le temps
L’objectif de la BPTT est d’adapter les poids du réseau récurrent afin de minimiser la fonction de coût sur une séquence complète d’entrées, en prenant en compte les contributions de chaque étape temporelle.
a. Principe fondamental
Le principe de la BPTT repose sur l’idée de dérouler le réseau récurrent dans le temps. Considérons un RNN avec des boucles de rétroaction à chaque pas temporel :
Lors de la rétropropagation dans le temps, on « déroule » le réseau récurrent sur toute la séquence....
Les problèmes de gradients
Les problèmes de gradients qui disparaissent (vanishing gradient) et de gradients qui explosent (exploding gradient) sont des défis majeurs dans l’entraînement des réseaux de neurones profonds, notamment les réseaux récurrents (RNN). Ces phénomènes compliquent l’ajustement optimal des paramètres du modèle et peuvent rendre l’entraînement inefficace.
Rappelons-nous que les gradients représentent les dérivées de la fonction de perte par rapport aux paramètres du modèle, tels que les poids et les biais. Ils indiquent la direction dans laquelle les poids doivent être ajustés pour réduire l’erreur, permettant ainsi au modèle d’apprendre.
Dans le contexte de la rétropropagation, l’algorithme se déplace en arrière depuis la couche de sortie vers la couche d’entrée et ces problèmes peuvent survenir lors de la propagation arrière de l’erreur et du calcul des dérivées de la fonction de perte.
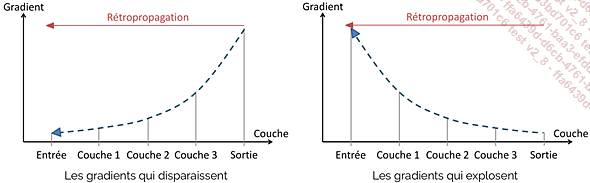
Figure 5-17 - Les problèmes de gradients
1. Les gradients qui disparaissent
Le problème des gradients qui disparaissent se manifeste lorsque les gradients deviennent très petits au fur et à mesure qu’ils sont propagés en arrière à travers le réseau....
Les LSTM
Les réseaux de neurones à mémoire à long et court terme (LSTM - Long Short-Term Memory) sont une architecture spécifique de réseaux de neurones récurrents (RNN), conçue pour traiter et prédire des séries temporelles, des séquences et d’autres types de données où le contexte et l’ordre des éléments sont importants.
Les RNN traditionnels ont été introduits dans les années 80 pour traiter des données séquentielles. Bien qu’efficaces, ils se heurtent au « problème du gradient qui disparaît » lorsqu’ils traitent de longues séquences (entre autres situations), ce qui les rendait incapables d’apprendre des relations à long terme dans les séquences de données.
En 1997, Sepp Hochreiter et Jürgen Schmidhuber ont introduit les LSTM pour résoudre ces limitations des RNN classiques. L’idée principale derrière les LSTM est d’introduire un mécanisme de mémoire explicite qui permet de mieux gérer les dépendances à long terme dans les séquences. Les LSTM ont connu un grand succès immédiat et sont devenus un outil précieux dans le domaine des réseaux de neurones pour le traitement de séquences, offrant une solution aux limitations des RNN traditionnels.
Leur capacité à gérer des dépendances temporelles complexes et à long terme a ouvert la voie à des applications variées et innovantes, allant de la traduction automatique à la prévision de séries temporelles complexes. Ils souffrent d’une certaine complexité, mais les avantages qu’ils apportent font d’eux un choix populaire et souvent préféré pour le traitement de séquences.
Les recherches continues sur les variantes et améliorations des LSTM, comme les GRU (Gated Recurrent Units), témoignent de l’intérêt du domaine et du potentiel qu’offrent ces architectures pour résoudre les défis de l’intelligence artificielle.
1. Principe des LSTM
Les LSTM sont conçus pour se souvenir des informations importantes et ignorer les informations moins pertinentes. Pour ce faire, ils utilisent...
L’avènement du deep learning
Le deep learning (ou « apprentissage profond » en français, mais c’est peu utilisé) est une approche spécifique en apprentissage automatique qui se concentre principalement sur l’utilisation de réseaux de neurones profonds pour apprendre des représentations complexes à partir de données volumineuses.
Dans les approches classiques d’apprentissage automatique, les données doivent être soigneusement préparées et transformées manuellement (ingénierie des caractéristiques, nous en parlons en introduction) en fonction de l’expertise humaine, ce qui peut être un processus coûteux et laborieux.
