
Analyser le procédé
Introduction
Objectifs du chapitre :
-
montrer comment l’analyse statistique permet de répondre à quelques-unes des questions telles que :
-
Quand le carnet de commandes sera-t-il épuisé ?
-
Quand cet élément de travail sera-t-il terminé ?
-
Combien d’éléments de travail peut-on livrer d’ici telle date ?
-
montrer quelques analyses complémentaires telles que :
-
Évolution du TEC, évolution du débit, rendement, blocages et abandons, respect du NSA, influence des dépendances.
-
montrer comment bénéficier des techniques d’apprentissage automatique pour comprendre son procédé.
L’analyse des mesures sur le procédé vise (au moins) deux cibles :
-
l’amélioration du procédé suivi par l’équipe pour développer le produit ;
-
l’amélioration de la prévisibilité des dates de livraison par l’équipe des éléments de travail qui parcourent son procédé de développement.
Le premier point sera abordé au chapitre Démarche d’amélioration avec Kanban.
Quant au second point, la prévisibilité que recherche l’équipe, et celle qu’elle obtient grâce aux analyses statistiques réalisées à partir des données...
Considérations générales sur les prévisions
Une fois que l’équipe commence à travailler sur un élément, il est impossible pour elle de dire avec certitude combien de temps exactement il faudra pour que cet élément se termine. À partir du moment où toute activité comporte une part d’incertitude, une approche probabiliste est justifiée. Ce que nos clients nous demandent vraiment de faire, c’est de prévoir l’avenir. Par conséquent, toute réponse que nous leur donnons équivaut à une prévision.
La qualité de la prévision d’une quantité (ou d’un événement) dépend au moins de :
-
la compréhension des facteurs qui contribuent à sa valeur (ou son existence) ;
-
la quantité de données disponibles ;
-
la similarité entre le passé et le futur ;
-
la capacité de la prévision à influencer ce que l’on cherche à prévoir (prophétie autoréalisatrice).
Prévoir peut se faire dans un environnement changeant dès lors que la façon dont il change est constante. Un environnement volatile qui continue à être volatile de la même façon n’est pas un obstacle à la prévision. La modélisation nécessaire à la prévision doit capturer la façon dont les choses évoluent, et non pas seulement comment les choses sont.
Toute prévision communiquée à un client ou un manageur s’exprime par une étendue (et non un seul nombre), une probabilité (de respecter cette étendue, elle est exprimée en général sous forme de pourcentage) et une durée de validité (jusqu’à quand cette prévision est-elle valable). Plus la durée de validité demandée est grande, plus l’étendue de la valeur de la prévision est grande et la probabilité...
Techniques et outils à utiliser
Hormis la technique dite de Monte Carlo, toutes les techniques statistiques utilisées sont élémentaires. Quant à la technique de Monte Carlo, nous ne l’utiliserons que dans son aspect le plus simple.
Toutes les analyses statistiques présentées dans ce chapitre se basent sur l’historique des métriques temps de cycle et débit. L’équipe aura à cœur d’en avoir des mesures correctes ! Elle réévaluera régulièrement les données historiques nécessaires : le débit de l’équipe il y a trois ans n’a sans doute plus grand-chose à voir avec le débit actuel ; il est inutile, voire dangereux, de se baser sur une telle donnée ancienne.
L’équipe doit donc revoir régulièrement sa base de données de mesures historiques afin de valider que les résultats des analyses statistiques qui sont réalisées à partir d’elles sont consistantes avec l’état actuel de l’initiative. Une fenêtre glissante (« les 100 dernières mesures ») pourra souvent être appropriée. Dans le cas où existe une particularité saisonnière (la liste des demandes de travaux que l’initiative reçoit dépend d’une période de l’année, comme Noël ou les vacances d’été, par exemple), les mesures de l’année passée de cette période pourront plutôt être utilisées.
 |
La difficulté qu’une équipe ou une organisation rencontre pour obtenir un réel enseignement d’une analyse (statistique ou non) ne vient le plus souvent pas d’un manque de données, mais d’une incapacité à remettre en question les hypothèses ou les croyances qui servent à interroger ces données. Pour prendre des décisions efficaces, on ne doit pas commencer par les faits. Il n’y a pas de faits si on n’a pas un critère de pertinence. Une analyse ne peut donner sa pleine mesure qu’accompagnée d’un vrai travail sur ce que l’on tient pour vrai, et plus généralement sur ses modèles mentaux. Ce travail... |
Premières analyses à partir du diagramme des cumuls du flux
La visualisation du DCF donne rapidement une idée de la stabilité du flux de travaux dans le procédé. Les mesures relevées sur un DCF n’ont de sens que si le procédé est stable54, c’est-à-dire que le débit en entrée du procédé est identique au débit en sortie. La forme graphique du DCF donne une très bonne indication de la stabilité du procédé : les courbes représentant l’entrée et la sortie sont parallèles.
