
Optimisation des coûts
Introduction
Maîtriser les coûts est un enjeu crucial lors du déploiement de solutions d’IA dans le cloud Azure. Microsoft propose ainsi de nombreux mécanismes pour optimiser la facture tout en maintenant les performances.
Que ce soit via une meilleure sélection des offres tarifaires, l’utilisation de fonctionnalités d’optimisation comme le spillover, la mise en cache de prompts ou encore par une gouvernance proactive des consommations, il est possible de réduire significativement les dépenses liées à l’infrastructure Azure sous-jacente, à Microsoft Foundry et à Copilot Studio.
Choisir les bonnes offres Azure pour réduire la facture
Un projet IA se limite rarement au seul déploiement d’un modèle. D’autres services sont utilisés, pour rendre accessibles l’API, le frontend (App Service, Azure Kubernetes Service…), donner la possibilité d’interroger ses données (compte de stockage, Azure SQL DB, etc.).
Azure propose des options d’achat à la consommation (pay-as-you-go) ou à engagement pour la plupart de ses services cloud.
1. Réservation
Opter pour des engagements de capacité (aussi appelés réservations) permet de bénéficier de fortes remises sur le tarif standard. Par exemple, réserver une machine virtuelle ou un service de base de données SQL sur une durée de 3 ans peut réduire les coûts jusqu’à 72 % par rapport au paiement à l’utilisation.
L’idée est de verrouiller un engagement sur des ressources que vous utiliserez de façon soutenue, en échange d’un tarif horaire préférentiel (sans impact technique sur les ressources concernées).
Azure propose des réservations sur de nombreux produits (machines virtuelles, SQL Azure, stockage, etc.), ainsi que des plans d’économies (Savings Plans) plus flexibles qui offrent des remises contre un engagement financier global sur la durée.
2. Cost Management
Avant de se lancer dans le déploiement de ressources qui soutiendront votre projet IA, il est important d’analyser vos données de consommation (via...
Tarification flexible de Microsoft Foundry
Dans le chapitre Microsoft Foundry - la fabrique d’IA de l’entreprise, deux méthodes d’utilisation d’un modèle ont été introduites, basées sur les tokens et les PTU (Provisioned Throughput Units).
1. PTU
Le mode Provisionné de Foundry permet de réserver des performances via des PTU. À lui seul, il permet souvent de baisser le coût par requête dès que l’utilisation dépasse quelques millions de tokens par jour. Mais on peut aller plus loin en convertissant ce coût en dépense d’investissement (CapEx) via les réservations de PTU.
En effet, plutôt que de payer vos PTU à l’heure au tarif normal, vous pouvez vous engager sur un nombre de PTU sur une durée donnée (1 mois ou 1 an). En échange, Microsoft accorde une remise conséquente - jusqu’à 70 % d’économie sur la capacité réservée. Par exemple, s’engager sur 100 PTU pendant un an reviendra nettement moins cher que payer 100 PTU à l’heure sur 12 mois. Cet engagement se gère via les réservations Azure comme pour d’autres services Azure.
Exemple concret : une application client consomme environ 50 requêtes/sec en continu. En Standard, cela coûterait environ 10 000 € par mois (selon la taille des réponses). En passant en Provisionné avec 50 PTU, la facture tombe peut-être à environ 7 000 €. En ajoutant une réservation d’1 an sur ces 50 PTU, le coût effectif mensuel descend aux alentours de 3 000 € - soit une économie de 70 % par rapport à l’hypothèse de départ non optimisée. Bien sûr, ces chiffres varient selon les modèles utilisés, mais l’ordre de grandeur illustre l’intérêt de convertir une grosse dépense variable en un engagement à tarif réduit.
Attention : qui dit réservation dit risque de sous-utilisation. Il est impératif de surveiller l’utilisation effective de vos PTU réservés pour éviter de payer pour… rien.
PTU, tokens sont les deux principales méthodes de déploiement...
Choix du modèle et optimisation des tokens
Au-delà des mécanismes tarifaires, réduire la consommation passe aussi par des choix techniques avisés : sélectionner le modèle adéquat et optimiser le contenu des requêtes.
Par exemple, un réflexe est d’utiliser un modèle plus petit lorsque c’est possible. En effet, Foundry propose une large gamme de modèles, y compris des modèles open source (ex. : gpt-oss-20b) aux coûts plus faibles. Inutile de mobiliser un GPT-4 grand modèle pour une tâche où un modèle médian (13B ou 20B paramètres) suffit. Microsoft a même introduit un Model Router permettant de déployer un point d’accès unique qui choisit automatiquement le meilleur modèle en fonction de la requête.