En revanche, dans le deep learning, les modèles apprennent automatiquement les caractéristiques pertinentes directement à partir des données brutes. La grande quantité de données traitée, et l’utilisation de nombreuses couches, permet d’atteindre des performances surpassant les méthodes classiques, même à partir des attributs bruts.
Le deep learning se distingue aussi par l’utilisation de technologies de Big Data, permettant aux modèles de mieux généraliser (mais le deep learning peut fonctionner sur des ensembles de données plus modestes - toute proportion considérée - avec des techniques comme le pré-entraînement ou l’augmentation de données) et l’utilisation de nombreuses couches, cruciales pour capturer des représentations hiérarchiques (c’est leur rôle dans l’apprentissage des caractéristiques qui rend les couches profondes si puissantes). D’une certaine manière, l’emploi de volumes massifs de données permet de remplacer l’effort humain nécessaire à l’ingénierie des caractéristiques par un effort machine.
Le terme deep learning...
Les transformers
Les transformers ont été introduits par Vaswani et al. en 2017 dans l’article « Attention Is All You Need ». Leur objectif était de proposer un modèle plus efficace que les réseaux récurrents (RNN) et les réseaux de neurones convolutifs (CNN) pour traiter les données séquentielles, en particulier pour les tâches de traduction automatique. Si les LSTM ont été une évolution technologique majeure en termes d’efficacité dans la capture des dépendances à longue distance, les transformers ont été un pas plus important encore, particulièrement concernant les applications de traitement du langage naturel (NLP - Natural Language Processing) grâce à leur capacité à traiter des séquences de texte en parallèle et à capturer des dépendances à très longue distance et beaucoup plus profondément qu’avec les modèles précédents.
Aujourd’hui, les transformers sont la base de nombreux modèles avancés, comme BERT, GPT, T5 et bien d’autres. Ils sont utilisés dans des domaines variés tels que la traduction, la synthèse de texte, la génération d’images et même dans les domaines de la vision par ordinateur.
L’innovation essentielle des transformers est le mécanisme d’attention, en particulier l’attention multitête. Contrairement aux modèles séquentiels traditionnels, il n’a pas besoin de traiter les données de manière ordonnée. Voyons les principales innovations du modèle des transformers :
-
Encodeurs et Décodeurs : le modèle est composé d’un encodeur et d’un décodeur, chacun constitué de plusieurs couches. L’encodeur traite les données d’entrée et génère des représentations qui sont utilisées par le décodeur pour produire la sortie.
-
Attention : le mécanisme d’attention permet au modèle de focaliser son attention sur différentes parties de l’entrée lors de la génération de chaque mot de sortie, capturant ainsi les relations pertinentes.
-
Positionnal Encoding...
Les GPT
Les GPT (Generative Pretrained Transformers) et les transformers partagent une même base architecturale, mais ils diffèrent par leur conception spécifique, leur objectif et leur utilisation. Pour comprendre les GPT, il est essentiel de les situer par rapport à l’architecture plus générale des transformers, dont ils sont une déclinaison spécialisée et optimisée pour la génération de texte.
1. Les transformers : une architecture de base flexible
Les transformers sont composés de blocs empilés d’encodeurs et de décodeurs. Aussi bien les composants des blocs que les blocs eux-mêmes peuvent être assemblés à souhait et constituent une architecture de base incroyablement flexible, capable de s’adapter à une grande variété de tâches en apprentissage machine. Leur mécanisme d’attention permet de traiter efficacement des données séquentielles de longue portée, tandis que leur conception modulaire (encodeur, décodeur, ou combinaison des deux) peut être utilisée aussi bien pour des tâches de classification, traduction ou génération de texte que pour des applications non textuelles comme l’analyse d’images ou la modélisation moléculaire.
Cette polyvalence a rapidement fait des transformers un standard dans le domaine de l’intelligence artificielle moderne....
Les grands modèles de langage (LLM)
Les grands modèles de langage (Large Language Models - LLM) sont des modèles d’apprentissage profond entraînés sur des quantités massives de données textuelles, capables de générer et de comprendre du texte dans un large éventail de contextes. Ils sont construits principalement avec des architectures de transformers, parfois adaptées ou passablement personnalisées, et ont évolué pour devenir des outils puissants dans les domaines du traitement du langage naturel (NLP).