1. DCF pathologique
Ici, je détaille quelques exemples de DCF pathologiques où cette condition de stabilité du procédé n’est pas remplie, ce qui doit entraîner des actions de la part de l’équipe pour le stabiliser. Instable, le procédé est imprévisible.
La figure 7.4(a) illustre un cas fréquent où des éléments de travail s’empilent dans une étape (en l’occurrence ici dans la deuxième) : le TEC de cette étape augmente continuellement et une file de travaux en attente se forme. Cela se traduit visuellement par une courbe dont la pente est plus grande que celle de la courbe en dessous. Les éléments arrivent plus vite dans cette étape du procédé qu’ils n’en partent. L’accroissement du TEC dans cette étape se traduit en augmentation du temps de cycle, et in fine, en dépassement du NSA. Instable, le procédé est imprévisible : il devient difficile de prévoir quand un travail sera terminé. Il est probable qu’une attitude « flux poussé » gouverne la façon de faire de ceux qui envoient le travail dans le procédé. Il est aussi possible que...
Quand cet élément de travail sera-t-il terminé (ou livré) ?
L’annonce que l’équipe fait à son (ou ses) client(s) concernant le moment où sera mis à sa disposition un élément de travail demandé repose sur la distribution du temps de cycle des éléments de travail que l’équipe a déjà développés. Le temps de cycle d’un élément de travail étant la différence entre le moment où l’équipe a terminé le travail et le moment où il l’a commencé, il convient d’abord de s’accorder sur ce que sont ces moments. Dans l’exemple que nous proposons d’utiliser tout au long de ce chapitre, le temps de cycle du parcours d’un élément de travail commence lorsqu’il entre dans l’étape Analyse du procédé et se termine lorsqu’il sort de l’étape Test dudit procédé.
De fait, le temps de cycle est la seule métrique dont nous aurons besoin pour donner une prévision sur le moment de fin de travail sur un élément donné. Commençons par visualiser les temps de cycle des éléments de travail passés.
> library(ggplot2)
# id = identificateur de l'élément de travail
# tc = son temps de cycle
# debut = unité de temp à laquelle il est entré dans l'étape Analyse
# fin = unité de temp à laquelle il est sorti de l'étape Test
> head(donnees) # les premières données
id tc debut fin
1 11 53 64
2 10 15 25
3 15 7 22
4 15 55 70
5 13 38 51
6 53 29 82
> summary(donnees)
tc debut fin
Min. : 7.00 Min. : 0.00 Min. : 10.00
1st Qu.: 12.00 1st Qu.: 12.75 1st Qu.: 29.00
Median : 15.00 Median : 31.00 Median...Quand cette bannette sera-t-elle vidée ?
La bannette Carnet de commandes de l’équipe contient 50 éléments de travail. En supposant qu’aucun élément de travail ne soit retiré ou ajouté, combien d’ut seront-elles nécessaires pour vider la bannette ?
La métrique qui va aider l’équipe à répondre à cette question est le débit de son procédé, c’est-à-dire le nombre d’éléments de travail par unité de temps qu’elle livre. Regardons donc l’historique des débits de notre procédé.
# nombre d'éléments livrés par ut (première livraison à l'ut 10)
> t <- table(factor(donnees$fin, levels = 10:91))
# 2 éléments ont terminé à l'ut 10, 1 à l'ut 11, aucun à l'ut 12, etc...
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
2 1 0 1 0 4 1 1 1 2 0 2 1 4 0 2 0 2 0 2 2 2
# 3 éléments ont terminé à l'ut 32, 1 à l'ut 33, 1 à l'ut 34, etc...
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57
3 1 1 1 2 2 0 0 0 0 2 3 0 0 1 2 1 2 0 2 1 2 1 1 1 1
# 2 éléments ont terminé à l'ut 58, aucun à l'ut 59, etc...
58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 ...Que peut-on produire d’ici la date T ?
Un jalon (commercial, etc.), un événement (salon, etc.), ou encore la date de fin de la prochaine itération imposent une échéance fixe. L’équipe cherche à savoir ce qu’il lui est possible de produire d’ici cette date.
La question n’est pas « Combien de temps pour réaliser cette fonctionnalité ? » mais « Que pouvez-vous réaliser d’ici la date T ? » Une échéance est une contrainte (imposée par le métier, la réglementation, ou le cadre méthodologique), ce n’est pas la résultante d’estimations d’effort à faire telle ou telle fonctionnalité (ou corriger telle ou telle quantité d’anomalies).