1. Limiter la longueur des prompts et réponses
Chaque token compte dans la facture. Formulez des consignes concises, évitez d’injecter systématiquement d’énormes textes si ce n’est pas nécessaire.
De même, utilisez les paramètres de l’API (comme max_tokens pour limiter la réponse) afin d’éviter des réponses inutilement longues. Par exemple, forcer un résumé en 100 mots plutôt qu’une réponse libre de 500 mots divisera mécaniquement les...
Optimiser les coûts dans Copilot Studio
Microsoft Copilot Studio est la plateforme permettant de créer des agents conversationnels personnalisés. Sa tarification diffère de celle de Foundry, mais on y retrouve des leviers d’optimisation de coûts à exploiter.
1. Licensing hybride
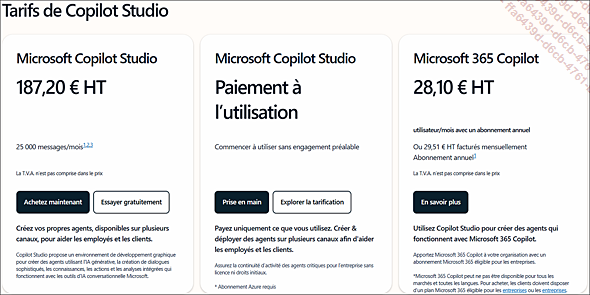
Copilot Studio utilise une facturation par message traité par vos agents. Vous pouvez souscrire des forfaits de messages (message packs) : par exemple 25 000 messages pour 200 $ par mois (soit 0,008 $ par message).
Au-delà, ou si vous n’avez pas de forfait, c’est le modèle pay-as-you-go qui s’applique, à 0,01 $ par message.
Ces coûts couvrent l’usage complet (les appels OpenAI sous-jacents, les connecteurs Power Platform, etc.). Un « message » correspond conceptuellement à une interaction avec l’agent (question posée ou action effectuée) et peut déclencher plusieurs appels LLM en coulisses, mais reste compté comme une unité.
Si vous prévoyez une utilisation intensive et régulière de vos agents, souscrire des packs prépayés revient moins cher par message (0,008 $ contre 0,01 $). Au contraire, pour une utilisation ponctuelle ou incertaine, le paiement à l’usage évite de payer des messages inutilisés.
Les messages non consommés d’un mois ne se reportent pas sur le suivant.
Il est possible de mixer les deux : par exemple, prendre...
Gouvernance
Techniquement, nous avons vu qu’il y avait plusieurs méthodes(spillover, prompt caching, etc.) pour optimiser les coûts de vos projets IA.
Mais le facteur humain reste primordial dans la réduction de la facture finale. Par exemple, répartir les coûts en interne permet de responsabiliser chaque équipe.
Azure Cost Management permet de ventiler les dépenses par étiquette/projet, ce qui aide à refacturer l’utilisation de ressources Azure en interne, comme le montre l’image ci-dessous :
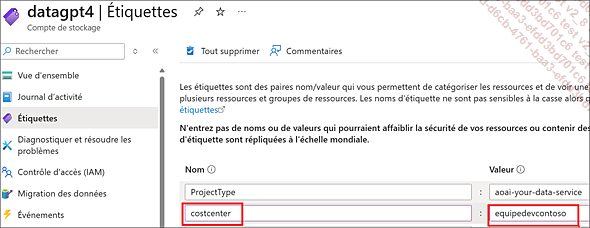
Quand les équipes découvriront le coût de leurs appels d’IA, elles seront incitées à optimiser leurs usages.
Ainsi, réductions de coût et gouvernance vont de pair. Par exemple, décider qu’un environnement de recette utilisera un modèle plus petit pour réduire la dépense (car pas besoin de la pleine qualité de GPT-4) est à la fois une décision technique et budgétaire. Formaliser ce genre de règle (ex. : « dev = usage standard, prod critique = PTU + spillover, volumétries x = batch », etc.) et l’intégrer dans un processus de déploiement aura un impact réel sur votre facture.
En appliquant toutes ces stratégies, les entreprises peuvent profiter de l’IA de Microsoft tout en gardant la maîtrise budgétaire...