Les LLM ont vu le jour avec des modèles comme GPT-2 (2019) et BERT (2018) qui ont démontré la puissance des transformers dans le domaine du NLP. Leur succès a conduit à des modèles plus grands comme GPT-3 (2020), qui a inauguré une ère de modèles à milliards de paramètres capables de réaliser des tâches variées avec une précision accrue. Plus récemment, des modèles tels que GPT-4 et PaLM de Google ont continué à pousser les limites, intégrant davantage de paramètres et des techniques de pré-entraînement avancées pour renforcer leur polyvalence et leur adaptabilité.
Les GPT, vus dans la section précédente, représentent une famille spécifique de LLM conçus avec une architecture...
Beaucoup d’autres techniques
Les sections précédentes traitent des modèles et algorithmes d’apprentissage machine les plus communs ou les plus utilisés dans l’industrie aujourd’hui, ou simplement les plus pertinents en termes de compréhension des évolutions technologiques. Mais il y en a beaucoup d’autres, voyons ci-dessous les principales techniques que nous n’avons pas couvertes.
1. Analyse en composantes principales (PCA)
L’analyse en composantes principales (PCA - Principal Component Analysis) est une méthode statistique utilisée pour réduire la dimensionnalité des données tout en conservant le maximum d’information possible. Elle consiste à transformer les données d’origine en un nouvel ensemble de variables, appelées composantes principales, qui sont non corrélées et qui capturent la variance maximale des données.
Les composantes principales sont les directions (vecteurs propres) le long desquelles les données varient le plus. La transformation se fait ensuite en projetant chaque point de données sur ces nouvelles directions.
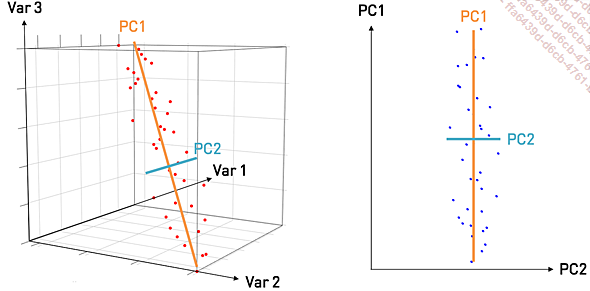
Figure 5-32 - La projection sur dimensions réduites dans la PCA
La PCA a été introduite en 1901 par le statisticien Karl Pearson, initialement pour analyser les corrélations entre variables dans des applications statistiques. Elle a depuis évolué pour devenir un outil de choix en exploration de données, en visualisation (notamment via la réduction des données à deux ou trois dimensions), et en prétraitement pour les algorithmes d’apprentissage machine.
Le processus de la PCA peut être résumé en plusieurs étapes :
-
Centrage des données : on commence par recentrer les données, c’est-à-dire qu’on soustrait la moyenne de chaque variable pour les amener autour de zéro.
-
Calcul des composantes principales : ensuite, on calcule les directions principales de la variance des données en trouvant les vecteurs propres (ou eigenvectors) et valeurs propres (ou eigenvalues) de la matrice de covariance des données.
-
Transformation des données : les données originales sont alors projetées sur les composantes principales (ou axes principaux) qui correspondent aux vecteurs...
Et d’autres approches
Finalement, il convient de présenter sommairement les approches en apprentissage machine que nous n’avons pas évoquées. Ces approches, récentes pour certaines, forment des outils puissants, utilisés pour de nombreuses applications industrielles.
1. L’apprentissage par renforcement (RL)
L’idée de l’apprentissage par renforcement (RL - reinforcement learning) remonte aux premiers travaux en psychologie comportementale et en intelligence artificielle. Ses racines plongent dans la théorie du conditionnement opérant, introduite par le psychologue B.F. Skinner dans les années 30, où des comportements sont appris en recevant des récompenses ou des punitions pour des actions spécifiques.
Dans les années 80, des chercheurs en intelligence artificielle ont commencé à formaliser ces idées en un cadre mathématique et algorithmique. Richard Sutton et Andrew Barto, deux figures emblématiques dans le domaine, ont joué un rôle clé dans le développement de la théorie du RL avec des concepts comme TD Learning (Temporal-Difference Learning) et Q-Learning.