Une échéance est souvent interprétée comme binaire : soit elle est respectée, soit elle ne l’est pas. Cependant, d’un point de vue de la valeur (potentielle), la date à laquelle un incrément est livré et ouvert au service n’influe pas obligatoirement de manière binaire sur le bénéfice qu’en obtient l’utilisateur. Par exemple, livré avant telle date, un incrément permettrait de générer une valeur potentielle de disons x, et livré après cette date...
L’équipe va-t-elle respecter son niveau de service attendu ?
Par définition, lorsque le niveau de service attendu est de x unité de temps à α %, l’équipe doit s’attendre à ce que 1 - α % des éléments soient livrés après plus de x unités de temps.
Ainsi, dans le procédé qui sert d’exemple, le NSA à 85 % est de 19 ut. Il faut s’attendre à ce que, dans 15 % des cas, le temps de cycle d’un élément de travail dépasse ces 19 ut.
L’analyse suivante se base sur les éléments n’ayant pas respecté le NSA (au nombre de 13 dans les données de ce qui sert d’exemple dans ce livre). Pour chacun, l’équipe détermine l’âge de l’élément en fin de chaque étape. Il s’agira ensuite, face à un nouvel élément de travail, de déterminer si son âge dans chaque étape le prédispose à ne pas respecter le NSA et donc prendre des mesures avant que cela ne devienne le cas.
# 13 éléments sur 100 n'ont pas respecté le NSA
# la colonne hors_accord a été positionnée à vrai pour ces éléments
> données %>% filter(hors_accord)
id debut fin tc age_fin_analyse age_fin_devel age_fin_en_test hors_accord
6 29 82 53 42 48 53 TRUE
9 59 79 20 9 15 20 TRUE
17 3 27 24 12 18 24 TRUE
27 0 23 23 12 18 23 TRUE
32 12 32 20 9 15 20 TRUE
38 32 53 21 14 16 21 TRUE
45 10 57 47 41 44 47 TRUE
53 19 49 30 18 24 30 TRUE
62 29 75 46 42 44 46 TRUE
70 39 66 27 18 23 27 TRUE
78 0 21 21 12 16 21 TRUE
85 62 85 23 11 17 23 TRUE
99 3 23 20 11 16 20 TRUE Code R : Les éléments n’ayant pas respecté le NSA
Lors du PRS, l’équipe regarde l’âge des éléments de travail par étape (figure 8.2) et oriente ses priorités de travail pour maximiser le respect de son niveau de service attendu. Sur ce graphique, la médiane, la moyenne et le niveau de service attendu sont représentés par des droites horizontales. Toutefois, il est clair qu’avoir un âge inférieur à...
Analyses complémentaires
1. Travaux dans l’en-cours
Il peut être intéressant d’examiner l’évolution de la quantité de travaux dans l’en-cours au cours du temps (figure 7.15(a)). De même, un histogramme de ces valeurs (figure 7.15(b)) montre leur nature non gaussienne.
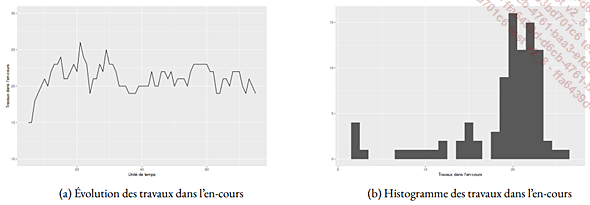
Fig. 7.15 : Travaux en cours par unité de temps
Ces diagrammes illustrent la stabilité (ou l’instabilité) du procédé en montrant la variabilité du TEC.
2. Débit
Il peut être intéressant d’examiner l’évolution du débit au cours du temps (figure 7.16(a)). De même, un histogramme de ces valeurs (figure 7.16(b)) montre leur nature non gaussienne.
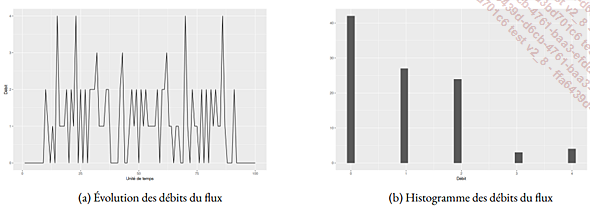
Fig. 7.16 : Débits par unité de temps
Il est naturel de se demander s’il existe un lien entre le débit et les travaux dans l’en-cours. S’agissant de données de comptage, il est indispensable d’utiliser un modèle de régression de type poissonien (les hypothèses des modèles linéaires classiques ne sont plus satisfaites).