Depuis, le RL est devenu un domaine majeur en intelligence artificielle, notamment grâce aux progrès récents en deep learning qui ont permis d’appliquer le RL à des problèmes complexes tels que les jeux vidéo (par exemple AlphaGo de DeepMind sur les jeux Atari, etc.), la robotique et plus encore.
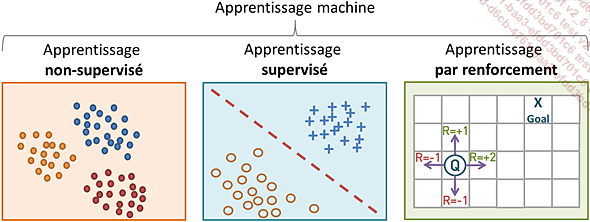
Figure 5-37 - Les types de machine learning
L’apprentissage par renforcement se distingue de l’apprentissage supervisé en ce qu’il n’a pas besoin de paires entrée-sortie étiquetées, ni que les actions sous-optimales soient corrigées explicitement. L’objectif est plutôt de trouver un équilibre entre l’exploration (de territoires inexplorés) et l’exploitation (des connaissances actuelles) afin de maximiser la récompense cumulative, dont le retour peut être incomplet ou retardé.
Le RL est un cadre d’apprentissage où un agent interagit avec un environnement dans le but de maximiser une récompense cumulative. Il est basé sur l’idée de découverte par essais et erreurs (trial and error).
L’agent doit...
Les technologies d’apprentissage machine
Nous avons détaillé dans ce chapitre le fonctionnement d’un bon nombre d’algorithmes et présenté quelques méthodes en apprentissage machine. Un bon niveau de compréhension de leur fonctionnement est absolument essentiel pour être en capacité à les mettre en œuvre efficacement. Mais fort heureusement, il est rarement nécessaire de programmer soi-même un réseau de neurones. Il existe en effet des librairies et framework qui proposent des implémentations open source et à l’état de l’art de la vaste majorité des techniques présentées sous ces lignes.
La plupart de ces frameworks ne s’arrêtent par ailleurs pas à fournir des implémentations d’algorithmes d’apprentissage machine, ils fournissent également en général toutes les commodités imaginables pour la préparation des données, l’ingénierie des caractéristiques, etc.
Voyons les principales librairies utilisées dans l’industrie.
1. TensorFlow
TensorFlow est une bibliothèque open source d’apprentissage machine et de deep learning développée par Google Brain en 2015. Conçu pour simplifier le développement de modèles de deep learning à grande échelle, TensorFlow est particulièrement utilisé pour les réseaux de neurones, mais il prend en charge divers autres algorithmes d’apprentissage machine. Il est principalement écrit en C++ pour des raisons de performance, car le deep learning requiert une gestion intensive des calculs, notamment pour l’entraînement de grands modèles. TensorFlow est conçu pour fonctionner sur des CPU, des GPU et/ou des TPU (Tensor Processing Units), ce qui permet de maximiser les performances en fonction des ressources disponibles.
Du côté de l’application cliente par contre, TensorFlow est principalement utilisé en Python, ce qui est pratique pour la communauté de chercheurs et de développeurs, puisque Python est certainement le langage le plus populaire dans le domaine de la Data Science et de l’intelligence artificielle. La bibliothèque offre une API Python intuitive qui simplifie...
Conclusion
Ces méthodes d’apprentissage machine modernes reposent toutes sur des concepts mathématiques accessibles (presque exclusivement des notions de base en algèbre plutôt simples, des sommes, du calcul matriciel, etc.) et souvent élégants. La beauté de ces techniques réside dans la simplicité des outils mathématiques sous-jacents. Ces bases mathématiques sont souvent étudiées dès les premiers niveaux d’apprentissage des mathématiques ou de l’algèbre linéaire, mais elles deviennent des outils puissants une fois placées dans les mains de concepteurs ingénieux.
Et on touche là la véritable intelligence dans ces méthodes. Elle ne réside pas tant dans les mathématiques ou algorithmes sous-jacents que dans l’ingéniosité des chercheurs et des concepteurs qui ont su transformer ces concepts en techniques innovantes. L’architecture des GAN de Ian Goodfellow, par exemple, ou l’idée d’entraîner des modèles sur des dispositifs décentralisés pour préserver la confidentialité, comme dans l’apprentissage fédéré, sont des idées qui révolutionnent notre manière d’utiliser les données et de construire des modèles.
Ces systèmes ont beau...