> reg[10:20, ]
ut tec deb
10 21 2 # au temps 10, le TEC était de 21 et 2 éléments ont été terminés
11 20 1
12 22 0
13 23 1
14 23 0
15 24 4
16 21 1
17 21 1
18 22 1
19 23 2
20 22 0
> mean(reg$deb)
[1] 1
> var(reg$deb) #
[1] 1.151515
> theoretic_count <- rpois(100, 1)
> tc_df <- data.frame(theoretic_count)
# cf. fig. 7.17
> ggplot(reg, aes(x = deb)) +
geom_bar(fill = "#1E90FF") +
geom_bar(data = tc_df, aes(theoretic_count, fill = "#1E90FF", alpha = 0.1)) +
theme_classic() +
theme(legend.position = "none")
#
> glmreg <- glm(deb ~ tec, reg, family = c("poisson"))
> summary(glmreg)
Call:
glm(formula = deb ~ tec, family = c("poisson"), data = reg)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.32534 0.41576 -3.188...Apprentissage automatique
Il ne s’agit pas dans cette section d’expliquer dans son intégralité ce qu’est l’apprentissage automatique (machine learning), mais d’en utiliser une partie dans le but de montrer comment une équipe qui travaille en mode Kanban peut modéliser son procédé, puis se servir de ce modèle pour analyser son procédé, l’améliorer et l’utiliser pour prévoir des caractéristiques des éléments de travail qui le traversent. Commençons pas définir ce qu’est l’apprentissage automatique.
1. Définition de l’apprentissage automatique
L’apprentissage automatique est une partie de l’analyse statistique dédiée à l’exploration des données. Il en existe deux catégories : la première s’attache à construire un modèle prédictif de ces données en identifiant les facteurs et relations qui permettent de prédire des résultats, la seconde s’attache à construire une classification de ces mêmes données.
|
Apprentissage automatique [3] |
|
L’apprentissage est une modification d’un comportement sur la base d’une expérience. Dans le cas d’un programme informatique, l’apprentissage automatique désigne la capacité d’apprendre de ce programme sans que cette modification ne soit explicitement programmée. Les modèles créés par des algorithmes d’apprentissage automatique peuvent révéler l’importance relative de certaines informations ou la façon dont elles interagissent entre elles pour résoudre un problème particulier. Un programme d’apprentissage automatique utilise les données et les réponses afin de produire la procédure qui permet d’obtenir les secondes à partir des premières. L’apprentissage automatique repose sur deux piliers fondamentaux :
|
Que faire si vous n’avez pas de données historiques ?
Nous avons vu dans ce chapitre que les prévisions que pouvaient faire l’équipe dépendaient de techniques statistiques réalisées sur les données passées des débits et temps de cycle de son procédé. Se pose naturellement la question de savoir que faire lorsqu’on n’a pas ces données ! Ma première remarque est de se rendre compte que l’on a toujours plus de données à sa disposition que ce que l’on croit et qu’on a souvent besoin de moins de données que ce que l’on craint.
Ma seconde remarque concerne la vitesse avec laquelle cette base de données se construit dès le début de l’initiative : si des estimations peuvent être nécessaires au tout début de l’initiative, très rapidement le relevé des débits et temps de cycle réels rend de nouvelles estimations inutiles.
Afin d’illustrer ma première remarque sur le fait qu’on en sait souvent plus que ce que l’on croit, je vais vous présenter « la règle des cinq » [18].
 |
La probabilité que la médiane de la valeur d’un attribut d’une population soit comprise entre la plus grande et la plus petite des valeurs de cet attribut sur un échantillon... |
Améliorer la justesse de ses prévisions
Un procédé présentant une forte variabilité dans le débit est moins prévisible. Pour avoir une chance d’être pertinente, une analyse statistique doit en effet remplir certaines conditions. L’équipe aura tout intérêt à valider ces conditions sur son procédé :
-
un débit stable favorise l’exactitude des prévisions obtenues par la technique de simulation de Monte Carlo ;
-
dès que de nouvelles données sont obtenues, les simulations de Monte Carlo doivent être refaites ;
-
évaluer différentes techniques de sélection des données en entrée : chaîne de Markov, séries temporelles62… ;
-
n’oubliez pas les hypothèses sous-jacentes à la modélisation de votre procédé : les débits des périodes estivales et de Noël ne sont peut-être pas des données historiques fiables pour simuler le débit des mois de mars ou septembre ;
-
n’utilisez pas la moyenne arithmétique ;
-
n’utilisez pas la « loi » de Little, car il s’agit d’une relation entre moyennes63 ;
-
il est inutile de procéder à des estimations ;
-
il est contre-productif de tenter d’ajuster la courbe de vos données...